
টেনসরফ্লো এক্সটেন্ডেডের একটি মূল উপাদানের একটি উদাহরণ
 GitHub-এ উৎস দেখুন
GitHub-এ উৎস দেখুনএই উদাহরণ কোল্যাব নোটবুকটি ব্যাখ্যা করে যে কীভাবে টেনসরফ্লো ডেটা ভ্যালিডেশন (TFDV) আপনার ডেটাসেট তদন্ত ও কল্পনা করতে ব্যবহার করা যেতে পারে। এর মধ্যে রয়েছে বর্ণনামূলক পরিসংখ্যান দেখা, একটি স্কিমা অনুমান করা, অসঙ্গতিগুলি পরীক্ষা করা এবং ঠিক করা এবং আমাদের ডেটাসেটে ড্রিফট এবং স্কু চেক করা। আপনার প্রোডাকশন পাইপলাইনে এটি সময়ের সাথে সাথে কীভাবে পরিবর্তন হতে পারে তা সহ আপনার ডেটাসেটের বৈশিষ্ট্যগুলি বোঝা গুরুত্বপূর্ণ। আপনার ডেটাতে অসামঞ্জস্যতাগুলি সন্ধান করা এবং আপনার প্রশিক্ষণ, মূল্যায়ন এবং পরিবেশন করা ডেটাসেটগুলি সামঞ্জস্যপূর্ণ কিনা তা নিশ্চিত করার জন্য তুলনা করাও গুরুত্বপূর্ণ।
আমরা শিকাগো সিটি দ্বারা প্রকাশিত ট্যাক্সি ট্রিপ ডেটাসেট থেকে ডেটা ব্যবহার করব৷
Google BigQuery- এ ডেটাসেট সম্পর্কে আরও পড়ুন । BigQuery UI- তে সম্পূর্ণ ডেটাসেট অন্বেষণ করুন।
ডেটাসেটের কলামগুলি হল:
| পিকআপ_কমিউনিটি_এরিয়া | ভাড়া | ট্রিপ_শুরু_মাস |
| ট্রিপ_শুরু_ঘণ্টা | ট্রিপ_শুরু_দিন | ট্রিপ_স্টার্ট_টাইমস্ট্যাম্প |
| পিকআপ_অক্ষাংশ | পিকআপ_দ্রাঘিমাংশ | ড্রপঅফ_অক্ষাংশ |
| ড্রপঅফ_দ্রাঘিমাংশ | ট্রিপ_মাইল | পিকআপ_সেনসাস_ট্র্যাক্ট |
| ড্রপঅফ_সেনসাস_ট্র্যাক্ট | শোধের ধরণ | প্রতিষ্ঠান |
| ট্রিপ_সেকেন্ড | ড্রপঅফ_কমিউনিটি_এরিয়া | পরামর্শ |
প্যাকেজ ইনস্টল এবং আমদানি করুন
টেনসরফ্লো ডেটা যাচাইকরণের জন্য প্যাকেজগুলি ইনস্টল করুন।
পিপ আপগ্রেড করুন
স্থানীয়ভাবে চালানোর সময় একটি সিস্টেমে পিপ আপগ্রেড করা এড়াতে, আমরা Colab-এ চলছি কিনা তা নিশ্চিত করুন। স্থানীয় সিস্টেম অবশ্যই আলাদাভাবে আপগ্রেড করা যেতে পারে।
try:
import colab
!pip install --upgrade pip
except:
pass
ডেটা যাচাইকরণ প্যাকেজ ইনস্টল করুন
