
يقوم مكون exampleGen TFX Pipeline بإدخال البيانات في خطوط أنابيب TFX. يستهلك ملفات/خدمات خارجية لإنشاء أمثلة ستتم قراءتها بواسطة مكونات TFX الأخرى. كما يوفر أيضًا قسمًا متسقًا وقابلاً للتكوين، ويقوم بخلط مجموعة البيانات للحصول على أفضل ممارسات تعلم الآلة.
- يستهلك: البيانات من مصادر البيانات الخارجية مثل CSV و
TFRecordوAvro وParquet وBigQuery. - يصدر: سجلات
tf.Example، أو سجلاتtf.SequenceExample، أو تنسيق أولي، اعتمادًا على تنسيق الحمولة.
exampleGen والمكونات الأخرى
يوفر exampleGen البيانات للمكونات التي تستخدم مكتبة TensorFlow Data Validator ، مثل SchemaGen و StatsatistGen و Example Validator . كما أنه يوفر البيانات إلى التحويل ، الذي يستخدم مكتبة TensorFlow Transform ، وفي النهاية إلى أهداف النشر أثناء الاستدلال.
مصادر البيانات وتنسيقاتها
يشتمل التثبيت القياسي لـ TFX حاليًا على مكونات exampleGen الكاملة لمصادر البيانات وتنسيقاتها:
تتوفر أيضًا برامج تنفيذية مخصصة تتيح تطوير مكونات exampleGen لمصادر البيانات وتنسيقاتها:
راجع أمثلة الاستخدام في الكود المصدري وهذه المناقشة لمزيد من المعلومات حول كيفية استخدام وتطوير المنفذين المخصصين.
بالإضافة إلى ذلك، تتوفر مصادر البيانات وتنسيقاتها كأمثلة للمكونات المخصصة :
استيعاب تنسيقات البيانات التي يدعمها Apache Beam
يدعم Apache Beam استيعاب البيانات من نطاق واسع من مصادر البيانات وتنسيقاتها ( انظر أدناه ). يمكن استخدام هذه الإمكانات لإنشاء مكونات exampleGen مخصصة لـ TFX، وهو ما يتم توضيحه من خلال بعض مكونات exampleGen الموجودة ( انظر أدناه ).
كيفية استخدام مكون exampleGen
بالنسبة لمصادر البيانات المدعومة (حاليًا، ملفات CSV، وملفات TFRecord مع tf.Example ، و tf.SequenceExample ، وتنسيق proto، ونتائج استعلامات BigQuery)، يمكن استخدام مكون خط الأنابيب exampleGen مباشرة في النشر ويتطلب القليل من التخصيص. على سبيل المثال:
example_gen = CsvExampleGen(input_base='data_root')
أو كما هو موضح أدناه لاستيراد TFRecord خارجي باستخدام tf.Example مباشرة:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
سبان، الإصدار والانقسام
Span عبارة عن مجموعة من أمثلة التدريب. إذا ظلت بياناتك موجودة في نظام الملفات، فقد يتم تخزين كل Span في دليل منفصل. لم يتم تشفير دلالات Span في TFX؛ قد يتوافق Span مع يوم من البيانات، أو ساعة من البيانات، أو أي مجموعة أخرى ذات معنى لمهمتك.
يمكن لكل Span أن يحتوي على إصدارات متعددة من البيانات. على سبيل المثال، إذا قمت بإزالة بعض الأمثلة من Span لتنظيف البيانات ذات الجودة الرديئة، فقد يؤدي ذلك إلى إصدار جديد من Span. افتراضيًا، تعمل مكونات TFX على أحدث إصدار ضمن نطاق Span.
يمكن أيضًا تقسيم كل إصدار ضمن النطاق إلى تقسيمات متعددة. حالة الاستخدام الأكثر شيوعًا لتقسيم النطاق هي تقسيمه إلى بيانات تدريب وتقييم.
