
| | |  गिटहब पर देखें गिटहब पर देखें | | |
इस ट्यूटोरियल में सादा-पाठ IMDB मूवी समीक्षाओं के डेटासेट पर भावना विश्लेषण करने के लिए BERT को फ़ाइन-ट्यून करने के लिए पूरा कोड है। एक मॉडल को प्रशिक्षित करने के अलावा, आप सीखेंगे कि टेक्स्ट को एक उपयुक्त प्रारूप में कैसे प्रीप्रोसेस किया जाए।
इस नोटबुक में, आप:
- IMDB डेटासेट लोड करें
- TensorFlow हब से एक BERT मॉडल लोड करें
- BERT को क्लासिफायरियर के साथ जोड़कर अपना खुद का मॉडल बनाएं
- अपने खुद के मॉडल को प्रशिक्षित करें, उसके हिस्से के रूप में BERT को फाइन-ट्यूनिंग करें
- अपना मॉडल सहेजें और वाक्यों को वर्गीकृत करने के लिए इसका इस्तेमाल करें
यदि आप IMDB डाटासेट के साथ काम करने के लिए नए हैं, कृपया देखें मूल पाठ वर्गीकरण अधिक जानकारी के लिए।
BERT . के बारे में
बर्ट और अन्य ट्रांसफार्मर एनकोडर आर्किटेक्चर NLP में कार्यों की एक किस्म (प्राकृतिक भाषा संसाधन) पर बेतहाशा सफल रहे हैं। वे प्राकृतिक भाषा के वेक्टर-स्पेस अभ्यावेदन की गणना करते हैं जो गहन शिक्षण मॉडल में उपयोग के लिए उपयुक्त हैं। मॉडल का बीईआरटी परिवार पहले और बाद में सभी टोकन के पूर्ण संदर्भ में इनपुट टेक्स्ट के प्रत्येक टोकन को संसाधित करने के लिए ट्रांसफार्मर एन्कोडर आर्किटेक्चर का उपयोग करता है, इसलिए नाम: ट्रांसफॉर्मर से द्विदिश एनकोडर प्रतिनिधित्व।
BERT मॉडल आमतौर पर पाठ के एक बड़े संग्रह पर पूर्व-प्रशिक्षित होते हैं, फिर विशिष्ट कार्यों के लिए इसे ठीक किया जाता है।
सेट अप
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
आप से AdamW अनुकूलक का उपयोग करेगा tensorflow / मॉडल ।
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
भावनाओं का विश्लेषण
इस नोटबुक सकारात्मक या नकारात्मक रूप में वर्गीकृत फिल्म समीक्षा, समीक्षा के पाठ पर आधारित करने के लिए एक भावना विश्लेषण मॉडल प्रशिक्षण देता है।
आप इस्तेमाल करेंगे बड़े फिल्म समीक्षा डेटासेट कि से 50,000 फिल्म समीक्षा की पाठ होता है इंटरनेट मूवी डाटाबेस ।
IMDB डेटासेट डाउनलोड करें
आइए डेटासेट डाउनलोड करें और निकालें, फिर निर्देशिका संरचना का अन्वेषण करें।
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
इसके बाद, आप का उपयोग करेगा text_dataset_from_directory एक लेबल बनाने के लिए उपयोगिता tf.data.Dataset ।
IMDB डेटासेट को पहले ही ट्रेन और परीक्षण में विभाजित किया जा चुका है, लेकिन इसमें सत्यापन सेट का अभाव है। के का उपयोग करके प्रशिक्षण डेटा की एक 80:20 विभाजन का उपयोग कर एक सत्यापन सेट बनाएँ validation_split नीचे तर्क।
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
आइए कुछ समीक्षाओं पर एक नज़र डालें।
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
TensorFlow हब से मॉडल लोड हो रहा है
यहां आप चुन सकते हैं कि आप TensorFlow हब और फ़ाइन-ट्यून से कौन सा BERT मॉडल लोड करेंगे। कई BERT मॉडल उपलब्ध हैं।