TensorFlow ডেটা যাচাইকরণ প্যাকেজ এবং নির্ভরতা ইনস্টল করুন, যা কয়েক মিনিট সময় নেয়। আপনি বেমানান নির্ভরতা সংস্করণ সম্পর্কিত সতর্কতা এবং ত্রুটি দেখতে পারেন, যা আপনি পরবর্তী বিভাগে সমাধান করবেন।
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlow আমদানি করুন এবং আপডেট করা প্যাকেজ পুনরায় লোড করুন
পূর্বের ধাপটি Google Colab পরিবেশে ডিফল্ট প্যাকেজ আপডেট করে, তাই নতুন নির্ভরতা সমাধানের জন্য আপনাকে অবশ্যই প্যাকেজ সংস্থানগুলি পুনরায় লোড করতে হবে।
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
এগিয়ে যাওয়ার আগে TensorFlow এর সংস্করণ এবং ডেটা বৈধতা পরীক্ষা করুন।
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
ডেটাসেট লোড করুন
আমরা Google ক্লাউড স্টোরেজ থেকে আমাদের ডেটাসেট ডাউনলোড করব।
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
পরিসংখ্যান গণনা এবং কল্পনা করুন
প্রথমে আমরা আমাদের প্রশিক্ষণ ডেটার পরিসংখ্যান গণনা করতে tfdv.generate_statistics_from_csv ব্যবহার করব। (চটপট সতর্কতা উপেক্ষা করুন)
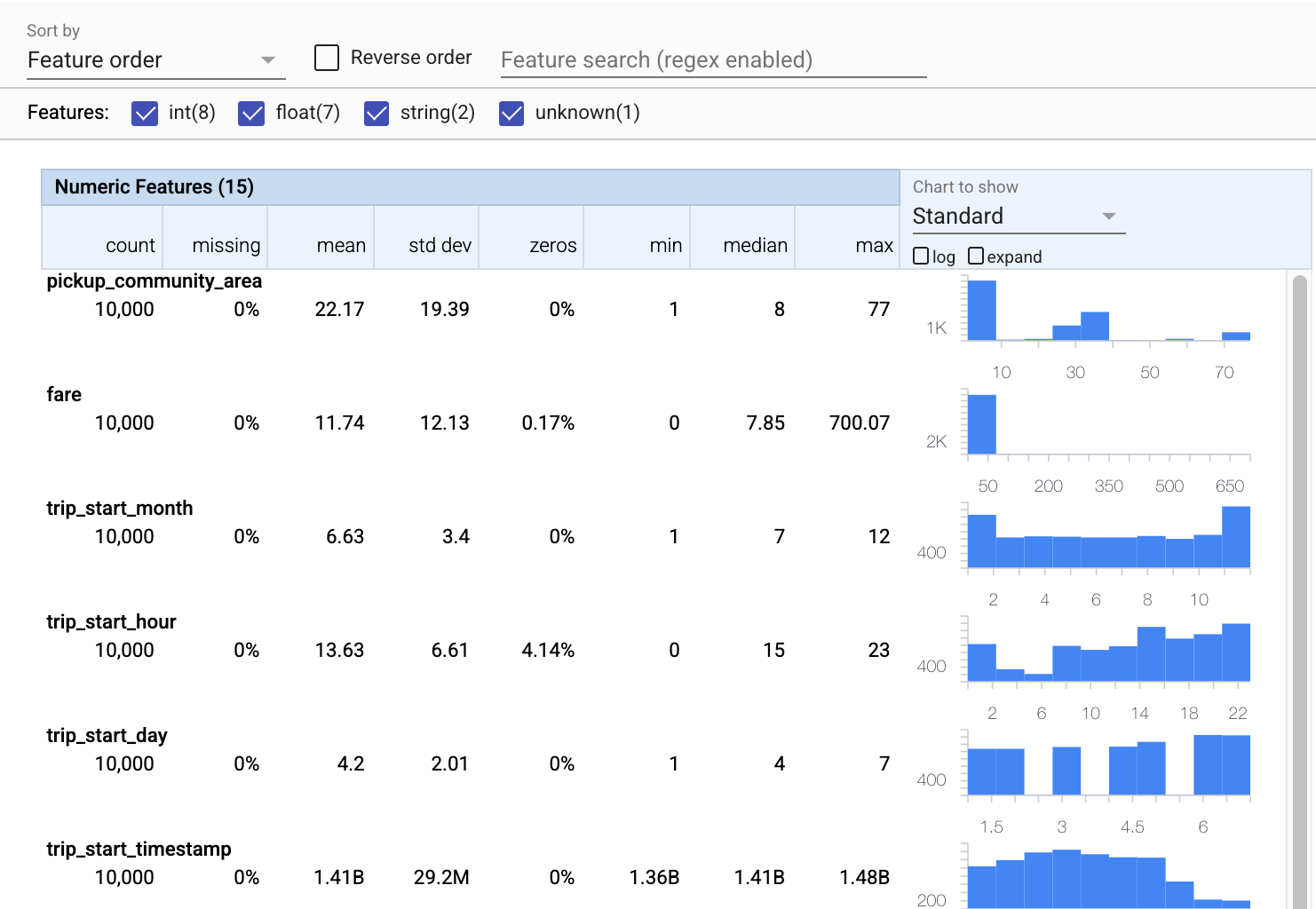
TFDV বর্ণনামূলক পরিসংখ্যান গণনা করতে পারে যা উপস্থিত বৈশিষ্ট্যগুলির পরিপ্রেক্ষিতে ডেটার একটি দ্রুত ওভারভিউ প্রদান করে এবং তাদের মান বিতরণের আকার।
অভ্যন্তরীণভাবে, TFDV Apache Beam-এর ডেটা-সমান্তরাল প্রসেসিং ফ্রেমওয়ার্ক ব্যবহার করে বড় ডেটাসেটের উপর পরিসংখ্যানের গণনার মাপকাঠি। যে অ্যাপ্লিকেশনগুলি TFDV-এর সাথে গভীরভাবে একীভূত হতে চায় (যেমন, ডেটা-জেনারেশন পাইপলাইনের শেষে পরিসংখ্যান জেনারেশন সংযুক্ত করুন), এপিআই পরিসংখ্যান তৈরির জন্য একটি বিম পিটি ট্রান্সফর্মও প্রকাশ করে।
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
এখন tfdv.visualize_statistics ব্যবহার করা যাক, যা আমাদের প্রশিক্ষণের ডেটার একটি সংক্ষিপ্ত ভিজ্যুয়ালাইজেশন তৈরি করতে ফ্যাসেট ব্যবহার করে:
- লক্ষ্য করুন যে সাংখ্যিক বৈশিষ্ট্য এবং ক্যাটাগোরিকাল বৈশিষ্ট্যগুলি আলাদাভাবে ভিজ্যুয়ালাইজ করা হয়েছে, এবং চার্টগুলি প্রতিটি বৈশিষ্ট্যের জন্য বিতরণগুলি প্রদর্শন করে প্রদর্শিত হয়৷
- লক্ষ্য করুন যে অনুপস্থিত বা শূন্য মান সহ বৈশিষ্ট্যগুলি একটি ভিজ্যুয়াল সূচক হিসাবে লাল রঙে একটি শতাংশ প্রদর্শন করে যে সেই বৈশিষ্ট্যগুলির উদাহরণগুলির সাথে সমস্যা থাকতে পারে৷ শতাংশ হল সেই বৈশিষ্ট্যের জন্য অনুপস্থিত বা শূন্য মান আছে এমন উদাহরণের শতাংশ।
- লক্ষ্য করুন যে
pickup_census_tractমান সহ কোন উদাহরণ নেই। এই মাত্রিকতা হ্রাস জন্য একটি সুযোগ! - প্রদর্শন পরিবর্তন করতে চার্টের উপরে "প্রসারিত" ক্লিক করার চেষ্টা করুন
- বালতি পরিসীমা এবং গণনাগুলি প্রদর্শন করতে চার্টে বারগুলির উপর ঘোরাঘুরি করার চেষ্টা করুন৷
- লগ এবং লিনিয়ার স্কেলগুলির মধ্যে স্যুইচ করার চেষ্টা করুন, এবং লক্ষ্য করুন কিভাবে লগ স্কেল
payment_typeবৈশিষ্ট্য সম্পর্কে আরও বিশদ প্রকাশ করে - "দেখার জন্য চার্ট" মেনু থেকে "পরিমাণ" নির্বাচন করার চেষ্টা করুন এবং কোয়ান্টাইল শতাংশ দেখানোর জন্য মার্কারগুলির উপর হোভার করুন
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
একটি স্কিমা অনুমান
এখন আমাদের ডেটার জন্য একটি স্কিমা তৈরি করতে tfdv.infer_schema ব্যবহার করা যাক। একটি স্কিমা ML-এর জন্য প্রাসঙ্গিক ডেটার জন্য সীমাবদ্ধতা সংজ্ঞায়িত করে। উদাহরণ সীমাবদ্ধতার মধ্যে প্রতিটি বৈশিষ্ট্যের ডেটা টাইপ অন্তর্ভুক্ত থাকে, তা সংখ্যাসূচক বা শ্রেণীগত, বা ডেটাতে এর উপস্থিতির ফ্রিকোয়েন্সি। শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য স্কিমা ডোমেনকেও সংজ্ঞায়িত করে - গ্রহণযোগ্য মানগুলির তালিকা। যেহেতু একটি স্কিমা লেখা একটি ক্লান্তিকর কাজ হতে পারে, বিশেষ করে প্রচুর বৈশিষ্ট্য সহ ডেটাসেটের জন্য, TFDV বর্ণনামূলক পরিসংখ্যানের উপর ভিত্তি করে স্কিমার একটি প্রাথমিক সংস্করণ তৈরি করার একটি পদ্ধতি প্রদান করে।
