
Em geral
Um EvalSavedModel ainda é necessário?
Anteriormente, o TFMA exigia que todas as métricas fossem armazenadas em um gráfico tensorflow usando um EvalSavedModel especial. Agora, as métricas podem ser calculadas fora do gráfico TF usando implementações beam.CombineFn .
Algumas das principais diferenças são:
- Um
EvalSavedModelrequer uma exportação especial do treinador, enquanto um modelo de serviço pode ser usado sem quaisquer alterações necessárias no código de treinamento. - Quando um
EvalSavedModelé usado, quaisquer métricas adicionadas no momento do treinamento ficam automaticamente disponíveis no momento da avaliação. Sem umEvalSavedModelessas métricas devem ser adicionadas novamente.- A exceção a esta regra é que se um modelo keras for usado, as métricas também poderão ser adicionadas automaticamente porque keras salva as informações de métrica junto com o modelo salvo.
O TFMA pode trabalhar com métricas internas e externas?
O TFMA permite que uma abordagem híbrida seja usada onde algumas métricas podem ser calculadas no gráfico, enquanto outras podem ser calculadas externamente. Se você possui atualmente um EvalSavedModel , poderá continuar a usá-lo.
Existem dois casos:
- Use TFMA
EvalSavedModelpara extração de recursos e cálculos de métricas, mas também adicione métricas adicionais baseadas em combinador. Nesse caso, você obteria todas as métricas do gráfico doEvalSavedModeljunto com quaisquer métricas adicionais do combinador que talvez não tenham sido suportadas anteriormente. - Use TFMA
EvalSavedModelpara extração de recursos/predição, mas use métricas baseadas em combinador para todos os cálculos de métricas. Este modo é útil se houver transformações de recursos presentes noEvalSavedModelque você gostaria de usar para fatiar, mas prefere realizar todos os cálculos métricos fora do gráfico.
Configurar
Quais tipos de modelo são suportados?
TFMA suporta modelos keras, modelos baseados em APIs genéricas de assinatura TF2, bem como modelos baseados em estimadores TF (embora dependendo do caso de uso, os modelos baseados em estimadores possam exigir o uso de um EvalSavedModel ).
Consulte o guia get_started para obter a lista completa de tipos de modelos suportados e quaisquer restrições.
Como configuro o TFMA para funcionar com um modelo nativo baseado em keras?
A seguir está um exemplo de configuração para um modelo keras com base nas seguintes suposições:
- O modelo salvo é para veiculação e usa o nome de assinatura
serving_default(isso pode ser alterado usandomodel_specs[0].signature_name). - As métricas integradas de
model.compile(...)devem ser avaliadas (isso pode ser desativado por meio deoptions.include_default_metricdentro de tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre outros tipos de métricas que podem ser configuradas.
Como configuro o TFMA para funcionar com um modelo genérico baseado em assinaturas TF2?
A seguir está um exemplo de configuração para um modelo TF2 genérico. Abaixo, signature_name é o nome da assinatura específica que deve ser usada para avaliação.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre outros tipos de métricas que podem ser configuradas.
Como configuro o TFMA para funcionar com um modelo baseado em estimador?
Neste caso existem três opções.
Opção 1: usar modelo de veiculação
Se esta opção for usada, quaisquer métricas adicionadas durante o treinamento NÃO serão incluídas na avaliação.
A seguir está um exemplo de configuração assumindo que serving_default é o nome da assinatura usado:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre outros tipos de métricas que podem ser configuradas.
Opção 2: Use EvalSavedModel junto com métricas adicionais baseadas em combinador
Nesse caso, use EvalSavedModel para extração e avaliação de recursos/predição e também adicione métricas adicionais baseadas em combinador.
A seguir está um exemplo de configuração:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre outros tipos de métricas que podem ser configuradas e EvalSavedModel para obter mais informações sobre como configurar o EvalSavedModel.
Opção 3: Use o modelo EvalSavedModel apenas para extração de recurso/predição
Semelhante à opção (2), mas use apenas EvalSavedModel para extração de recursos/predição. Esta opção é útil se apenas métricas externas forem desejadas, mas houver transformações de recursos que você gostaria de dividir. Semelhante à opção (1), quaisquer métricas adicionadas durante o treinamento NÃO serão incluídas na avaliação.
