
El componente EjemploGen TFX Pipeline ingiere datos en canalizaciones TFX. Consume archivos/servicios externos para generar ejemplos que serán leídos por otros componentes TFX. También proporciona una partición consistente y configurable, y mezcla el conjunto de datos para las mejores prácticas de ML.
- Consume: datos de fuentes de datos externas como CSV,
TFRecord, Avro, Parquet y BigQuery. - Emite: registros
tf.Example, registrostf.SequenceExampleo formato proto, según el formato de carga útil.
EjemploGen y otros componentes
EjemploGen proporciona datos a componentes que utilizan la biblioteca de validación de datos de TensorFlow , como SchemaGen , StatisticsGen y Ejemplo Validador . También proporciona datos a Transform , que utiliza la biblioteca TensorFlow Transform y, en última instancia, a los objetivos de implementación durante la inferencia.
Fuentes de datos y formatos
Actualmente, una instalación estándar de TFX incluye componentes completos de ExampleGen para estos formatos y fuentes de datos:
También hay disponibles ejecutores personalizados que permiten el desarrollo de componentes de EjemploGen para estas fuentes y formatos de datos:
Consulte los ejemplos de uso en el código fuente y esta discusión para obtener más información sobre cómo usar y desarrollar ejecutores personalizados.
Además, estas fuentes y formatos de datos están disponibles como ejemplos de componentes personalizados :
Ingesta de formatos de datos compatibles con Apache Beam
Apache Beam admite la ingesta de datos de una amplia gama de fuentes y formatos de datos ( ver más abajo ). Estas capacidades se pueden utilizar para crear componentes de EjemploGen personalizados para TFX, lo cual se demuestra con algunos componentes de EjemploGen existentes ( ver más abajo ).
Cómo utilizar un componente de EjemploGen
Para las fuentes de datos admitidas (actualmente, archivos CSV, archivos TFRecord con tf.Example , tf.SequenceExample y formato proto, y resultados de consultas de BigQuery), el componente de canalización de EjemploGen se puede usar directamente en la implementación y requiere poca personalización. Por ejemplo:
example_gen = CsvExampleGen(input_base='data_root')
o como a continuación para importar TFRecord externo con tf.Example directamente:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
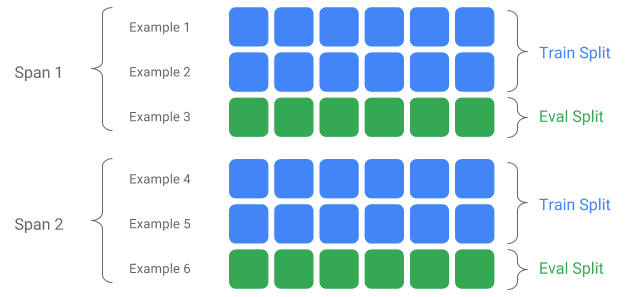
Span, versión y división
Un Span es una agrupación de ejemplos de entrenamiento. Si sus datos persisten en un sistema de archivos, cada Span puede almacenarse en un directorio separado. La semántica de un Span no está codificada en TFX; un lapso puede corresponder a un día de datos, una hora de datos o cualquier otra agrupación que sea significativa para su tarea.
Cada tramo puede contener múltiples versiones de datos. Para dar un ejemplo, si elimina algunos ejemplos de un intervalo para limpiar datos de mala calidad, esto podría resultar en una nueva versión de ese intervalo. De forma predeterminada, los componentes TFX funcionan con la última versión dentro de un intervalo.
Cada versión dentro de un lapso se puede subdividir en múltiples divisiones. El caso de uso más común para dividir un Span es dividirlo en datos de entrenamiento y evaluación.
División de entrada/salida personalizada
Para personalizar la proporción de división de entrenamiento/evaluación que generará EjemploGen, configure output_config para el componente EjemploGen. Por ejemplo:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Observe cómo se configuraron hash_buckets en este ejemplo.
Para una fuente de entrada que ya se ha dividido, configure input_config para el componente EjemploGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Para el gen de ejemplo basado en archivos (por ejemplo, CsvExampleGen e ImportExampleGen), pattern es un patrón de archivo relativo global que se asigna a archivos de entrada con el directorio raíz proporcionado por la ruta base de entrada. Para ejemplos de generación basados en consultas (por ejemplo, BigQueryExampleGen, PrestoExampleGen), pattern es una consulta SQL.
