
Visão geral
TensorFlow Model Analysis (TFMA) é uma biblioteca para realizar avaliação de modelo.
- Para : engenheiros de aprendizado de máquina ou cientistas de dados
- quem : deseja analisar e entender seus modelos do TensorFlow
- é : uma biblioteca independente ou componente de um pipeline TFX
- that : avalia modelos em grandes quantidades de dados de forma distribuída nas mesmas métricas definidas no treinamento. Essas métricas são comparadas em fatias de dados e visualizadas em notebooks Jupyter ou Colab.
- ao contrário : algumas ferramentas de introspecção de modelo, como tensorboard, que oferecem introspecção de modelo
O TFMA realiza seus cálculos de maneira distribuída em grandes quantidades de dados usando o Apache Beam . As seções a seguir descrevem como configurar um pipeline de avaliação TFMA básico. Consulte a arquitetura para obter mais detalhes sobre a implementação subjacente.
Se você quiser apenas começar e começar, confira nosso caderno colab .
Esta página também pode ser visualizada em tensorflow.org .
Tipos de modelos suportados
TFMA foi projetado para suportar modelos baseados em tensorflow, mas pode ser facilmente estendido para suportar outros frameworks também. Historicamente, o TFMA exigia a criação de um EvalSavedModel para usar o TFMA, mas a versão mais recente do TFMA oferece suporte a vários tipos de modelos, dependendo das necessidades do usuário. A configuração de um EvalSavedModel só deve ser necessária se um modelo baseado em tf.estimator for usado e forem necessárias métricas de tempo de treinamento personalizadas.
Observe que, como o TFMA agora é executado com base no modelo de serviço, o TFMA não avaliará mais automaticamente as métricas adicionadas no momento do treinamento. A exceção neste caso é se um modelo keras for usado, pois keras salva as métricas usadas junto com o modelo salvo. No entanto, se este for um requisito difícil, o TFMA mais recente é compatível com versões anteriores, de modo que um EvalSavedModel ainda pode ser executado em um pipeline do TFMA.
A tabela a seguir resume os modelos suportados por padrão:
| Tipo de modelo | Métricas de tempo de treinamento | Métricas pós-treinamento |
|---|---|---|
| TF2 (keras) | S* | S |
| TF2 (genérico) | N / D | S |
| EvalSavedModel (estimador) | S | S |
| Nenhum (pd.DataFrame, etc) | N / D | S |
- As métricas de tempo de treinamento referem-se às métricas definidas no momento do treinamento e salvas com o modelo (TFMA EvalSavedModel ou modelo salvo keras). As métricas pós-treinamento referem-se às métricas adicionadas por meio de
tfma.MetricConfig. - Os modelos genéricos do TF2 são modelos personalizados que exportam assinaturas que podem ser usadas para inferência e não são baseados em keras ou estimador.
Consulte as Perguntas frequentes para obter mais informações sobre como instalar e configurar esses diferentes tipos de modelos.
Configurar
Antes de executar uma avaliação, é necessária uma pequena configuração. Primeiro, deve ser definido um objeto tfma.EvalConfig que forneça especificações para o modelo, métricas e fatias que serão avaliadas. Em segundo lugar, é necessário criar um tfma.EvalSharedModel que aponte para o modelo (ou modelos) real a ser usado durante a avaliação. Uma vez definidos, a avaliação é realizada chamando tfma.run_model_analysis com um conjunto de dados apropriado. Para obter mais detalhes, consulte o guia de configuração .
Se estiver executando em um pipeline do TFX, consulte o guia do TFX para saber como configurar o TFMA para ser executado como um componente do TFX Evaluator .
Exemplos
Avaliação de modelo único
A seguir, usa-se tfma.run_model_analysis para realizar a avaliação em um modelo de serviço. Para obter uma explicação das diferentes configurações necessárias, consulte o guia de configuração .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Para avaliação distribuída, construa um pipeline do Apache Beam usando um executor distribuído. No pipeline, use tfma.ExtractEvaluateAndWriteResults para avaliação e para gravar os resultados. Os resultados podem ser carregados para visualização usando tfma.load_eval_result .
Por exemplo:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Validação de modelo
Para executar a validação do modelo em relação a um candidato e uma linha de base, atualize a configuração para incluir uma configuração de limite e passe dois modelos para tfma.run_model_analysis .
Por exemplo:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Visualização
Os resultados da avaliação do TFMA podem ser visualizados em um notebook Jupyter usando os componentes frontend incluídos no TFMA. Por exemplo:
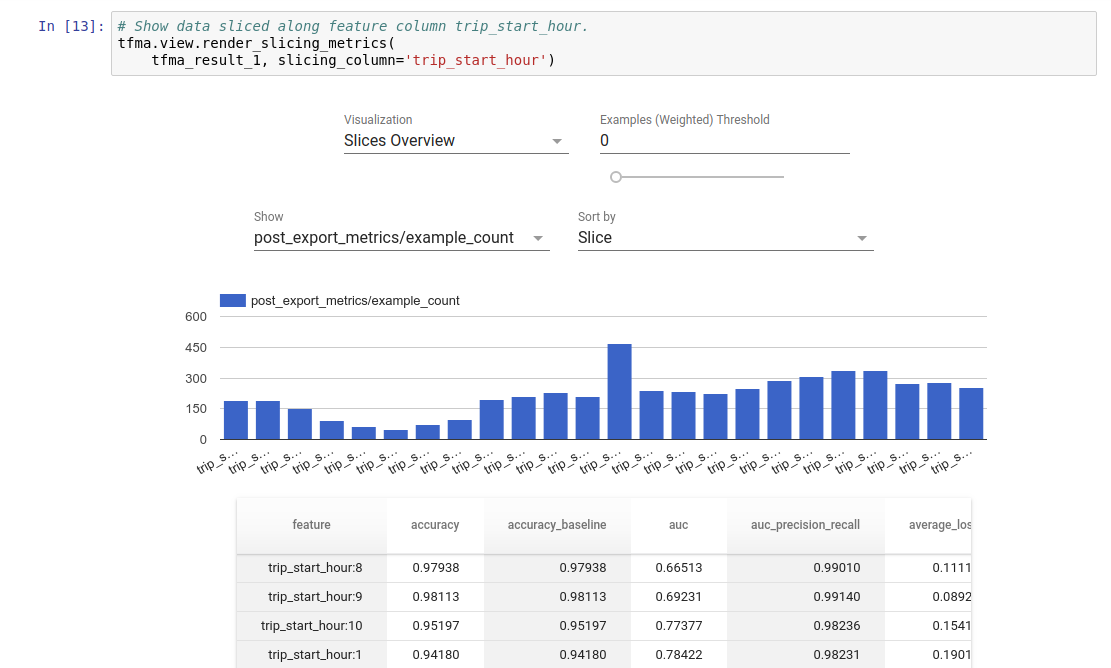 .
.