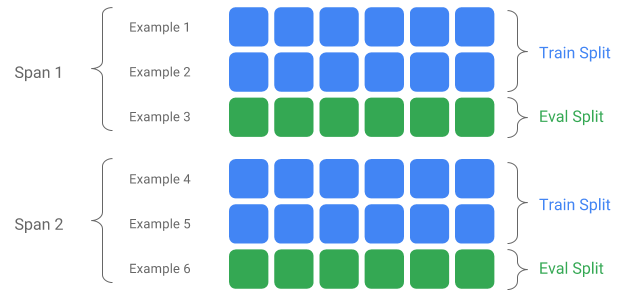
تقسيم الإدخال/الإخراج المخصص
لتخصيص نسبة تقسيم التدريب/التقييم التي سيخرجها exampleGen، قم بتعيين output_config لمكون exampleGen. على سبيل المثال:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
لاحظ كيف تم تعيين hash_buckets في هذا المثال.
بالنسبة لمصدر الإدخال الذي تم تقسيمه بالفعل، قم بتعيين input_config لمكون exampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
بالنسبة إلى المثال المستند إلى الملف (على سبيل المثال CsvExampleGen وImportExampleGen)، pattern هو نمط ملف نسبي عالمي يتم تعيينه لملفات الإدخال مع الدليل الجذر المحدد بواسطة المسار الأساسي للإدخال. بالنسبة إلى المثال العام المستند إلى الاستعلام (مثل BigQueryExampleGen، وPrestoExampleGen)، pattern هو استعلام SQL.
افتراضيًا، يتم التعامل مع قاعدة الإدخال بأكملها كتقسيم إدخال واحد، ويتم إنشاء تقسيم إخراج التدريب والتقييم بنسبة 2:1.
يرجى الرجوع إلى proto/example_gen.proto للتعرف على تكوين تقسيم الإدخال والإخراج الخاص بـ exampleGen. وارجع إلى دليل المكونات النهائية لاستخدام الانقسامات المخصصة في اتجاه مجرى النهر.
طريقة التقسيم
عند استخدام طريقة تقسيم hash_buckets ، بدلاً من السجل بأكمله، يمكن للمرء استخدام ميزة لتقسيم الأمثلة. في حالة وجود ميزة ما، سيستخدم exampleGen بصمة تلك الميزة كمفتاح القسم.
يمكن استخدام هذه الميزة للحفاظ على تقسيم مستقر عن طريق خصائص معينة للأمثلة: على سبيل المثال، سيتم دائمًا وضع المستخدم في نفس القسم إذا تم تحديد "user_id" كاسم ميزة القسم.
يعتمد تفسير معنى "الميزة" وكيفية مطابقة "الميزة" مع الاسم المحدد على تطبيق exampleGen ونوع الأمثلة.
لتطبيقات exampleGen الجاهزة:
- إذا قام بإنشاء tf.Example، فإن "الميزة" تعني إدخالاً في tf.Example.features.feature.
- إذا قام بإنشاء tf.SequenceExample، فإن "الميزة" تعني إدخالاً في tf.SequenceExample.context.feature.
- يتم دعم ميزات int64 وbytes فقط.
في الحالات التالية، يعرض exampleGen أخطاء وقت التشغيل:
- اسم الميزة المحددة غير موجود في المثال.
- ميزة فارغة:
tf.train.Feature(). - أنواع الميزات غير المدعومة، على سبيل المثال، الميزات العائمة.
لإخراج تقسيم التدريب/التقييم بناءً على إحدى الميزات الموجودة في الأمثلة، قم بتعيين output_config لمكون exampleGen. على سبيل المثال:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
لاحظ كيف تم تعيين partition_feature_name في هذا المثال.
فترة
يمكن استرداد النطاق باستخدام مواصفات '{SPAN}' في نمط الإدخال الشامل :
- تتطابق هذه المواصفات مع الأرقام وتقوم بتعيين البيانات في أرقام SPAN ذات الصلة. على سبيل المثال، سيقوم "data_{SPAN}-*.tfrecord" بجمع ملفات مثل "data_12-a.tfrecord" و"data_12-b.tfrecord".
- اختياريًا، يمكن تحديد هذه المواصفات بعرض الأعداد الصحيحة عند تعيينها. على سبيل المثال، يتم تعيين 'data_{SPAN:2}.file' إلى ملفات مثل 'data_02.file' و'data_27.file' (كمدخلات لـ Span-2 وSpan-27 على التوالي)، ولكنه لا يتم تعيينه إلى 'data_1. ملف "ولا" data_123.file ".
