| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
TensorBoard Gömme Projektör kullanarak, grafiksel yüksek boyutlu katıştırmalarını temsil edebilir. Bu, gömme katmanlarınızı görselleştirmede, incelemede ve anlamada yardımcı olabilir.

Bu öğreticide, bu tür eğitimli katmanı nasıl görselleştireceğinizi öğreneceksiniz.
Kurmak
Bu eğitimde, film inceleme verilerini sınıflandırmak için oluşturulan bir gömme katmanını görselleştirmek için TensorBoard'u kullanacağız.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB Verileri
Her biri bir duyarlılık etiketine (olumlu/negatif) sahip 25.000 IMDB film incelemesinden oluşan bir veri seti kullanacağız. Her inceleme önceden işlenir ve bir dizi kelime indeksi (tamsayı) olarak kodlanır. Basit olması için, kelimeler veri kümesindeki genel sıklığa göre indekslenir, örneğin "3" tamsayısı, tüm incelemelerde görünen en sık 3. kelimeyi kodlar. Bu, "yalnızca en yaygın 10.000 kelimeyi göz önünde bulundurun, ancak en yaygın 20 kelimeyi ortadan kaldırın" gibi hızlı filtreleme işlemlerine izin verir.
Bir kural olarak, "0" belirli bir kelimeyi temsil etmez, bunun yerine bilinmeyen herhangi bir kelimeyi kodlamak için kullanılır. Eğitimin ilerleyen bölümlerinde, görselleştirmedeki "0" satırını kaldıracağız.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras Gömme Katmanı
Bir Keras Gömme Katman dağarcığınızdan her kelime için bir gömme eğitmek için kullanılabilir. Her kelime (veya bu durumda alt kelime), model tarafından eğitilecek olan 16 boyutlu bir vektör (veya gömme) ile ilişkilendirilecektir.
Bkz bu öğretici kelime tespitlerinin hakkında daha fazla bilgi için.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
TensorBoard için Veri Kaydetme
TensorBoard, tensorflow projelerinizin günlüklerinden tensörleri ve meta verileri okur. Günlük dizini yolu ile belirtilen log_dir altında. Bu eğitim için kullandığımız olacak /logs/imdb-example/ .
Verileri Tensorboard'a yüklemek için, modelde belirli bir ilgi katmanının görselleştirilmesine izin veren meta verilerle birlikte bu dizine bir eğitim kontrol noktası kaydetmemiz gerekir.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
analiz
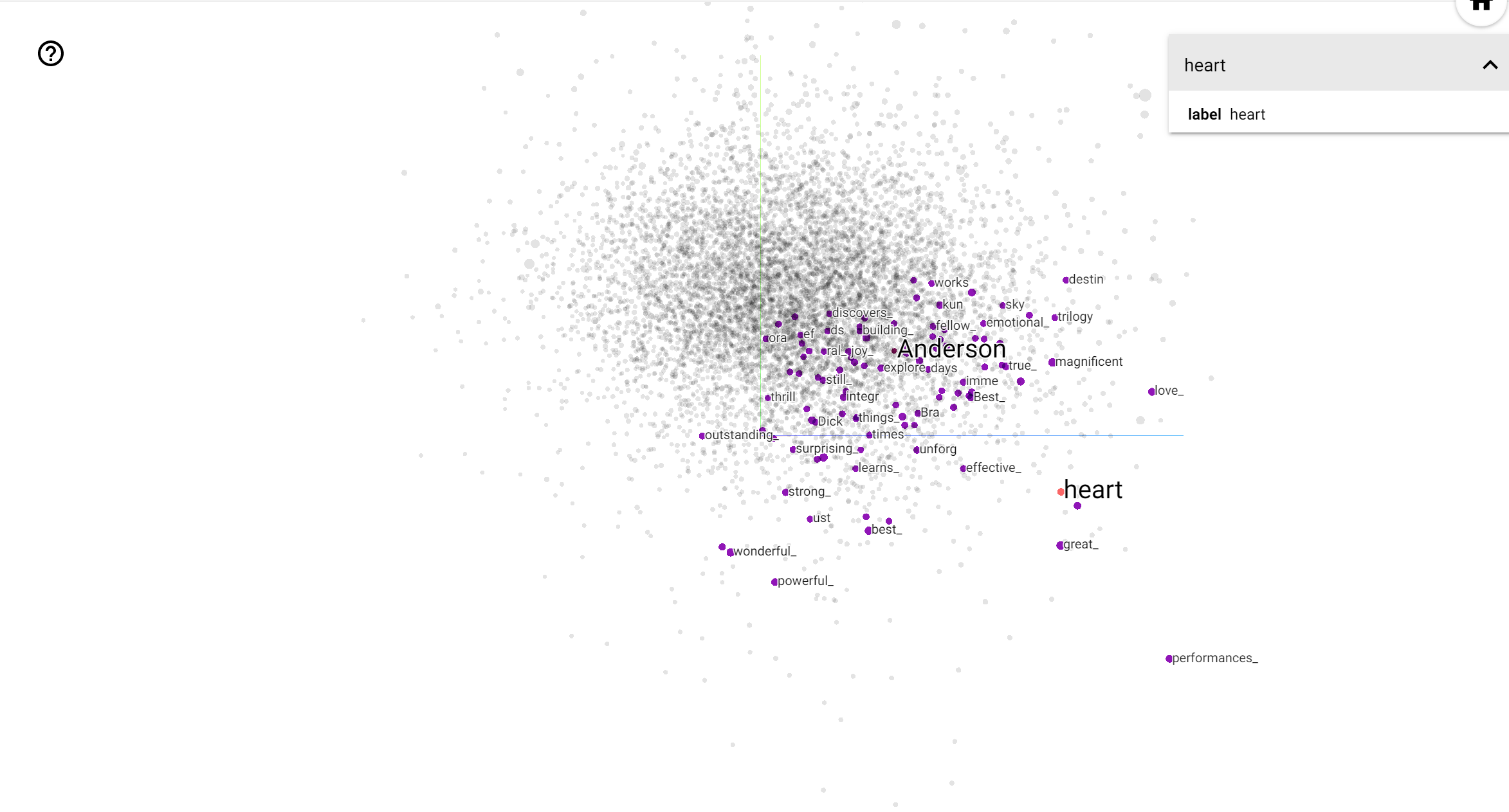
TensorBoard Projektör, yerleştirmeyi yorumlamak ve görselleştirmek için harika bir araçtır. Pano, kullanıcıların belirli terimleri aramasına olanak tanır ve gömme (düşük boyutlu) alanda birbirine bitişik kelimeleri vurgular. Bu örnekten biz Wes Anderson ve Alfred Hitchcock hem oldukça nötr terimler olduğunu, ancak farklı bağlamlarda başvurulan olduğunu görebilirsiniz.
