
Os Indicadores de Justiça foram projetados para apoiar as equipes na avaliação e melhoria de modelos para questões de justiça em parceria com o kit de ferramentas mais amplo do Tensorflow. A ferramenta é atualmente usada ativamente internamente por muitos de nossos produtos e agora está disponível em BETA para você testar em seus próprios casos de uso.
O que são indicadores de justiça?
Fairness Indicators é uma biblioteca que permite o cálculo fácil de métricas de imparcialidade comumente identificadas para classificadores binários e multiclasse. Muitas ferramentas existentes para avaliar questões de justiça não funcionam bem em conjuntos de dados e modelos de grande escala. No Google, é importante que tenhamos ferramentas que possam funcionar em sistemas com bilhões de usuários. Os indicadores de justiça permitirão que você avalie casos de uso de qualquer tamanho.
Em particular, os Indicadores de Justiça incluem a capacidade de:
- Avalie a distribuição de conjuntos de dados
- Avalie o desempenho do modelo, dividido em grupos definidos de usuários
- Sinta-se confiante em relação aos seus resultados com intervalos de confiança e avaliações em vários limites
- Mergulhe profundamente em fatias individuais para explorar as causas raízes e oportunidades de melhoria
O download do pacote pip inclui:
- Validação de dados do Tensorflow (TFDV)
- Análise do modelo Tensorflow (TFMA)
- Indicadores de Justiça
- A ferramenta What-If (WIT)
Usando indicadores de justiça com modelos Tensorflow
Dados
Para executar Indicadores de Justiça com TFMA, certifique-se de que o conjunto de dados de avaliação esteja rotulado para os recursos que você gostaria de dividir. Se você não tiver os recursos de fatia exatos para suas preocupações de justiça, poderá tentar encontrar um conjunto de avaliação que tenha ou considerar recursos de proxy em seu conjunto de recursos que possam destacar disparidades de resultados. Para orientação adicional, veja aqui .
Modelo
Você pode usar a classe Tensorflow Estimator para construir seu modelo. O suporte para modelos Keras chegará em breve ao TFMA. Se você deseja executar o TFMA em um modelo Keras, consulte a seção “TFMA independente de modelo” abaixo.
Após o treinamento do seu Estimador, você precisará exportar um modelo salvo para fins de avaliação. Para saber mais, consulte o guia TFMA .
Configurando fatias
A seguir, defina as fatias que você gostaria de avaliar:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Se quiser avaliar fatias interseccionais (por exemplo, cor e altura do pelo), você pode definir o seguinte:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Métricas de justiça computacional