De forma predeterminada, todo el directorio base de entrada se trata como una única división de entrada, y la división de salida de tren y evaluación se genera con una proporción de 2:1.
Consulte proto/example_gen.proto para conocer la configuración dividida de entrada y salida de EjemploGen. Y consulte la guía de componentes posteriores para utilizar las divisiones personalizadas posteriores.
Método de división
Cuando se utiliza el método de división hash_buckets , en lugar del registro completo, se puede utilizar una función para particionar los ejemplos. Si una función está presente, EjemploGen utilizará una huella digital de esa función como clave de partición.
Esta característica se puede utilizar para mantener una división estable con ciertas propiedades de los ejemplos: por ejemplo, un usuario siempre se colocará en la misma división si se seleccionó "user_id" como nombre de la función de partición.
La interpretación de lo que significa una "característica" y cómo hacer coincidir una "característica" con el nombre especificado depende de la implementación de EjemploGen y del tipo de ejemplos.
Para implementaciones de EjemploGen listas para usar:
- Si genera tf.Example, entonces una "característica" significa una entrada en tf.Example.features.feature.
- Si genera tf.SequenceExample, entonces una "característica" significa una entrada en tf.SequenceExample.context.feature.
- Solo se admiten funciones int64 y bytes.
En los siguientes casos, EjemploGen arroja errores de tiempo de ejecución:
- El nombre de la característica especificada no existe en el ejemplo.
- Función vacía:
tf.train.Feature(). - Tipos de funciones no admitidas, por ejemplo, funciones flotantes.
Para generar la división de tren/evaluación en función de una característica de los ejemplos, configure output_config para el componente EjemploGen. Por ejemplo:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Observe cómo se configuró el partition_feature_name en este ejemplo.
Durar
El intervalo se puede recuperar utilizando la especificación '{SPAN}' en el patrón global de entrada :
- Esta especificación coincide con dígitos y asigna los datos a los números SPAN relevantes. Por ejemplo, 'data_{SPAN}-*.tfrecord' recopilará archivos como 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- Opcionalmente, esta especificación se puede especificar con el ancho de los números enteros cuando se asigna. Por ejemplo, 'data_{SPAN:2}.file' se asigna a archivos como 'data_02.file' y 'data_27.file' (como entradas para Span-2 y Span-27 respectivamente), pero no se asigna a 'data_1. archivo' ni 'data_123.file'.
- Cuando falta la especificación SPAN, se supone que siempre es Span '0'.
- Si se especifica SPAN, la canalización procesará el último intervalo y almacenará el número del intervalo en metadatos.
Por ejemplo, supongamos que hay datos de entrada:
- '/tmp/span-1/tren/datos'
- '/tmp/span-1/eval/datos'
- '/tmp/span-2/tren/datos'
- '/tmp/span-2/eval/datos'
y la configuración de entrada se muestra a continuación:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
al activar la canalización, procesará:
- '/tmp/span-2/train/data' como división de tren
- '/tmp/span-2/eval/data' como división de evaluación
con número de intervalo como '2'. Si más adelante '/tmp/span-3/...' está listo, simplemente active la canalización nuevamente y recogerá el intervalo '3' para su procesamiento. A continuación se muestra el ejemplo de código para usar la especificación de intervalo:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Se puede recuperar un intervalo determinado con RangeConfig, que se detalla a continuación.
Fecha
Si su fuente de datos está organizada en el sistema de archivos por fecha, TFX admite la asignación de fechas directamente para abarcar números. Hay tres especificaciones para representar el mapeo de fechas a intervalos: {AAAA}, {MM} y {DD}:
- Las tres especificaciones deben estar presentes en el patrón global de entrada , si se especifica alguna:
- Se puede especificar exclusivamente la especificación {SPAN} o este conjunto de especificaciones de fecha.
- Se calcula una fecha del calendario con el año desde AAAA, el mes desde MM y el día del mes desde DD, luego el número de intervalo se calcula como el número de días desde la época Unix (es decir, 1970-01-01). Por ejemplo, 'log-{AAAA}{MM}{DD}.data' coincide con un archivo 'log-19700101.data' y lo consume como entrada para Span-0, y 'log-20170101.data' como entrada para Span-17167.