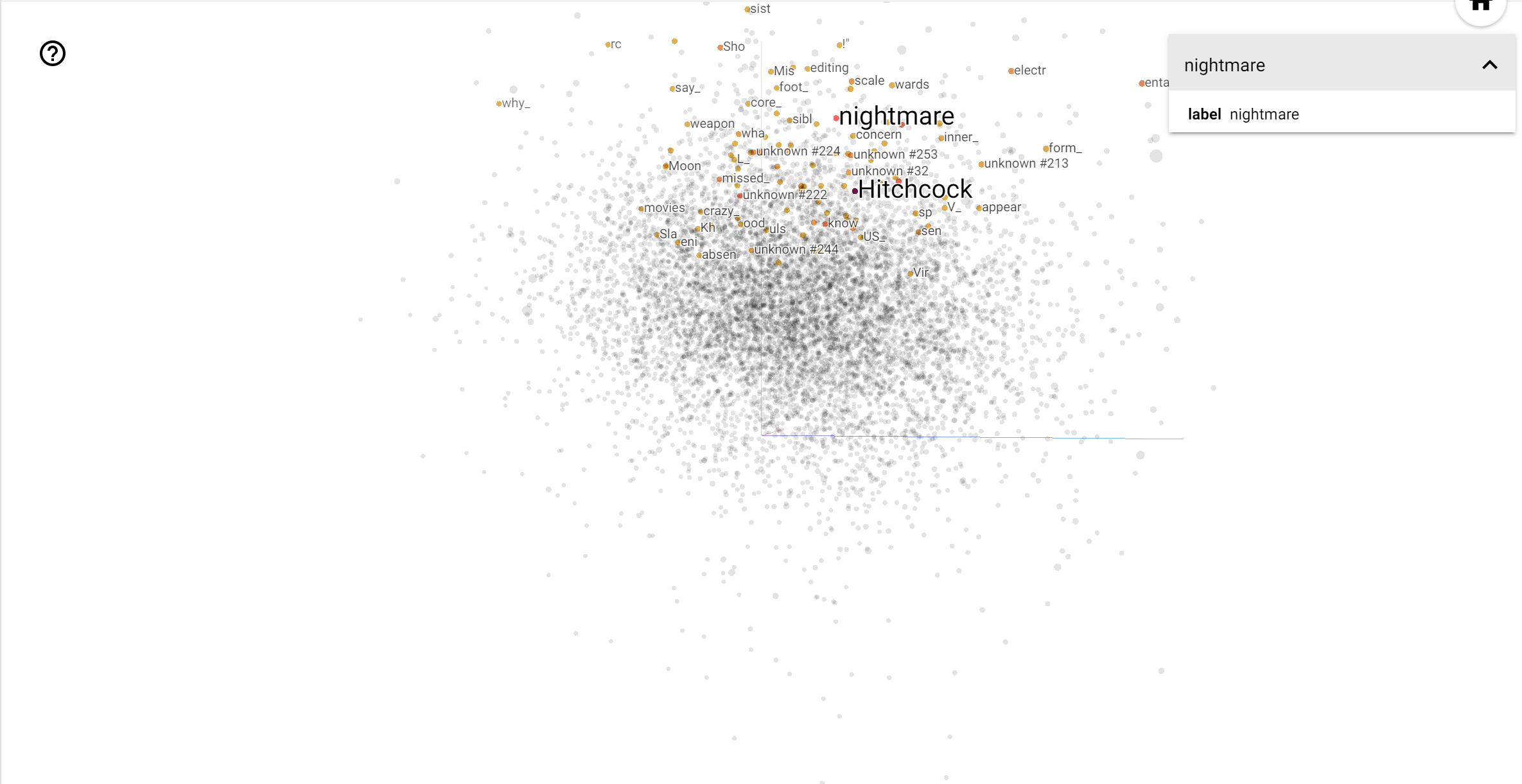
Bu alanda, Hitchcock daha yakın gibi kelimeler etmektir nightmare Anderson yakın kelime için ise nedeniyle o "gerilim ustası" olarak bilinen gerçeğine muhtemeldir, heart onun acımasız detaylı ve iç açıcı tarzı ile tutarlıdır, .