- बर्ट-बेस , Uncased और सात अधिक मॉडल मूल बर्ट लेखकों द्वारा जारी किया गया प्रशिक्षित वजन के साथ।
- छोटे BERTs ही सामान्य वास्तुकला लेकिन कम और / या छोटे ट्रांसफार्मर ब्लॉक, आप गति, आकार और गुणवत्ता के बीच तालमेल का पता लगाने की सुविधा देता है जो की है।
- अल्बर्ट : कि परतों के बीच मानकों को साझा करके मॉडल आकार (लेकिन गणना समय) कम कर देता है "एक लाइट बर्ट" के चार अलग अलग आकार।
- बर्ट विशेषज्ञों : आठ मॉडल सभी कि बर्ट आधार वास्तुकला है, लेकिन अलग-पूर्व प्रशिक्षण डोमेन के बीच एक विकल्प प्रदान करते हैं, लक्ष्य कार्य के साथ और अधिक बारीकी से संरेखित करने के लिए।
- इलेक्ट्रा बर्ट रूप में एक ही वास्तुकला (तीन अलग अलग आकार में) है, लेकिन एक सेट अप में एक discriminator अनुसार पहले से प्रशिक्षित हो जाता है कि जैसा दिखता है एक उत्पादक विरोधात्मक Network (GAN)।
- बात-प्रमुखों ध्यान दें और सुरक्षा पूर्ण GELU [साथ बर्ट आधार , बड़े ] ट्रांसफार्मर वास्तुकला के मूल करने के लिए दोनों के सुधार है।
TensorFlow हब पर मॉडल प्रलेखन में शोध साहित्य के अधिक विवरण और संदर्भ हैं। ऊपर दिए गए लिंक का पालन करें, या पर क्लिक करें tfhub.dev यूआरएल अगले सेल निष्पादन के बाद छपी।
सुझाव है कि एक छोटे बीईआरटी (कम मापदंडों के साथ) के साथ शुरू किया जाए क्योंकि वे तेजी से फाइन-ट्यून करने के लिए हैं। यदि आप एक छोटा मॉडल पसंद करते हैं लेकिन उच्च सटीकता के साथ, ALBERT आपका अगला विकल्प हो सकता है। यदि आप और भी बेहतर सटीकता चाहते हैं, तो क्लासिक BERT आकारों में से एक या उनके हाल के परिशोधन जैसे इलेक्ट्रा, टॉकिंग हेड्स, या एक BERT विशेषज्ञ चुनें।
एक तरफ मॉडल नीचे उपलब्ध से, देखते हैं एक से अधिक संस्करण मॉडल है कि बड़े होते हैं और यहां तक कि बेहतर सटीकता प्राप्त हो सकते हैं, लेकिन वे भी सुधारी एक एकल GPU पर होने के लिए बड़े हैं। आप ऐसा करने पर सक्षम हो जाएगा का समाधान GLUE एक TPU colab पर बर्ट का उपयोग कर कार्यों ।
आप नीचे दिए गए कोड में देखेंगे कि tfhub.dev URL को स्विच करना इनमें से किसी भी मॉडल को आज़माने के लिए पर्याप्त है, क्योंकि उनके बीच के सभी अंतर TF हब से सहेजे गए मॉडल में समाहित हैं।
फ़ाइन-ट्यून करने के लिए एक BERT मॉडल चुनें
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
प्रीप्रोसेसिंग मॉडल
टेक्स्ट इनपुट को संख्यात्मक टोकन आईडी में बदलने और BERT में इनपुट करने से पहले कई टेंसर में व्यवस्थित करने की आवश्यकता होती है। TensorFlow हब ऊपर चर्चा किए गए प्रत्येक BERT मॉडल के लिए एक मिलान प्रीप्रोसेसिंग मॉडल प्रदान करता है, जो TF.text लाइब्रेरी से TF ऑप्स का उपयोग करके इस परिवर्तन को लागू करता है। टेक्स्ट को प्रीप्रोसेस करने के लिए अपने TensorFlow मॉडल के बाहर शुद्ध पायथन कोड चलाना आवश्यक नहीं है।
प्रीप्रोसेसिंग मॉडल BERT मॉडल के दस्तावेज़ीकरण द्वारा संदर्भित होना चाहिए, जिसे आप ऊपर मुद्रित URL पर पढ़ सकते हैं। ऊपर दिए गए ड्रॉप-डाउन से BERT मॉडल के लिए, प्रीप्रोसेसिंग मॉडल स्वचालित रूप से चुना जाता है।