সঠিক স্কিমা পাওয়া গুরুত্বপূর্ণ কারণ আমাদের বাকি প্রোডাকশন পাইপলাইনটি TFDV যে স্কিমার তৈরি করে তা সঠিক হওয়ার জন্য নির্ভর করবে। স্কিমা ডেটার জন্য ডকুমেন্টেশনও সরবরাহ করে এবং একই ডেটাতে বিভিন্ন বিকাশকারীরা কাজ করলে এটি কার্যকর। আসুন অনুমানকৃত স্কিমা প্রদর্শন করতে tfdv.display_schema ব্যবহার করি যাতে আমরা এটি পর্যালোচনা করতে পারি।
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
ত্রুটির জন্য মূল্যায়ন ডেটা পরীক্ষা করুন
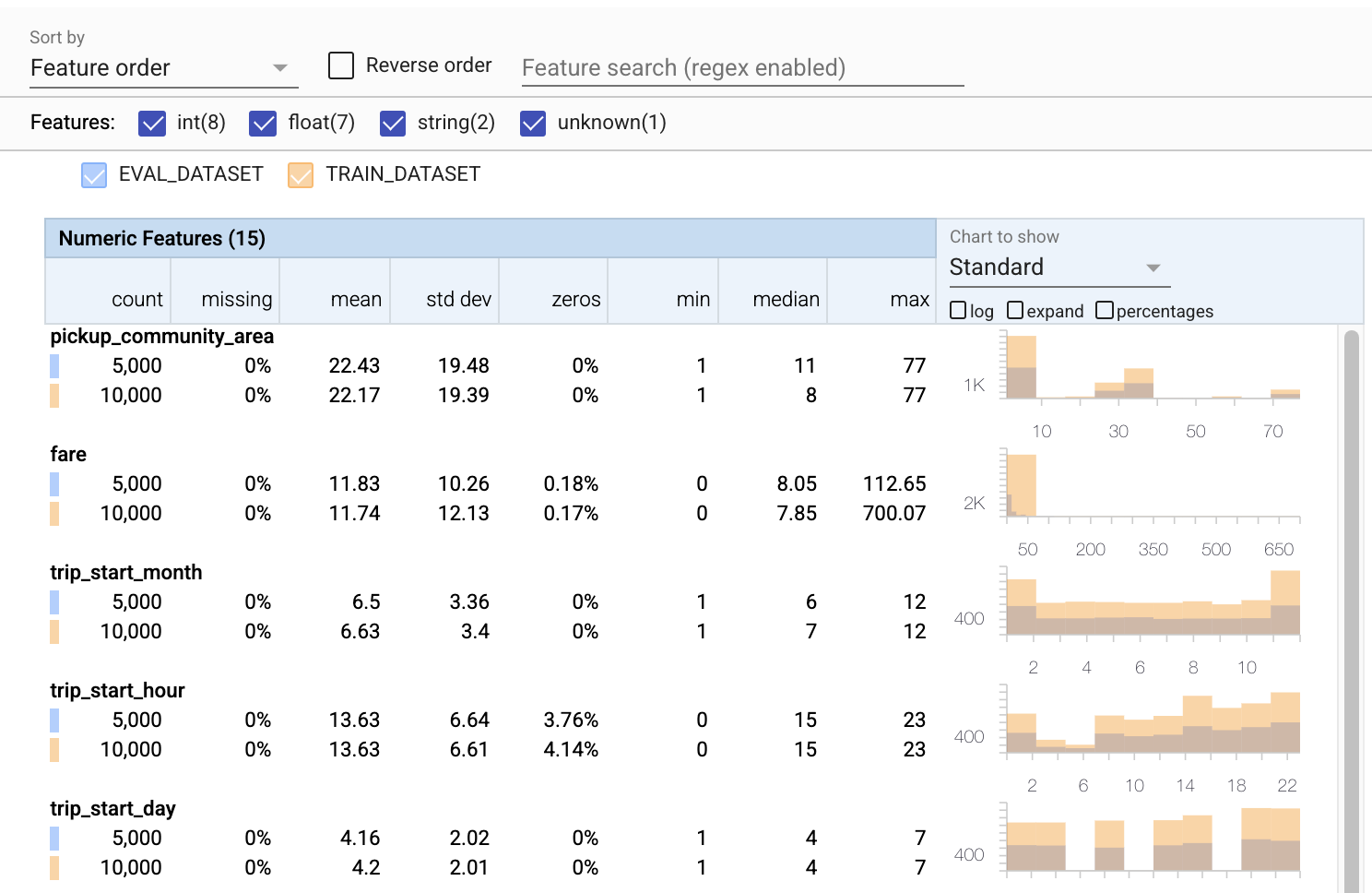
এখন পর্যন্ত আমরা শুধুমাত্র প্রশিক্ষণের তথ্য দেখছি। এটি গুরুত্বপূর্ণ যে আমাদের মূল্যায়নের ডেটা আমাদের প্রশিক্ষণের ডেটার সাথে সামঞ্জস্যপূর্ণ, যার মধ্যে এটি একই স্কিমা ব্যবহার করে। এটিও গুরুত্বপূর্ণ যে মূল্যায়ন ডেটাতে আমাদের প্রশিক্ষণের ডেটার মতো আমাদের সংখ্যাসূচক বৈশিষ্ট্যগুলির জন্য মোটামুটি একই পরিসরের মানের উদাহরণগুলি অন্তর্ভুক্ত করা হয়েছে, যাতে মূল্যায়নের সময় ক্ষতির পৃষ্ঠের আমাদের কভারেজ প্রশিক্ষণের সময় মোটামুটি একই রকম হয়৷ শ্রেণীগত বৈশিষ্ট্যের ক্ষেত্রেও একই কথা প্রযোজ্য। অন্যথায়, আমাদের প্রশিক্ষণের সমস্যা থাকতে পারে যেগুলি মূল্যায়নের সময় চিহ্নিত করা হয়নি, কারণ আমরা আমাদের ক্ষতির পৃষ্ঠের অংশ মূল্যায়ন করিনি।
- লক্ষ্য করুন যে প্রতিটি বৈশিষ্ট্যে এখন প্রশিক্ষণ এবং মূল্যায়ন ডেটাসেট উভয়ের পরিসংখ্যান অন্তর্ভুক্ত রয়েছে।
- লক্ষ্য করুন যে চার্টে এখন প্রশিক্ষণ এবং মূল্যায়ন ডেটাসেট উভয়ই ওভারলেড রয়েছে, এটি তাদের তুলনা করা সহজ করে তোলে।
- লক্ষ্য করুন যে চার্টে এখন শতাংশ দৃশ্য অন্তর্ভুক্ত রয়েছে, যা লগ বা ডিফল্ট রৈখিক স্কেলগুলির সাথে একত্রিত করা যেতে পারে।
- লক্ষ্য করুন যে প্রশিক্ষণ বনাম মূল্যায়ন ডেটাসেটের জন্য
trip_milesএর গড় এবং মাঝামাঝি আলাদা। যে সমস্যা সৃষ্টি করবে? - বাহ, প্রশিক্ষণ বনাম মূল্যায়ন ডেটাসেটের জন্য সর্বোচ্চ
tipsখুব আলাদা। যে সমস্যা সৃষ্টি করবে? - সংখ্যাসূচক বৈশিষ্ট্য চার্টে প্রসারিত ক্লিক করুন এবং লগ স্কেল নির্বাচন করুন।
