
Um exemplo de um componente-chave do TensorFlow Extended
 Ver fonte no GitHub
Ver fonte no GitHubEste exemplo de notebook colab ilustra como o TensorFlow Data Validation (TFDV) pode ser usado para investigar e visualizar seu conjunto de dados. Isso inclui analisar estatísticas descritivas, inferir um esquema, verificar e corrigir anomalias e verificar desvios e desvios em nosso conjunto de dados. É importante entender as características do seu conjunto de dados, incluindo como ele pode mudar ao longo do tempo em seu pipeline de produção. Também é importante procurar anomalias em seus dados e comparar seus conjuntos de dados de treinamento, avaliação e veiculação para garantir que sejam consistentes.
Usaremos dados do conjunto de dados Taxi Trips divulgado pela cidade de Chicago.
Leia mais sobre o conjunto de dados no Google BigQuery . Explore o conjunto de dados completo na IU do BigQuery .
As colunas no conjunto de dados são:
| pickup_community_area | tarifa | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | tipo de pagamento | companhia |
| viagem_segundos | dropoff_community_area | pontas |
Instalar e importar pacotes
Instale os pacotes para validação de dados do TensorFlow.
Pip de atualização
Para evitar atualizar o Pip em um sistema ao executar localmente, verifique se estamos executando no Colab. É claro que os sistemas locais podem ser atualizados separadamente.
try:
import colab
!pip install --upgrade pip
except:
pass
Instalar pacotes de validação de dados
Instale os pacotes e dependências do TensorFlow Data Validation, o que leva alguns minutos. Você pode ver avisos e erros relacionados a versões de dependência incompatíveis, que você resolverá na próxima seção.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Importe o TensorFlow e recarregue os pacotes atualizados
A etapa anterior atualiza os pacotes padrão no ambiente do Gooogle Colab, portanto, você deve recarregar os recursos do pacote para resolver as novas dependências.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Verifique as versões do TensorFlow e a validação de dados antes de continuar.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Carregar o conjunto de dados
Faremos o download do nosso conjunto de dados do Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Calcular e visualizar estatísticas
Primeiro, usaremos tfdv.generate_statistics_from_csv para calcular estatísticas para nossos dados de treinamento. (ignore os avisos rápidos)
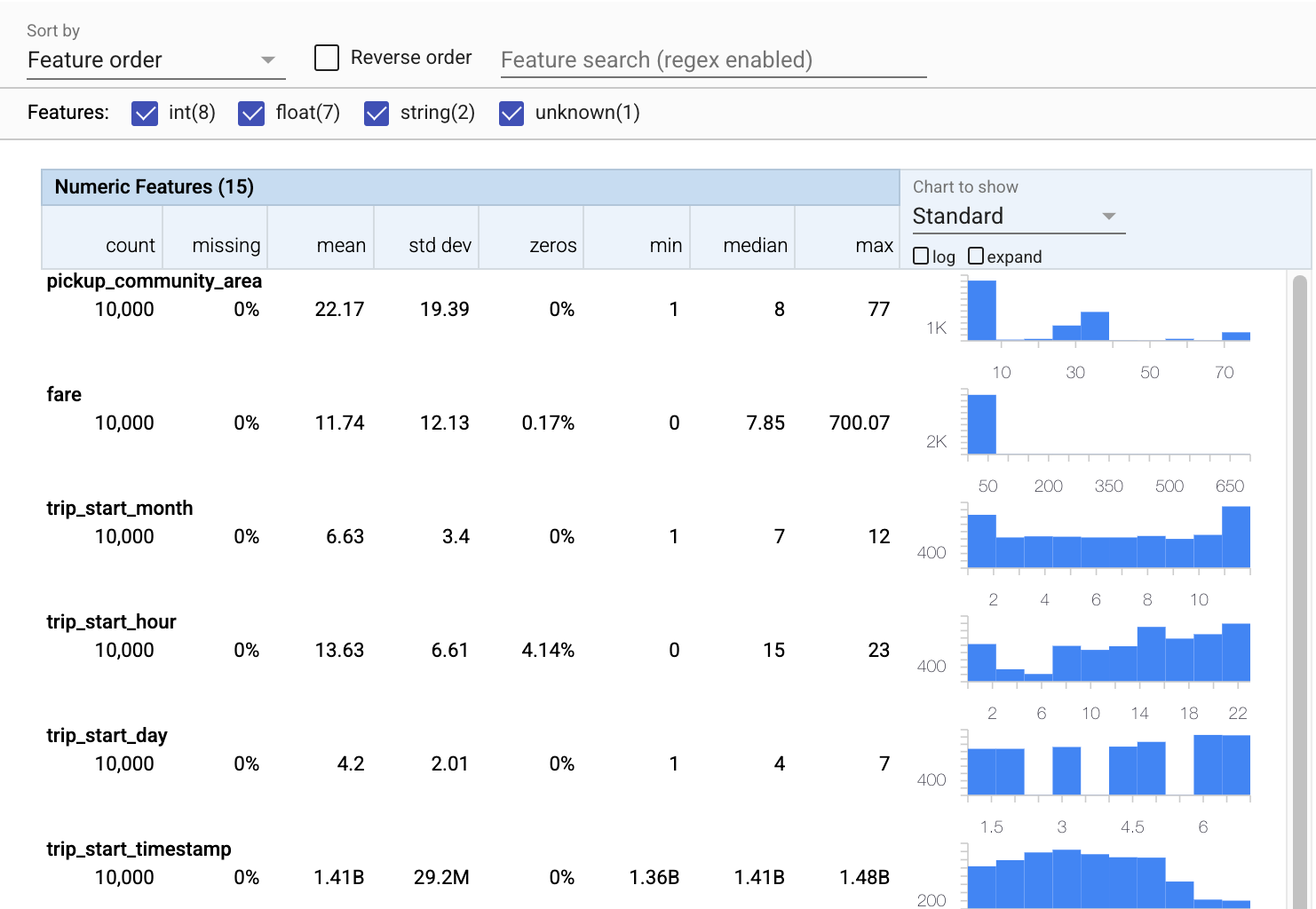
O TFDV pode computar estatísticas descritivas que fornecem uma visão geral rápida dos dados em termos das características que estão presentes e as formas de suas distribuições de valor.