Adicione um retorno de chamada de Indicadores de Justiça à lista metrics_callback . No retorno de chamada, você pode definir uma lista de limites nos quais o modelo será avaliado.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Antes de executar a configuração, determine se deseja ou não ativar o cálculo de intervalos de confiança. Os intervalos de confiança são calculados usando inicialização de Poisson e requerem recomputação em 20 amostras.
compute_confidence_intervals = True
Execute o pipeline de avaliação do TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Indicadores de imparcialidade de renderização
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Dicas para usar Indicadores de Justiça:
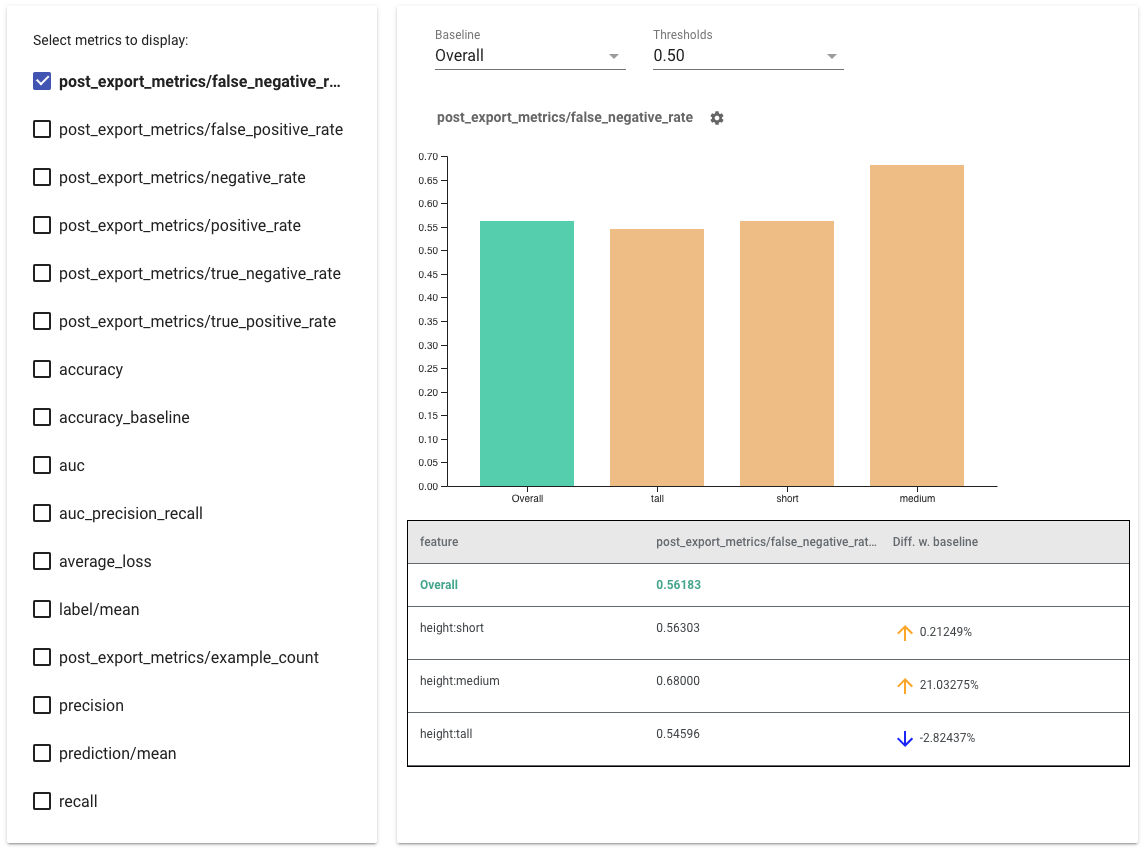
- Selecione as métricas a serem exibidas marcando as caixas do lado esquerdo. Gráficos individuais para cada uma das métricas aparecerão no widget, em ordem.
- Altere a fatia da linha de base , a primeira barra do gráfico, usando o seletor suspenso. Os deltas serão calculados com este valor de linha de base.
- Selecione limites usando o seletor suspenso. Você pode visualizar vários limites no mesmo gráfico. Os limites selecionados estarão em negrito e você pode clicar em um limite em negrito para desmarcá-lo.
- Passe o mouse sobre uma barra para ver as métricas dessa fatia.
- Identifique disparidades com a linha de base usando a coluna "Diferença com linha de base", que identifica a diferença percentual entre a fatia atual e a linha de base.
- Explore detalhadamente os pontos de dados de uma fatia usando a ferramenta What-If . Veja aqui um exemplo.
Renderizando indicadores de imparcialidade para vários modelos
Os Indicadores de Justiça também podem ser usados para comparar modelos. Em vez de passar um único eval_result, passe um objeto multi_eval_results, que é um dicionário que mapeia dois nomes de modelos para objetos eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
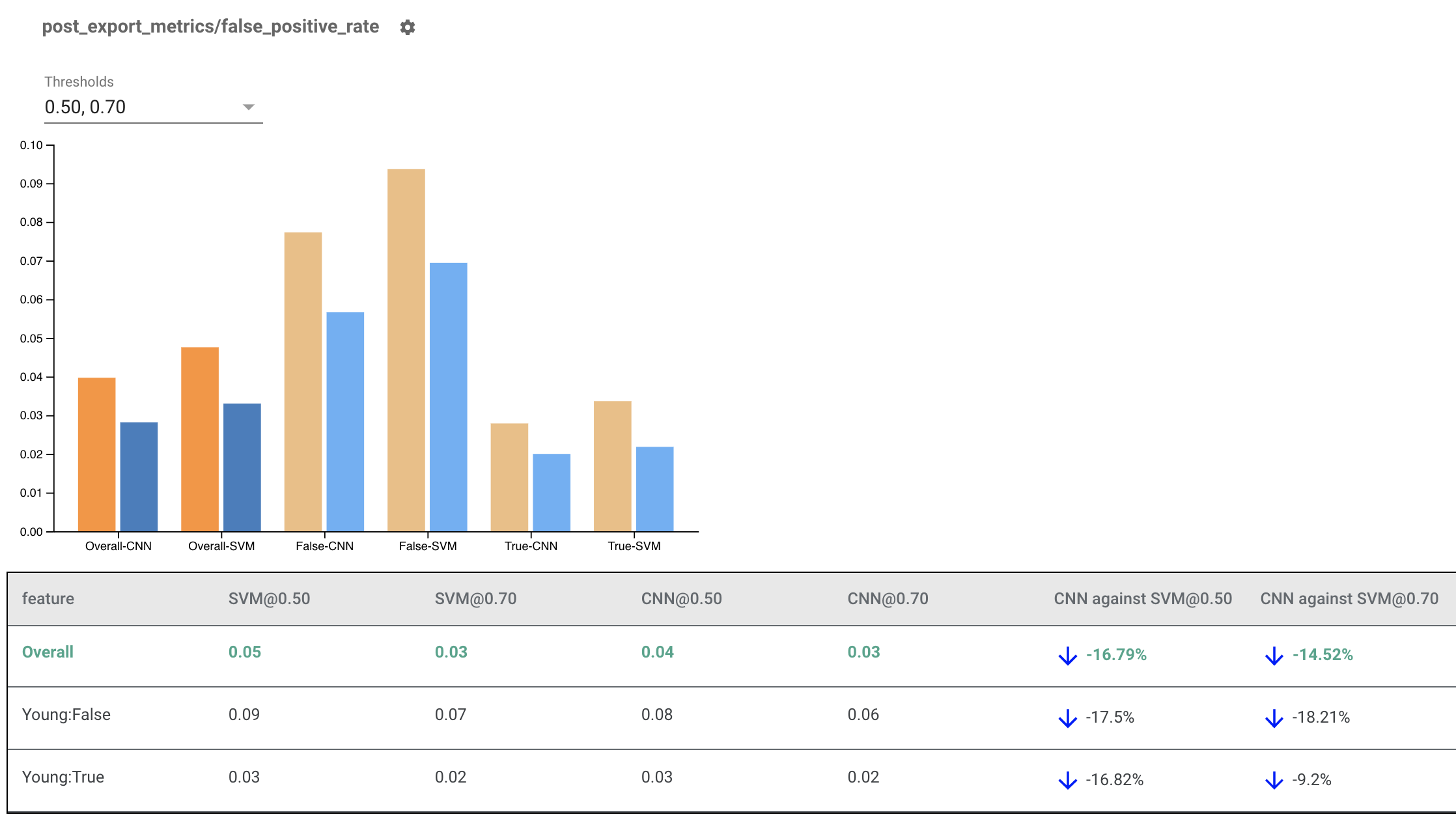
A comparação de modelos pode ser usada junto com a comparação de limites. Por exemplo, você pode comparar dois modelos em dois conjuntos de limites para encontrar a combinação ideal para suas métricas de imparcialidade.
Usando indicadores de justiça com modelos não TensorFlow
Para melhor atender clientes que possuem diferentes modelos e fluxos de trabalho, desenvolvemos uma biblioteca de avaliação independente do modelo que está sendo avaliado.
Qualquer pessoa que queira avaliar seu sistema de aprendizado de máquina pode usar isso, especialmente se você tiver modelos não baseados no TensorFlow. Usando o Apache Beam Python SDK, você pode criar um binário de avaliação TFMA independente e executá-lo para analisar seu modelo.
Dados
Esta etapa é fornecer o conjunto de dados no qual você deseja que as avaliações sejam executadas. Deve estar no formato proto tf.Example com rótulos, previsões e outros recursos que você pode querer dividir.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Modelo