- عندما تكون مواصفات SPAN مفقودة، فمن المفترض أن تكون Span '0' دائمًا.
- إذا تم تحديد SPAN، فسيقوم خط الأنابيب بمعالجة النطاق الأخير، وتخزين رقم النطاق في بيانات التعريف.
على سبيل المثال، لنفترض أن هناك بيانات إدخال:
- "/tmp/span-1/القطار/البيانات"
- '/tmp/span-1/التقييم/البيانات'
- "/tmp/span-2/القطار/البيانات"
- '/tmp/span-2/التقييم/البيانات'
ويظهر تكوين الإدخال على النحو التالي:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
عند تشغيل خط الأنابيب، سيتم معالجة:
- "/tmp/span-2/train/data" كتقسيم للقطار
- "/tmp/span-2/eval/data" كتقسيم تقييمي
مع رقم الامتداد كـ "2". إذا أصبح "/tmp/span-3/..." جاهزًا لاحقًا، فما عليك سوى تشغيل خط الأنابيب مرة أخرى وسوف يلتقط النطاق "3" للمعالجة. يظهر أدناه مثال التعليمات البرمجية لاستخدام مواصفات النطاق:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
يمكن استرداد نطاق معين باستخدام RangeConfig، وهو ما هو مفصل أدناه.
تاريخ
إذا تم تنظيم مصدر البيانات الخاص بك على نظام الملفات حسب التاريخ، فإن TFX يدعم تعيين التواريخ مباشرة لتشمل الأرقام. هناك ثلاث مواصفات لتمثيل التعيين من التواريخ إلى الامتدادات: {YYYY} و{MM} و{DD}:
- يجب أن تكون المواصفات الثلاثة موجودة تمامًا في نمط الإدخال الشامل إذا تم تحديد أي منها:
- يمكن تحديد مواصفات {SPAN} أو مجموعة مواصفات التاريخ هذه بشكل حصري.
- يتم حساب تاريخ تقويمي بالسنة من YYYY، والشهر من MM، ويوم الشهر من DD، ثم يتم حساب رقم النطاق كعدد الأيام منذ عصر Unix (أي 1970-01-01). على سبيل المثال، يتطابق "log-{YYYY}{MM}{DD}.data" مع ملف "log-19700101.data" ويستهلكه كمدخل لـ Span-0، و"log-20170101.data" كمدخل لـ Span-0. سبان-17167.
- إذا تم تحديد هذه المجموعة من مواصفات التاريخ، فسيقوم المسار بمعالجة أحدث تاريخ، وتخزين رقم النطاق المقابل في البيانات التعريفية.
على سبيل المثال، لنفترض أن هناك بيانات إدخال منظمة حسب تاريخ التقويم:
- '/tmp/1970-01-02/القطار/البيانات'
- '/tmp/1970-01-02/التقييم/البيانات'
- '/tmp/1970-01-03/القطار/البيانات'
- '/tmp/1970-01-03/التقييم/البيانات'
ويظهر تكوين الإدخال على النحو التالي:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
عند تشغيل خط الأنابيب، سيتم معالجة:
- '/tmp/1970-01-03/train/data' كقطار مقسم
- "/tmp/1970-01-03/eval/data" كتقسيم تقييم
مع رقم الامتداد كـ "2". إذا أصبح "/tmp/1970-01-04/..." جاهزًا لاحقًا، فما عليك سوى تشغيل خط الأنابيب مرة أخرى وسوف يلتقط النطاق "3" للمعالجة. يظهر أدناه مثال التعليمات البرمجية لاستخدام مواصفات التاريخ:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
إصدار
يمكن استرداد الإصدار باستخدام مواصفات '{VERSION}' في نمط الإدخال الشامل :
- تتطابق هذه المواصفات مع الأرقام وتقوم بتعيين البيانات إلى أرقام الإصدار ذات الصلة ضمن SPAN. لاحظ أنه يمكن استخدام مواصفات الإصدار مع مواصفات Span أو Date.
- يمكن أيضًا تحديد هذه المواصفات اختياريًا بالعرض بنفس طريقة مواصفات SPAN. على سبيل المثال "span-{SPAN}/version-{VERSION:4}/data-*".