Neste caso a configuração é a mesma acima, apenas include_default_metrics está desabilitado.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre outros tipos de métricas que podem ser configuradas e EvalSavedModel para obter mais informações sobre como configurar o EvalSavedModel.
Como configuro o TFMA para funcionar com um modelo baseado em modelo para estimador Keras?
A configuração do keras model_to_estimator é semelhante à configuração do estimador. No entanto, existem algumas diferenças específicas em como funciona o modelo para o estimador. Em particular, o model-to-esimtator retorna suas saídas na forma de um dict onde a chave do dict é o nome da última camada de saída no modelo keras associado (se nenhum nome for fornecido, keras escolherá um nome padrão para você como dense_1 ou output_1 ). Do ponto de vista do TFMA, esse comportamento é semelhante ao que seria produzido para um modelo de múltiplos resultados, mesmo que o modelo a ser estimador possa ser apenas para um único modelo. Para compensar essa diferença, é necessária uma etapa adicional para configurar o nome de saída. No entanto, as mesmas três opções se aplicam como estimador.
Veja a seguir um exemplo das alterações necessárias em uma configuração baseada em estimador:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Como configuro o TFMA para funcionar com previsões pré-calculadas (ou seja, independentes de modelo)? ( TFRecord e tf.Example )
Para configurar o TFMA para funcionar com previsões pré-calculadas, o tfma.PredictExtractor padrão deve ser desabilitado e o tfma.InputExtractor deve ser configurado para analisar as previsões junto com os outros recursos de entrada. Isso é feito configurando um tfma.ModelSpec com o nome da chave de recurso usada para as previsões junto com os rótulos e pesos.
A seguir está um exemplo de configuração:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obter mais informações sobre métricas que podem ser configuradas.
Observe que embora um tfma.ModelSpec esteja sendo configurado, um modelo não está realmente sendo usado (ou seja, não há tfma.EvalSharedModel ). A chamada para executar a análise do modelo pode ser assim:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Como configuro o TFMA para funcionar com previsões pré-calculadas (ou seja, independentes de modelo)? ( pd.DataFrame )
Para pequenos conjuntos de dados que cabem na memória, uma alternativa ao TFRecord é um pandas.DataFrame s. TFMA pode operar em pandas.DataFrame s usando a API tfma.analyze_raw_data . Para obter uma explicação sobre tfma.MetricsSpec e tfma.SlicingSpec , consulte o guia de configuração . Consulte métricas para obter mais informações sobre métricas que podem ser configuradas.
A seguir está um exemplo de configuração:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Métricas
Que tipos de métricas são suportadas?
TFMA oferece suporte a uma ampla variedade de métricas, incluindo:
- métricas de regressão
- métricas de classificação binária
- métricas de classificação multiclasse/multirótulo
- métricas micro média/macro média
- métricas baseadas em consulta/classificação
As métricas de modelos de múltiplas saídas são suportadas?
Sim. Consulte o guia de métricas para obter mais detalhes.
As métricas de vários modelos são suportadas?
Sim. Consulte o guia de métricas para obter mais detalhes.
As configurações de métricas (nome, etc.) podem ser personalizadas?
Sim. As configurações de métricas podem ser personalizadas (por exemplo, definição de limites específicos, etc.) adicionando config à configuração da métrica. Consulte o guia de métricas com mais detalhes.
As métricas personalizadas são suportadas?
Sim. Escrevendo uma implementação tf.keras.metrics.Metric personalizada ou escrevendo uma implementação beam.CombineFn personalizada. O guia de métricas tem mais detalhes.
Que tipos de métricas não são compatíveis?
Contanto que sua métrica possa ser calculada usando beam.CombineFn , não há restrições sobre os tipos de métricas que podem ser calculadas com base em tfma.metrics.Metric . Se estiver trabalhando com uma métrica derivada de tf.keras.metrics.Metric , os seguintes critérios deverão ser atendidos:
- Deveria ser possível calcular estatísticas suficientes para a métrica em cada exemplo de forma independente, depois combinar estas estatísticas suficientes adicionando-as a todos os exemplos e determinar o valor da métrica apenas a partir destas estatísticas suficientes.