Em vez de especificar um modelo, você cria uma configuração e um extrator de avaliação independente do modelo para analisar e fornecer os dados que o TFMA precisa para calcular métricas. A especificação ModelAgnosticConfig define os recursos, previsões e rótulos a serem usados nos exemplos de entrada.
Para isso, crie um mapa de recursos com chaves que representam todos os recursos, incluindo chaves de rótulo e predição e valores que representam o tipo de dados do recurso.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Crie uma configuração independente de modelo usando chaves de rótulo, chaves de previsão e mapa de recursos.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Configurar o extrator independente de modelo
O extrator é usado para extrair os recursos, rótulos e previsões da entrada usando configuração independente do modelo. E se quiser fatiar seus dados, você também precisa definir a slice key spec , contendo informações sobre as colunas que deseja fatiar.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Métricas de justiça computacional
Como parte de EvalSharedModel , você pode fornecer todas as métricas nas quais deseja que seu modelo seja avaliado. As métricas são fornecidas na forma de retornos de chamada de métricas, como os definidos em post_export_metrics ou fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Ele também leva um construct_fn que é usado para criar um gráfico tensorflow para realizar a avaliação.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Depois que tudo estiver configurado, use uma das funções ExtractEvaluate ou ExtractEvaluateAndWriteResults fornecidas por model_eval_lib para avaliar o modelo.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Por fim, renderize Indicadores de Equidade usando as instruções da seção "Renderizar Indicadores de Equidade" acima.
Mais exemplos
O diretório de exemplos de Indicadores de Justiça contém vários exemplos:
- Fairness_Indicators_Example_Colab.ipynb fornece uma visão geral dos indicadores de justiça na análise de modelo do TensorFlow e como usá-los com um conjunto de dados real. Este notebook também aborda a validação de dados do TensorFlow e a ferramenta What-If , duas ferramentas para analisar modelos do TensorFlow que vêm com indicadores de justiça.
- Fairness_Indicators_on_TF_Hub.ipynb demonstra como usar indicadores de justiça para comparar modelos treinados em diferentes incorporações de texto . Este notebook usa incorporações de texto do TensorFlow Hub , a biblioteca do TensorFlow para publicar, descobrir e reutilizar componentes do modelo.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb demonstra como visualizar indicadores de justiça no TensorBoard.