- Si se especifica este conjunto de especificaciones de fecha, la canalización procesará la última fecha y almacenará el número de intervalo correspondiente en metadatos.
Por ejemplo, supongamos que hay datos de entrada organizados por fecha del calendario:
- '/tmp/1970-01-02/tren/datos'
- '/tmp/1970-01-02/eval/datos'
- '/tmp/1970-01-03/tren/datos'
- '/tmp/1970-01-03/eval/datos'
y la configuración de entrada se muestra a continuación:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
al activar la canalización, procesará:
- '/tmp/1970-01-03/train/data' como tren dividido
- '/tmp/1970-01-03/eval/data' como división de evaluación
con número de intervalo como '2'. Si más tarde '/tmp/1970-01-04/...' está listo, simplemente active la canalización nuevamente y tomará el intervalo '3' para su procesamiento. A continuación se muestra el ejemplo de código para usar la especificación de fecha:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Versión
La versión se puede recuperar usando la especificación '{VERSION}' en el patrón global de entrada :
- Esta especificación coincide con dígitos y asigna los datos a los números de VERSIÓN relevantes bajo SPAN. Tenga en cuenta que la especificación de versión se puede utilizar en combinación con la especificación de intervalo o de fecha.
- Esta especificación también se puede especificar opcionalmente con el ancho de la misma manera que la especificación SPAN. por ejemplo, 'span-{SPAN}/version-{VERSION:4}/data-*'.
- Cuando falta la especificación VERSIÓN, la versión se establece en Ninguna.
- Si se especifican SPAN y VERSION, la canalización procesará la última versión para el último intervalo y almacenará el número de versión en metadatos.
- Si se especifica VERSIÓN, pero no SPAN (o especificación de fecha), se generará un error.
Por ejemplo, supongamos que hay datos de entrada:
- '/tmp/span-1/ver-1/tren/datos'
- '/tmp/span-1/ver-1/eval/datos'
- '/tmp/span-2/ver-1/tren/datos'
- '/tmp/span-2/ver-1/eval/datos'
- '/tmp/span-2/ver-2/tren/datos'
- '/tmp/span-2/ver-2/eval/datos'
y la configuración de entrada se muestra a continuación:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
al activar la canalización, procesará:
- '/tmp/span-2/ver-2/train/data' como división de tren
- '/tmp/span-2/ver-2/eval/data' como división de evaluación
con el número de intervalo como '2' y el número de versión como '2'. Si más adelante '/tmp/span-2/ver-3/...' está listo, simplemente active la canalización nuevamente y seleccionará el intervalo '2' y la versión '3' para su procesamiento. A continuación se muestra el ejemplo de código para usar la especificación de versión:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Configuración de rango
TFX admite la recuperación y el procesamiento de un intervalo específico en EjemploGen basado en archivos mediante la configuración de rango, una configuración abstracta utilizada para describir rangos para diferentes entidades TFX. Para recuperar un intervalo específico, configure range_config para un componente de EjemploGen basado en archivos. Por ejemplo, supongamos que hay datos de entrada:
- '/tmp/span-01/tren/datos'
- '/tmp/span-01/eval/datos'
- '/tmp/span-02/tren/datos'
- '/tmp/span-02/eval/datos'
Para recuperar y procesar datos específicamente con intervalo '1', especificamos una configuración de rango además de la configuración de entrada. Tenga en cuenta que EjemploGen solo admite rangos estáticos de un solo tramo (para especificar el procesamiento de tramos individuales específicos). Por lo tanto, para StaticRange, start_span_number debe ser igual a end_span_number. Utilizando el intervalo proporcionado y la información del ancho del intervalo (si se proporciona) para el relleno con ceros, EjemploGen reemplazará la especificación SPAN en los patrones de división proporcionados con el número de intervalo deseado. A continuación se muestra un ejemplo de uso:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
La configuración de rango también se puede usar para procesar fechas específicas, si se usa la especificación de fecha en lugar de la especificación SPAN. Por ejemplo, supongamos que hay datos de entrada organizados por fecha del calendario:
- '/tmp/1970-01-02/tren/datos'
- '/tmp/1970-01-02/eval/datos'
- '/tmp/1970-01-03/tren/datos'
- '/tmp/1970-01-03/eval/datos'
Para recuperar y procesar datos específicamente el 2 de enero de 1970, hacemos lo siguiente:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Generación de ejemplos personalizados
Si los componentes de EjemploGen disponibles actualmente no se ajustan a sus necesidades, puede crear un EjemploGen personalizado, que le permitirá leer desde diferentes fuentes de datos o en diferentes formatos de datos.