trip_secondsবৈশিষ্ট্যটি পর্যালোচনা করুন এবং সর্বাধিক পার্থক্য লক্ষ্য করুন। মূল্যায়ন কি ক্ষতির পৃষ্ঠের অংশগুলি মিস করবে?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
মূল্যায়ন অসঙ্গতি জন্য পরীক্ষা করুন
আমাদের মূল্যায়ন ডেটাসেট কি আমাদের প্রশিক্ষণ ডেটাসেটের স্কিমার সাথে মেলে? এটি শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য বিশেষভাবে গুরুত্বপূর্ণ, যেখানে আমরা গ্রহণযোগ্য মানগুলির পরিসর চিহ্নিত করতে চাই৷
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
স্কিমায় মূল্যায়নের অসঙ্গতিগুলি ঠিক করুন
উফ! দেখে মনে হচ্ছে আমাদের মূল্যায়ন ডেটাতে company জন্য কিছু নতুন মান রয়েছে, যা আমাদের প্রশিক্ষণ ডেটাতে ছিল না। payment_type জন্য আমাদের কাছে একটি নতুন মান রয়েছে। এগুলিকে অসঙ্গতি হিসাবে বিবেচনা করা উচিত, তবে আমরা সেগুলি সম্পর্কে কী সিদ্ধান্ত নেব তা নির্ভর করে ডেটা সম্পর্কে আমাদের ডোমেন জ্ঞানের উপর৷ যদি একটি অসঙ্গতি সত্যিই একটি ডেটা ত্রুটি নির্দেশ করে, তাহলে অন্তর্নিহিত ডেটা ঠিক করা উচিত। অন্যথায়, আমরা ইভাল ডেটাসেটে মান অন্তর্ভুক্ত করার জন্য স্কিমা আপডেট করতে পারি।
আমরা যদি আমাদের মূল্যায়ন ডেটাসেট পরিবর্তন না করি তবে আমরা সবকিছু ঠিক করতে পারব না, তবে আমরা যে স্কিমায় আমরা স্বাচ্ছন্দ্য বোধ করি সেগুলি ঠিক করতে পারি৷ এর মধ্যে রয়েছে নির্দিষ্ট বৈশিষ্ট্যগুলির জন্য কী এবং কী অসঙ্গতি নয় সে সম্পর্কে আমাদের দৃষ্টিভঙ্গি শিথিল করা, সেইসাথে শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য অনুপস্থিত মানগুলি অন্তর্ভুক্ত করতে আমাদের স্কিমা আপডেট করা। TFDV আমাদের কী ঠিক করতে হবে তা আবিষ্কার করতে সক্ষম করেছে।
আসুন এখনই সেই সংশোধনগুলি করি, এবং তারপরে আরও একবার পর্যালোচনা করি৷
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
আরে ওটা দেখো! আমরা যাচাই করেছি যে প্রশিক্ষণ এবং মূল্যায়ন ডেটা এখন সামঞ্জস্যপূর্ণ! ধন্যবাদ TFDV ;)