- Por exemplo, para precisão, as estatísticas suficientes são "totalmente correto" e "total de exemplos". É possível calcular esses dois números para exemplos individuais e somá-los para formar um grupo de exemplos para obter os valores corretos para esses exemplos. A precisão final pode ser calculada usando "exemplos totais corretos/totais".
Complementos
Posso usar o TFMA para avaliar a imparcialidade ou o preconceito no meu modelo?
O TFMA inclui um complemento FairnessIndicators que fornece métricas pós-exportação para avaliar os efeitos de vieses não intencionais em modelos de classificação.
Personalização
E se eu precisar de mais personalização?
O TFMA é muito flexível e permite personalizar quase todas as partes do pipeline usando Extractors , Evaluators e/ou Writers personalizados. Essas abstrações são discutidas com mais detalhes no documento de arquitetura .
Solução de problemas, depuração e obtenção de ajuda
Por que as métricas MultiClassConfusionMatrix não correspondem às métricas binarizadas do ConfusionMatrix
Na verdade, são cálculos diferentes. A binarização realiza uma comparação para cada ID de classe de forma independente (ou seja, a previsão para cada classe é comparada separadamente com os limites fornecidos). Neste caso, é possível que duas ou mais classes indiquem que corresponderam à previsão porque o seu valor previsto foi maior que o limite (isto será ainda mais evidente em limites mais baixos). No caso da matriz de confusão multiclasse, ainda existe apenas um valor verdadeiro previsto e ele corresponde ao valor real ou não. O limite só é usado para forçar uma previsão a não corresponder a nenhuma classe se for menor que o limite. Quanto maior o limite, mais difícil será a correspondência da previsão de uma classe binária. Da mesma forma, quanto menor o limite, mais fácil será a correspondência das previsões de uma classe binária. Isso significa que em limites > 0,5 os valores binarizados e os valores da matriz multiclasse estarão mais alinhados e em limites < 0,5 eles estarão mais distantes.
Por exemplo, digamos que temos 10 classes onde a classe 2 foi prevista com uma probabilidade de 0,8, mas a classe real era a classe 1, que tinha uma probabilidade de 0,15. Se você binarizar na classe 1 e usar um limite de 0,1, então a classe 1 será considerada correta (0,15 > 0,1) e será contada como TP. Porém, para o caso multiclasse, a classe 2 será considerada correta (0,8 > 0.1) e como a classe 1 foi a real, esta será contabilizada como FN. Como em limites mais baixos mais valores serão considerados positivos, em geral haverá contagens de TP e FP mais altas para a matriz de confusão binarizada do que para a matriz de confusão multiclasse, e TN e FN igualmente mais baixos.
A seguir está um exemplo de diferenças observadas entre MultiClassConfusionMatrixAtThresholds e as contagens correspondentes da binarização de uma das classes.
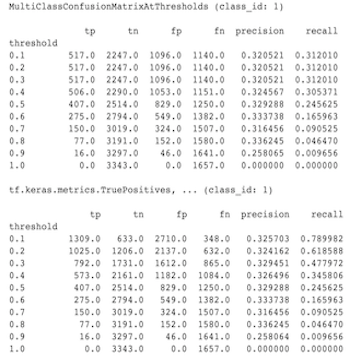
Por que minhas métricas Precision@1 e recall@1 têm o mesmo valor?
Com um valor k superior de 1, precisão e recall são a mesma coisa. A precisão é igual a TP / (TP + FP) e a recuperação é igual a TP / (TP + FN) . A previsão principal é sempre positiva e corresponderá ou não ao rótulo. Em outras palavras, com N exemplos, TP + FP = N . No entanto, se o rótulo não corresponder à previsão principal, isso também implica que uma previsão k não superior foi correspondida e com o k superior definido como 1, todas as previsões 1 não principais serão 0. Isso implica que FN deve ser (N - TP) ou N = TP + FN . O resultado final é precision@1 = TP / N = recall@1 . Observe que isso se aplica apenas quando há um único rótulo por exemplo, não para vários rótulos.