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
आइए कुछ पाठ पर प्रीप्रोसेसिंग मॉडल का प्रयास करें और आउटपुट देखें:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
आप देख सकते हैं, अब आप पूर्व प्रसंस्करण कि एक बर्ट मॉडल (का प्रयोग करेंगे से 3 आउटपुट है input_words_id , input_mask और input_type_ids )।
कुछ अन्य महत्वपूर्ण बिंदु:
- इनपुट को 128 टोकन तक छोटा कर दिया गया है। टोकन की संख्या अनुकूलित किया जा सकता है, और आप के बारे में अधिक विवरण देख सकते हैं एक TPU colab पर बर्ट का उपयोग कर हल GLUE कार्यों ।
-
input_type_idsकेवल एक मान (0) है क्योंकि यह एक एक वाक्य इनपुट है। एकाधिक वाक्य इनपुट के लिए, इसमें प्रत्येक इनपुट के लिए एक नंबर होगा।
चूंकि यह टेक्स्ट प्रीप्रोसेसर एक TensorFlow मॉडल है, इसे सीधे आपके मॉडल में शामिल किया जा सकता है।
BERT मॉडल का उपयोग करना
BERT को अपने मॉडल में डालने से पहले, आइए इसके आउटपुट पर एक नज़र डालें। आप इसे TF हब से लोड करेंगे और लौटाए गए मान देखेंगे।
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
बर्ट मॉडल 3 महत्वपूर्ण कुंजी के साथ एक नक्शे को वापस: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputएक पूरे के रूप में प्रत्येक इनपुट अनुक्रम का प्रतिनिधित्व करता है। आकार है[batch_size, H]। आप इसे पूरी मूवी समीक्षा के लिए एक एम्बेडिंग के रूप में सोच सकते हैं। -
sequence_outputप्रत्येक इनपुट संदर्भ में टोकन का प्रतिनिधित्व करता है। आकार है[batch_size, seq_length, H]। आप इसे मूवी समीक्षा में प्रत्येक टोकन के लिए एक प्रासंगिक एम्बेडिंग के रूप में सोच सकते हैं। -
encoder_outputsके मध्यवर्ती एक्टीवेशन हैंLट्रांसफार्मर ब्लॉक।outputs["encoder_outputs"][i]आकार का एक टेन्सर है[batch_size, seq_length, 1024]i-वें ट्रांसफार्मर ब्लॉक के आउटपुट के साथ, के लिए0 <= i < L। सूची के अंतिम मूल्य के बराबर हैsequence_output।
ठीक करने के लिए आप का उपयोग करने के लिए जा रहे हैं pooled_output सरणी।
अपने मॉडल को परिभाषित करें
आप प्रीप्रोसेसिंग मॉडल, चयनित BERT मॉडल, एक सघन और एक ड्रॉपआउट परत के साथ एक बहुत ही सरल फ़ाइन-ट्यून मॉडल बनाएंगे।
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
आइए जांचें कि मॉडल प्रीप्रोसेसिंग मॉडल के आउटपुट के साथ चलता है।
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
बेशक, आउटपुट अर्थहीन है, क्योंकि मॉडल को अभी तक प्रशिक्षित नहीं किया गया है।
आइए मॉडल की संरचना पर एक नज़र डालें।
tf.keras.utils.plot_model(classifier_model)
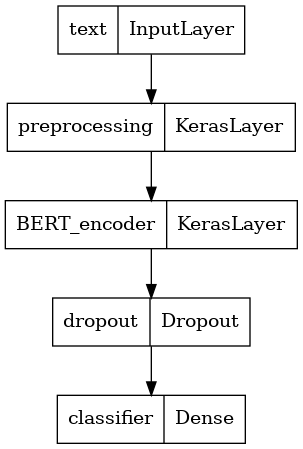
मॉडल प्रशिक्षण
अब आपके पास एक मॉडल को प्रशिक्षित करने के लिए सभी टुकड़े हैं, जिसमें प्रीप्रोसेसिंग मॉड्यूल, बीईआरटी एनकोडर, डेटा और क्लासिफायर शामिल हैं।
लॉस फंकशन
चूंकि यह एक द्विआधारी वर्गीकरण समस्या है और इस मॉडल में संभावना (एक एकल इकाई परत) आउटपुट, आप इस्तेमाल करेंगे losses.BinaryCrossentropy नुकसान कार्य करते हैं।