স্কিমা পরিবেশ
আমরা এই উদাহরণের জন্য একটি 'সার্ভিং' ডেটাসেটও বিভক্ত করেছি, তাই আমাদের এটিও পরীক্ষা করা উচিত। ডিফল্টরূপে একটি পাইপলাইনের সমস্ত ডেটাসেট একই স্কিমা ব্যবহার করা উচিত, তবে প্রায়শই ব্যতিক্রম রয়েছে। উদাহরণস্বরূপ, তত্ত্বাবধানে শেখার ক্ষেত্রে আমাদের ডেটাসেটে লেবেলগুলি অন্তর্ভুক্ত করতে হবে, কিন্তু যখন আমরা অনুমানের জন্য মডেলটি পরিবেশন করি তখন লেবেলগুলি অন্তর্ভুক্ত করা হবে না। কিছু ক্ষেত্রে সামান্য স্কিমার তারতম্য প্রবর্তন করা প্রয়োজন।
এই ধরনের প্রয়োজনীয়তা প্রকাশ করতে পরিবেশ ব্যবহার করা যেতে পারে। বিশেষ করে, স্কিমার বৈশিষ্ট্যগুলি default_environment , in_environment এবং not_in_environment ব্যবহার করে পরিবেশের একটি সেটের সাথে যুক্ত হতে পারে।
উদাহরণস্বরূপ, এই ডেটাসেটে tips বৈশিষ্ট্যটি প্রশিক্ষণের জন্য লেবেল হিসাবে অন্তর্ভুক্ত করা হয়েছে, তবে পরিবেশন করা ডেটাতে এটি অনুপস্থিত। নির্দিষ্ট পরিবেশ ছাড়া, এটি একটি অসঙ্গতি হিসাবে প্রদর্শিত হবে।
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
আমরা নীচের tips বৈশিষ্ট্য মোকাবেলা করব. আমাদের ট্রিপ সেকেন্ডে একটি INT মানও রয়েছে, যেখানে আমাদের স্কিমা একটি ফ্লোট আশা করেছিল৷ সেই পার্থক্য সম্পর্কে আমাদের সচেতন করে, TFDV প্রশিক্ষণ এবং পরিবেশনের জন্য ডেটা তৈরি করার উপায়ে অসঙ্গতিগুলি উন্মোচন করতে সহায়তা করে। মডেলের কর্মক্ষমতা ক্ষতিগ্রস্থ না হওয়া পর্যন্ত, কখনও কখনও বিপর্যয়মূলকভাবে এই ধরনের সমস্যা সম্পর্কে অজানা থাকা খুব সহজ। এটি একটি তাৎপর্যপূর্ণ সমস্যা হতে পারে বা নাও হতে পারে, তবে যেকোনো ক্ষেত্রেই এটি আরও তদন্তের কারণ হওয়া উচিত।
এই ক্ষেত্রে, আমরা নিরাপদে INT মানগুলিকে FLOAT-এ রূপান্তর করতে পারি, তাই আমরা TFDV-কে বলতে চাই আমাদের স্কিমা ব্যবহার করে ধরন অনুমান করতে৷ এখন এটা করা যাক.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