Personalización de generación de ejemplos basada en archivos (experimental)
Primero, extienda BaseExampleGenExecutor con un Beam PTransform personalizado, que proporciona la conversión de su división de entrada de tren/evaluación a ejemplos de TF. Por ejemplo, el ejecutor CsvExampleGen proporciona la conversión de una división CSV de entrada a ejemplos TF.
Luego, cree un componente con el ejecutor anterior, como se hizo en el componente CsvExampleGen . Alternativamente, pase un ejecutor personalizado al componente estándar EjemploGen como se muestra a continuación.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Ahora también admitimos la lectura de archivos Avro y Parquet utilizando este método .
Formatos de datos adicionales
Apache Beam admite la lectura de varios formatos de datos adicionales . a través de transformaciones Beam I/O. Puede crear componentes personalizados de EjemploGen aprovechando las transformaciones de E/S de haz usando un patrón similar al ejemplo de Avro.
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Al momento de escribir este artículo, los formatos y fuentes de datos actualmente admitidos para el SDK de Beam Python incluyen:
- amazon s3
- apache avro
- apache hadoop
- Apache Kafka
- Parquet apache
- Google Cloud BigQuery
- Google Cloud BigTable
- Almacén de datos de Google Cloud
- Pub/Sub de Google Cloud
- Almacenamiento en la nube de Google (GCS)
- MongoDB
Consulte los documentos de Beam para obtener la lista más reciente.
Personalización de generación de ejemplos basada en consultas (experimental)
Primero, extienda BaseExampleGenExecutor con un Beam PTransform personalizado, que lee desde la fuente de datos externa. Luego, cree un componente simple extendiendo QueryBasedExampleGen.
Esto puede requerir o no configuraciones de conexión adicionales. Por ejemplo, el ejecutor de BigQuery lee mediante un conector beam.io predeterminado, que abstrae los detalles de configuración de la conexión. El ejecutor de Presto requiere un Beam PTransform personalizado y un protobuf de configuración de conexión personalizada como entrada.
Si se requiere una configuración de conexión para un componente de EjemploGen personalizado, cree un nuevo protobuf y páselo a través de custom_config, que ahora es un parámetro de ejecución opcional. A continuación se muestra un ejemplo de cómo utilizar un componente configurado.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Componentes posteriores de exampleGen
Se admite la configuración dividida personalizada para componentes posteriores.
EstadísticasGen
El comportamiento predeterminado es realizar la generación de estadísticas para todas las divisiones.
Para excluir cualquier división, configure exclude_splits para el componente StatisticsGen. Por ejemplo:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
El comportamiento predeterminado es generar un esquema basado en todas las divisiones.
Para excluir cualquier división, establezca exclude_splits para el componente SchemaGen. Por ejemplo:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Validador de ejemplo
El comportamiento predeterminado es validar las estadísticas de todas las divisiones en ejemplos de entrada con respecto a un esquema.
Para excluir cualquier división, establezca exclude_splits para el componente exampleValidator. Por ejemplo:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transformar
El comportamiento predeterminado es analizar y producir los metadatos de la división 'entrenar' y transformar todas las divisiones.
Para especificar las divisiones de análisis y transformación, configure splits_config para el componente Transformar. Por ejemplo:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Entrenador y sintonizador
El comportamiento predeterminado es entrenar en la división 'entrenar' y evaluar en la división 'evaluar'.
Para especificar las divisiones del tren y evaluar las divisiones, configure train_args y eval_args para el componente Trainer. Por ejemplo:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
evaluador
El comportamiento predeterminado es proporcionar métricas calculadas en la división 'eval'.
Para calcular estadísticas de evaluación en divisiones personalizadas, configure example_splits para el componente Evaluador. Por ejemplo:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Hay más detalles disponibles en la referencia de la API CsvExampleGen , la implementación de la API FileBasedExampleGen y la referencia de la API ImportExampleGen .