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
अनुकूलक
फ़ाइन-ट्यूनिंग के लिए, आइए उसी अनुकूलक का उपयोग करें जिससे BERT को मूल रूप से प्रशिक्षित किया गया था: "एडेप्टिव मोमेंट्स" (एडम)। इस अनुकूलक भविष्यवाणी नुकसान को कम करता है और वजन क्षय (क्षणों का उपयोग नहीं) है, जो के रूप में भी जाना जाता है के द्वारा नियमितीकरण करता AdamW ।
सीखने की दर (के लिए init_lr ), तो आप एक ही समय का उपयोग बर्ट पूर्व प्रशिक्षण देगा: एक काल्पनिक सीखने की शुरुआती दर के रैखिक क्षय, अधिक प्रशिक्षण कदम (के पहले 10% एक रेखीय वार्म अप चरण की शुरुआत में लगाए num_warmup_steps )। BERT पेपर के अनुरूप, फाइन-ट्यूनिंग के लिए प्रारंभिक सीखने की दर छोटी होती है (सर्वश्रेष्ठ 5e-5, 3e-5, 2e-5)।
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
BERT मॉडल और प्रशिक्षण लोड हो रहा है
का उपयोग करते हुए classifier_model आपको पहले बनाए गए हैं, तो आप नुकसान, मीट्रिक और अनुकूलक के साथ मॉडल संकलन कर सकते हैं।
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
मॉडल का मूल्यांकन करें
आइए देखें कि मॉडल कैसा प्रदर्शन करता है। दो मान लौटाए जाएंगे। हानि (एक संख्या जो त्रुटि का प्रतिनिधित्व करती है, कम मान बेहतर होते हैं), और सटीकता।
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
समय के साथ सटीकता और हानि को प्लॉट करें
के आधार पर History वस्तु द्वारा दिया model.fit() आप तुलना के लिए प्रशिक्षण और सत्यापन हानि, साथ ही प्रशिक्षण और सत्यापन सटीकता की साजिश कर सकते हैं:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
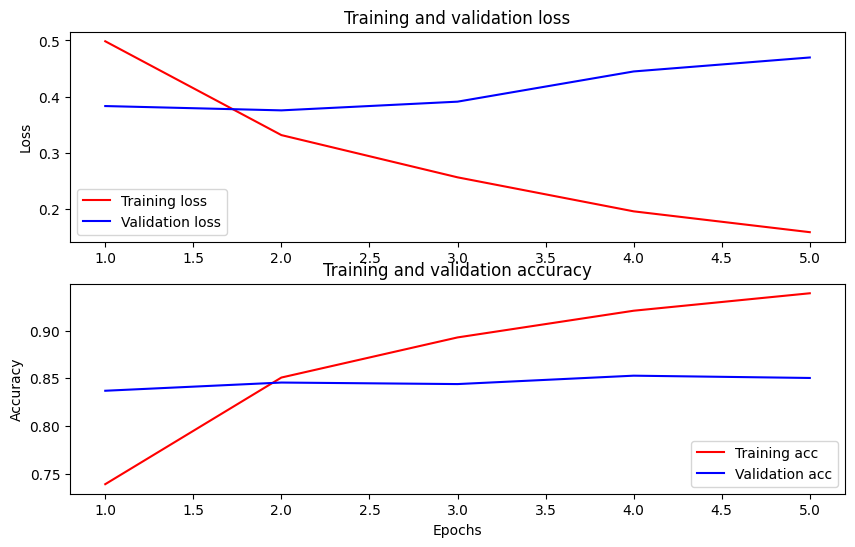
इस भूखंड में, लाल रेखाएँ प्रशिक्षण हानि और सटीकता का प्रतिनिधित्व करती हैं, और नीली रेखाएँ सत्यापन हानि और सटीकता का प्रतिनिधित्व करती हैं।
अनुमान के लिए निर्यात करें
अब आप अपने फाइन-ट्यून किए गए मॉडल को बाद में उपयोग के लिए सहेज लें।
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
आइए मॉडल को फिर से लोड करें, ताकि आप उस मॉडल के साथ कंधे से कंधा मिलाकर कोशिश कर सकें जो अभी भी स्मृति में है।
reloaded_model = tf.saved_model.load(saved_model_path)
यहां आप अपनी पसंद के किसी भी वाक्य पर अपने मॉडल का परीक्षण कर सकते हैं, बस नीचे दिए गए उदाहरण चर में जोड़ें।
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
आप अपने मॉडल का उपयोग करना चाहते हैं TF प्रस्तुति , याद है कि वह अपने नाम पर रखा गया हस्ताक्षर से एक के माध्यम से अपने SavedModel कॉल करेंगे। पायथन में, आप उनका परीक्षण इस प्रकार कर सकते हैं:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
अगले कदम
अगले कदम के रूप में, आप कोशिश कर सकते हैं एक TPU ट्यूटोरियल पर बर्ट का उपयोग कर GLUE कार्यों का समाधान है, जो एक TPU और आप कैसे कई जानकारी के साथ काम करने के लिए शो पर चलता है।