এখন আমাদের কাছে শুধুমাত্র tips বৈশিষ্ট্য (যা আমাদের লেবেল) একটি অসঙ্গতি ('কলাম ড্রপড') হিসাবে দেখানো হয়েছে। অবশ্যই আমরা আমাদের পরিবেশন করা ডেটাতে লেবেল থাকার আশা করি না, তাই আসুন TFDV কে এটি উপেক্ষা করার জন্য বলি।
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
প্রবাহ এবং তির্যক জন্য পরীক্ষা করুন
একটি ডেটাসেট স্কিমাতে সেট করা প্রত্যাশার সাথে সামঞ্জস্যপূর্ণ কিনা তা পরীক্ষা করার পাশাপাশি, TFDV ড্রিফট এবং স্কু সনাক্ত করার জন্য কার্যকারিতাও প্রদান করে। TFDV স্কিমাতে নির্দিষ্ট করা ড্রিফট/স্কু তুলনাকারীদের উপর ভিত্তি করে বিভিন্ন ডেটাসেটের পরিসংখ্যান তুলনা করে এই পরীক্ষাটি করে।
প্রবাহ
ড্রিফ্ট সনাক্তকরণ শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য এবং ডেটার পরপর স্প্যানগুলির মধ্যে (যেমন, স্প্যান N এবং স্প্যান N+1 এর মধ্যে), যেমন প্রশিক্ষণের বিভিন্ন দিনের ডেটার মধ্যে সমর্থিত। আমরা L-ইনফিনিটি দূরত্বের পরিপ্রেক্ষিতে ড্রিফ্ট প্রকাশ করি এবং আপনি থ্রেশহোল্ড দূরত্ব সেট করতে পারেন যাতে ড্রিফট গ্রহণযোগ্য থেকে বেশি হলে আপনি সতর্কতা পান। সঠিক দূরত্ব সেট করা সাধারণত একটি পুনরাবৃত্তিমূলক প্রক্রিয়া যার জন্য ডোমেন জ্ঞান এবং পরীক্ষা-নিরীক্ষার প্রয়োজন হয়।
তির্যক
TFDV আপনার ডেটাতে তিনটি ভিন্ন ধরণের স্কু সনাক্ত করতে পারে - স্কিমা স্কু, ফিচার স্ক্যু এবং ডিস্ট্রিবিউশন স্ক্যু।
স্কিমা স্কু
স্কিমা স্কিউ ঘটে যখন প্রশিক্ষণ এবং পরিবেশন ডেটা একই স্কিমার সাথে সামঞ্জস্যপূর্ণ হয় না। প্রশিক্ষণ এবং পরিবেশন ডেটা উভয়ই একই স্কিমা মেনে চলবে বলে আশা করা হচ্ছে। উভয়ের মধ্যে যেকোন প্রত্যাশিত বিচ্যুতি (যেমন লেবেল বৈশিষ্ট্যটি শুধুমাত্র প্রশিক্ষণের ডেটাতে উপস্থিত কিন্তু পরিবেশন করার সময় নয়) স্কিমার পরিবেশ ক্ষেত্রের মাধ্যমে নির্দিষ্ট করা উচিত।
ফিচার Skew
ফিচার স্ক্যু তখন ঘটে যখন একটি মডেল যে বৈশিষ্ট্যের মানগুলিকে প্রশিক্ষণ দেয় তা পরিবেশন করার সময় যে বৈশিষ্ট্যের মানগুলি দেখে তার থেকে আলাদা। উদাহরণস্বরূপ, এটি ঘটতে পারে যখন:
- একটি ডেটা উত্স যা কিছু বৈশিষ্ট্য মান প্রদান করে তা প্রশিক্ষণ এবং পরিবেশন সময়ের মধ্যে পরিবর্তন করা হয়
- প্রশিক্ষণ এবং পরিবেশনের মধ্যে বৈশিষ্ট্য তৈরি করার জন্য ভিন্ন যুক্তি রয়েছে। উদাহরণস্বরূপ, যদি আপনি শুধুমাত্র দুটি কোড পাথের একটিতে কিছু রূপান্তর প্রয়োগ করেন।
ডিস্ট্রিবিউশন স্কু
বিতরণ তির্যক ঘটে যখন প্রশিক্ষণ ডেটাসেটের বিতরণ পরিবেশন ডেটাসেটের বিতরণ থেকে উল্লেখযোগ্যভাবে আলাদা হয়। ডিস্ট্রিবিউশন স্কুয়ের মূল কারণগুলির মধ্যে একটি হল প্রশিক্ষণ ডেটাসেট তৈরি করতে বিভিন্ন কোড বা বিভিন্ন ডেটা উত্স ব্যবহার করা। আরেকটি কারণ হল একটি ত্রুটিপূর্ণ স্যাম্পলিং মেকানিজম যা প্রশিক্ষণের জন্য পরিবেশনকারী ডেটার একটি অ-প্রতিনিধিত্বমূলক উপ-নমুনা বেছে নেয়।
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
এই উদাহরণে আমরা কিছু ড্রিফ্ট দেখতে পাচ্ছি, তবে এটি আমরা যে থ্রেশহোল্ড সেট করেছি তার নীচে।
স্কিমা হিমায়িত করুন
এখন যেহেতু স্কিমাটি পর্যালোচনা করা হয়েছে এবং কিউরেট করা হয়েছে, আমরা এটির "হিমায়িত" অবস্থা প্রতিফলিত করতে একটি ফাইলে সংরক্ষণ করব।
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
কখন TFDV ব্যবহার করবেন
TFDV কে শুধুমাত্র আপনার প্রশিক্ষণ পাইপলাইনের শুরুতে প্রয়োগ করা বলে মনে করা সহজ, যেমনটি আমরা এখানে করেছি, কিন্তু আসলে এর অনেক ব্যবহার রয়েছে। এখানে আরো কিছু আছে:
- আমরা হঠাৎ খারাপ বৈশিষ্ট্যগুলি পেতে শুরু করিনি তা নিশ্চিত করতে অনুমানের জন্য নতুন ডেটা যাচাই করা হচ্ছে
- আমাদের মডেল সিদ্ধান্ত পৃষ্ঠের সেই অংশে প্রশিক্ষিত হয়েছে তা নিশ্চিত করতে অনুমানের জন্য নতুন ডেটা যাচাই করা হচ্ছে
- আমরা কিছু ভুল করিনি তা নিশ্চিত করার জন্য আমরা এটিকে রূপান্তরিত করার পরে এবং বৈশিষ্ট্য ইঞ্জিনিয়ারিং (সম্ভবত TensorFlow Transform ব্যবহার করে) করার পরে আমাদের ডেটা যাচাই করা