
סקירה כללית
TensorFlow Model Analysis (TFMA) היא ספרייה לביצוע הערכת מודלים.
- עבור : מהנדסי למידת מכונה או מדעני נתונים
- מי : רוצה לנתח ולהבין את המודלים של TensorFlow שלהם
- זה : ספרייה עצמאית או רכיב של צינור TFX
- כי : מעריך מודלים על כמויות גדולות של נתונים בצורה מבוזרת על אותם מדדים שהוגדרו בהדרכה. מדדים אלה מושווים על פני פרוסות נתונים, ומוצגים במחברות של Jupyter או Colab.
- בניגוד : כמה כלי בדיקה פנימה של מודלים כמו tensorboard המציעים התבוננות פנימית של מודל
TFMA מבצעת את החישובים שלה בצורה מבוזרת על פני כמויות גדולות של נתונים באמצעות Apache Beam . הסעיפים הבאים מתארים כיצד להגדיר צינור הערכה בסיסי של TFMA. ראה ארכיטקטורה פרטים נוספים על היישום הבסיסי.
אם אתה רק רוצה לקפוץ ולהתחיל, בדוק את מחברת ה-Colab שלנו.
ניתן לצפות בדף זה גם מ- tensorflow.org .
סוגי דגמים נתמכים
TFMA נועד לתמוך במודלים מבוססי tensorflow, אך ניתן להרחיב אותו בקלות לתמיכה גם במסגרות אחרות. מבחינה היסטורית, TFMA דרש יצירת EvalSavedModel כדי להשתמש ב-TFMA, אך הגרסה העדכנית ביותר של TFMA תומכת במספר סוגים של דגמים בהתאם לצרכי המשתמש. יש צורך בהגדרת EvalSavedModel רק אם נעשה שימוש במודל מבוסס tf.estimator ונדרשים מדדי זמן אימון מותאמים אישית.
שים לב שמכיוון ש-TFMA פועל כעת על בסיס מודל ההגשה, TFMA לא יעריך עוד באופן אוטומטי מדדים שנוספו בזמן האימון. היוצא מן הכלל למקרה זה הוא אם נעשה שימוש במודל של keras שכן keras שומר את המדדים המשמשים לצד המודל השמור. עם זאת, אם זו דרישה קשה, ה-TFMA האחרון תואם לאחור כך שעדיין ניתן להפעיל EvalSavedModel בצינור TFMA.
הטבלה הבאה מסכמת את הדגמים הנתמכים כברירת מחדל:
| סוג דגם | מדדי זמן אימון | מדדי פוסט אימון |
|---|---|---|
| TF2 (keras) | Y* | י |
| TF2 (גנרי) | לא | י |
| EvalSavedModel (מעריך) | י | י |
| אין (pd.DataFrame וכו') | לא | י |
- מדדי זמן אימון מתייחסים למדדים שהוגדרו בזמן האימון ונשמרו עם המודל (או TFMA EvalSavedModel או מודל שמור של keras). מדדי פוסט אימון מתייחסים למדדים שנוספו באמצעות
tfma.MetricConfig. - דגמי TF2 גנריים הם מודלים מותאמים אישית שמייצאים חתימות שניתן להשתמש בהן להסקת מסקנות ואינן מבוססות על קרס או על מעריך.
ראה שאלות נפוצות למידע נוסף על אופן ההגדרה וההגדרה של סוגי הדגמים השונים הללו.
הגדרה
לפני הפעלת הערכה, נדרשת כמות קטנה של הגדרה. ראשית, יש להגדיר אובייקט tfma.EvalConfig המספק מפרטים עבור המודל, המדדים והפרוסות שיש להעריך. שנית צריך ליצור tfma.EvalSharedModel שמצביע על המודל (או המודלים) בפועל שישמשו במהלך ההערכה. לאחר הגדרתם, ההערכה מתבצעת על ידי קריאה ל- tfma.run_model_analysis עם מערך נתונים מתאים. לפרטים נוספים, עיין במדריך ההתקנה .
אם פועל בתוך צינור TFX, עיין במדריך TFX כיצד להגדיר את TFMA לפעול כרכיב TFX Evaluator .
דוגמאות
הערכת מודל יחיד
הבא משתמש tfma.run_model_analysis כדי לבצע הערכה על מודל הגשה. להסבר על ההגדרות השונות הדרושות, עיין במדריך ההתקנה .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
להערכה מבוזרת, בנה צינור Apache Beam באמצעות רץ מבוזר. בצינור, השתמש ב- tfma.ExtractEvaluateAndWriteResults להערכה וכדי לכתוב את התוצאות. ניתן לטעון את התוצאות להדמיה באמצעות tfma.load_eval_result .
לְדוּגמָה:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
אימות מודל
כדי לבצע אימות מודל מול מועמד ובסיס, עדכן את התצורה כך שתכלול הגדרת סף והעבר שני מודלים ל- tfma.run_model_analysis .
לְדוּגמָה:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
רְאִיָה
ניתן להמחיש את תוצאות הערכת TFMA במחברת Jupyter באמצעות רכיבי הקצה הכלולים ב-TFMA. לְדוּגמָה:
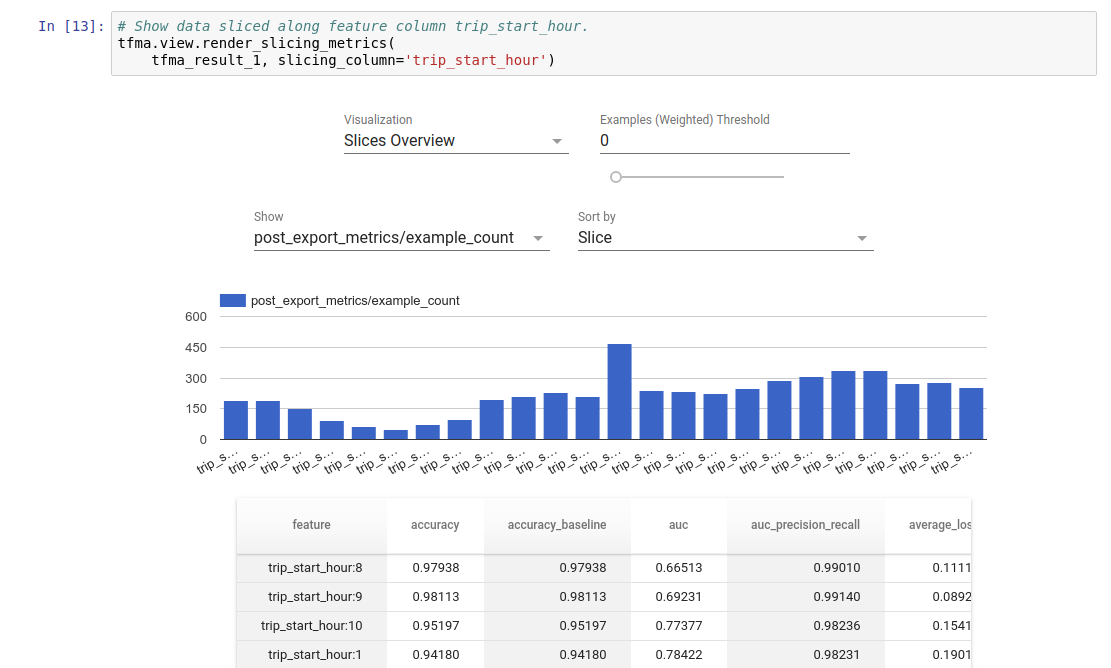 .
.