- عندما تكون مواصفات VERSION مفقودة، يتم تعيين الإصدار على لا شيء.
- إذا تم تحديد SPAN وVERSION، فسيقوم خط الأنابيب بمعالجة الإصدار الأحدث لأحدث فترة، وتخزين رقم الإصدار في بيانات التعريف.
- إذا تم تحديد VERSION، ولكن ليس SPAN (أو مواصفات التاريخ)، فسيتم ظهور خطأ.
على سبيل المثال، لنفترض أن هناك بيانات إدخال:
- "/tmp/span-1/ver-1/train/data"
- '/tmp/span-1/ver-1/التقييم/البيانات'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/التقييم/البيانات'
- "/tmp/span-2/ver-2/train/data"
- '/tmp/span-2/ver-2/eval/data'
ويظهر تكوين الإدخال على النحو التالي:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
عند تشغيل خط الأنابيب، سيتم معالجة:
- '/tmp/span-2/ver-2/train/data' كقطار مقسم
- "/tmp/span-2/ver-2/eval/data" كتقسيم تقييمي
مع رقم النطاق كـ "2" ورقم الإصدار كـ "2". إذا أصبح "/tmp/span-2/ver-3/..." جاهزًا لاحقًا، فما عليك سوى تشغيل خط الأنابيب مرة أخرى وسوف يلتقط النطاق "2" والإصدار "3" للمعالجة. يظهر أدناه مثال التعليمات البرمجية لاستخدام مواصفات الإصدار:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
تكوين النطاق
يدعم TFX استرجاع ومعالجة نطاق معين في exampleGen القائم على الملفات باستخدام تكوين النطاق، وهو تكوين مجرد يستخدم لوصف النطاقات لكيانات TFX المختلفة. لاسترداد نطاق معين، قم بتعيين range_config لمكون exampleGen المستند إلى الملف. على سبيل المثال، لنفترض أن هناك بيانات إدخال:
- '/tmp/span-01/القطار/البيانات'
- '/tmp/span-01/التقييم/البيانات'
- '/tmp/span-02/القطار/البيانات'
- '/tmp/span-02/التقييم/البيانات'
لاسترداد البيانات ومعالجتها على وجه التحديد بالامتداد "1"، نحدد تكوين نطاق بالإضافة إلى تكوين الإدخال. لاحظ أن exampleGen يدعم فقط النطاقات الثابتة ذات النطاق المفرد (لتحديد معالجة نطاقات فردية محددة). وبالتالي، بالنسبة إلى StaticRange، يجب أن يساوي start_span_number end_span_number. باستخدام النطاق المقدم ومعلومات عرض النطاق (إذا تم توفيرها) للحشوة الصفرية، سيستبدل exampleGen مواصفات SPAN في أنماط الانقسام المتوفرة برقم النطاق المطلوب. يظهر مثال للاستخدام أدناه:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
يمكن أيضًا استخدام تكوين النطاق لمعالجة تواريخ محددة، إذا تم استخدام مواصفات التاريخ بدلاً من مواصفات SPAN. على سبيل المثال، لنفترض أن هناك بيانات إدخال منظمة حسب تاريخ التقويم:
- '/tmp/1970-01-02/القطار/البيانات'
- '/tmp/1970-01-02/التقييم/البيانات'
- '/tmp/1970-01-03/القطار/البيانات'
- '/tmp/1970-01-03/التقييم/البيانات'
لاسترداد البيانات ومعالجتها على وجه التحديد في الثاني من يناير عام 1970، نقوم بما يلي:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
مثال مخصص
إذا كانت مكونات exampleGen المتوفرة حاليًا لا تناسب احتياجاتك، فيمكنك إنشاء exampleGen مخصص، والذي سيمكنك من القراءة من مصادر بيانات مختلفة أو بتنسيقات بيانات مختلفة.
تخصيص exampleGen القائم على الملف (تجريبي)
أولاً، قم بتوسيع BaseExampleGenExecutor باستخدام Beam PTransform المخصص، والذي يوفر التحويل من تقسيم إدخال التدريب/التقييم إلى أمثلة TF. على سبيل المثال، يوفر المنفذ CsvExampleGen التحويل من تقسيم إدخال CSV إلى أمثلة TF.