Por que minhas métricas mean_label e mean_prediction são sempre 0,5?
Provavelmente, isso é causado porque as métricas estão configuradas para um problema de classificação binária, mas o modelo está gerando probabilidades para ambas as classes em vez de apenas uma. Isso é comum quando a API de classificação do tensorflow é usada. A solução é escolher a classe na qual você gostaria que as previsões se baseassem e então binarizar nessa classe. Por exemplo:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Como interpretar o MultiLabelConfusionMatrixPlot?
Dado um rótulo específico, o MultiLabelConfusionMatrixPlot (e MultiLabelConfusionMatrix associado) pode ser usado para comparar os resultados de outros rótulos e suas previsões quando o rótulo escolhido era realmente verdadeiro. Por exemplo, digamos que temos três classes bird , plane e superman e estamos classificando imagens para indicar se elas contêm uma ou mais dessas classes. O MultiLabelConfusionMatrix calculará o produto cartesiano de cada classe real em relação a outra classe (chamada de classe prevista). Observe que, embora o emparelhamento seja (actual, predicted) , a classe predicted não implica necessariamente uma previsão positiva, ela apenas representa a coluna prevista na matriz real versus prevista. Por exemplo, digamos que calculamos as seguintes matrizes:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
O MultiLabelConfusionMatrixPlot possui três maneiras de exibir esses dados. Em todos os casos, a forma de ler a tabela é linha por linha, da perspectiva da classe real.
1) Contagem total de previsões
Neste caso, para uma determinada linha (ou seja, classe real), quais foram as contagens de TP + FP para as outras classes. Para as contagens acima, nossa exibição seria a seguinte:
| Pássaro previsto | Avião previsto | Super-homem previsto | |
|---|---|---|---|
| Pássaro real | 6 | 4 | 2 |
| Avião real | 4 | 4 | 4 |
| Super-homem real | 5 | 5 | 4 |
Quando as imagens continham realmente um bird previmos corretamente 6 deles. Ao mesmo tempo, também previmos plane (correta ou incorretamente) 4 vezes e superman (correta ou incorretamente) 2 vezes.
2) Contagem de previsão incorreta
Neste caso, para uma determinada linha (ou seja, classe real), quais foram as contagens de FP para as outras classes. Para as contagens acima, nossa exibição seria a seguinte:
| Pássaro previsto | Avião previsto | Super-homem previsto | |
|---|---|---|---|
| Pássaro real | 0 | 2 | 1 |
| Avião real | 1 | 0 | 3 |
| Super-homem real | 2 | 3 | 0 |
Quando as fotos realmente continham um bird previmos incorretamente plane 2 vezes e superman 1 vez.
3) Contagem de falsos negativos
Neste caso, para uma determinada linha (ou seja, classe real), quais foram as contagens FN para as outras classes. Para as contagens acima, nossa exibição seria a seguinte:
| Pássaro previsto | Avião previsto | Super-homem previsto | |
|---|---|---|---|
| Pássaro real | 2 | 2 | 4 |
| Avião real | 1 | 4 | 3 |
| Super-homem real | 2 | 2 | 5 |
Quando as fotos realmente continham um bird não conseguimos prevê-lo duas vezes. Ao mesmo tempo, falhamos em prever plane 2 vezes e superman 4 vezes.
Por que recebo um erro sobre a chave de previsão não encontrada?
Alguns modelos geram suas previsões na forma de um dicionário. Por exemplo, um estimador TF para problemas de classificação binária gera um dicionário contendo probabilities , class_ids , etc. Na maioria dos casos, o TFMA tem padrões para encontrar nomes de chaves comumente usados, como predictions , probabilities , etc. chaves de saída sob nomes não conhecidos pelo TFMA. Nestes casos, uma configuração prediciton_key deve ser adicionada ao tfma.ModelSpec para identificar o nome da chave sob a qual a saída está armazenada.