بعد ذلك، قم بإنشاء مكون بالمنفذ أعلاه، كما هو الحال في مكون CsvExampleGen . وبدلاً من ذلك، قم بتمرير منفذ تنفيذي مخصص إلى مكون exampleGen القياسي كما هو موضح أدناه.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
الآن، ندعم أيضًا قراءة ملفات Avro وParquet باستخدام هذه الطريقة .
تنسيقات البيانات الإضافية
يدعم Apache Beam قراءة عدد من تنسيقات البيانات الإضافية . من خلال تحويلات I/O لشعاع. يمكنك إنشاء مكونات exampleGen مخصصة من خلال الاستفادة من تحويلات الإدخال/الإخراج لـ Beam باستخدام نمط مشابه لمثال Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
حتى كتابة هذه السطور، تتضمن التنسيقات ومصادر البيانات المدعومة حاليًا لـ Beam Python SDK ما يلي:
- أمازون إس 3
- أباتشي أفرو
- أباتشي هادوب
- أباتشي كافكا
- أباتشي باركيه
- جوجل السحابية BigQuery
- جوجل السحابية الكبيرة
- مخزن بيانات جوجل السحابي
- Google Cloud Pub/Sub
- جوجل للتخزين السحابي (GCS)
- MongoDB
تحقق من مستندات Beam للحصول على أحدث القائمة.
تخصيص exampleGen القائم على الاستعلام (تجريبي)
أولاً، قم بتوسيع BaseExampleGenExecutor باستخدام Beam PTransform المخصص، والذي يقرأ من مصدر البيانات الخارجي. ثم قم بإنشاء مكون بسيط عن طريق توسيع QueryBasedExampleGen.
قد يتطلب هذا أو لا يتطلب تكوينات اتصال إضافية. على سبيل المثال، يقرأ منفذ BigQuery باستخدام موصل Beam.io الافتراضي، الذي يلخص تفاصيل تكوين الاتصال. يتطلب منفذ Presto Beam PTransform مخصصًا و protobuf لتكوين اتصال مخصص كمدخل.
إذا كان تكوين الاتصال مطلوبًا لمكون ExceptionGen مخصص، فقم بإنشاء protobuf جديد وقم بتمريره من خلال custom_config، والذي أصبح الآن معلمة تنفيذ اختيارية. فيما يلي مثال لكيفية استخدام المكون الذي تم تكوينه.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
exampleGen مكونات المصب
يتم دعم التكوين المقسم المخصص للمكونات النهائية.
الإحصائيات
السلوك الافتراضي هو إنشاء الإحصائيات لجميع الانقسامات.
لاستبعاد أي انقسامات، قم بتعيين exclude_splits لمكون StatisticsGen. على سبيل المثال:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
مخطط
السلوك الافتراضي هو إنشاء مخطط يعتمد على كافة الانقسامات.
لاستبعاد أي انقسامات، قم بتعيين exclude_splits لمكون SchemaGen. على سبيل المثال:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
مثالValidator
السلوك الافتراضي هو التحقق من صحة إحصائيات جميع الانقسامات في أمثلة الإدخال مقابل المخطط.
لاستبعاد أي انقسامات، قم بتعيين exclude_splits لمكون exampleValidator. على سبيل المثال:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
تحويل
السلوك الافتراضي هو تحليل وإنتاج البيانات التعريفية من تقسيم "القطار" وتحويل كافة الانقسامات.
لتحديد تقسيمات التحليل وتقسيمات التحويل، قم بتعيين splits_config لمكون التحويل. على سبيل المثال:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
المدرب والموالف
السلوك الافتراضي هو التدريب على تقسيم "القطار" وتقييمه على تقسيم "التقييم".
لتحديد تقسيمات القطار وتقييم الانقسامات، قم بتعيين train_args و eval_args لمكون Trainer. على سبيل المثال:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
مقيم
السلوك الافتراضي هو توفير المقاييس المحسوبة على تقسيم "التقييم".
لحساب إحصائيات التقييم على الانقسامات المخصصة، قم بتعيين example_splits لمكون المُقيم. على سبيل المثال:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
تتوفر المزيد من التفاصيل في مرجع CsvExampleGen API وتنفيذ FileBasedExampleGen API ومرجع ImportExampleGen API .