Internamente, o TFDV usa a estrutura de processamento paralelo de dados do Apache Beam para dimensionar o cálculo de estatísticas em grandes conjuntos de dados. Para aplicativos que desejam se integrar mais profundamente com o TFDV (por exemplo, anexar geração de estatísticas no final de um pipeline de geração de dados), a API também expõe um Beam PTransform para geração de estatísticas.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
Agora vamos usar tfdv.visualize_statistics , que usa Facets para criar uma visualização sucinta de nossos dados de treinamento:
- Observe que os recursos numéricos e os recursos categóricos são visualizados separadamente e que os gráficos são exibidos mostrando as distribuições de cada recurso.
- Observe que os recursos com valores ausentes ou zero exibem uma porcentagem em vermelho como um indicador visual de que pode haver problemas com exemplos nesses recursos. A porcentagem é a porcentagem de exemplos que têm valores ausentes ou zero para esse recurso.
- Observe que não há exemplos com valores para
pickup_census_tract. Esta é uma oportunidade de redução de dimensionalidade! - Tente clicar em "expandir" acima dos gráficos para alterar a exibição
- Tente passar o mouse sobre as barras nos gráficos para exibir os intervalos e as contagens dos buckets
- Tente alternar entre as escalas de log e linear e observe como a escala de log revela muito mais detalhes sobre o recurso categórico
payment_type - Tente selecionar "quantis" no menu "Gráfico para mostrar" e passe o mouse sobre os marcadores para mostrar as porcentagens de quantis
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Inferir um esquema
Agora vamos usar tfdv.infer_schema para criar um esquema para nossos dados. Um esquema define restrições para os dados relevantes para ML. As restrições de exemplo incluem o tipo de dados de cada recurso, seja numérico ou categórico, ou a frequência de sua presença nos dados. Para recursos categóricos, o esquema também define o domínio - a lista de valores aceitáveis. Como escrever um esquema pode ser uma tarefa tediosa, especialmente para conjuntos de dados com muitos recursos, o TFDV fornece um método para gerar uma versão inicial do esquema com base nas estatísticas descritivas.
Acertar o esquema é importante porque o resto do nosso pipeline de produção dependerá do esquema que o TFDV gera para estar correto. O esquema também fornece documentação para os dados e, portanto, é útil quando diferentes desenvolvedores trabalham nos mesmos dados. Vamos usar tfdv.display_schema para exibir o esquema inferido para que possamos revisá-lo.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Verifique os dados de avaliação quanto a erros
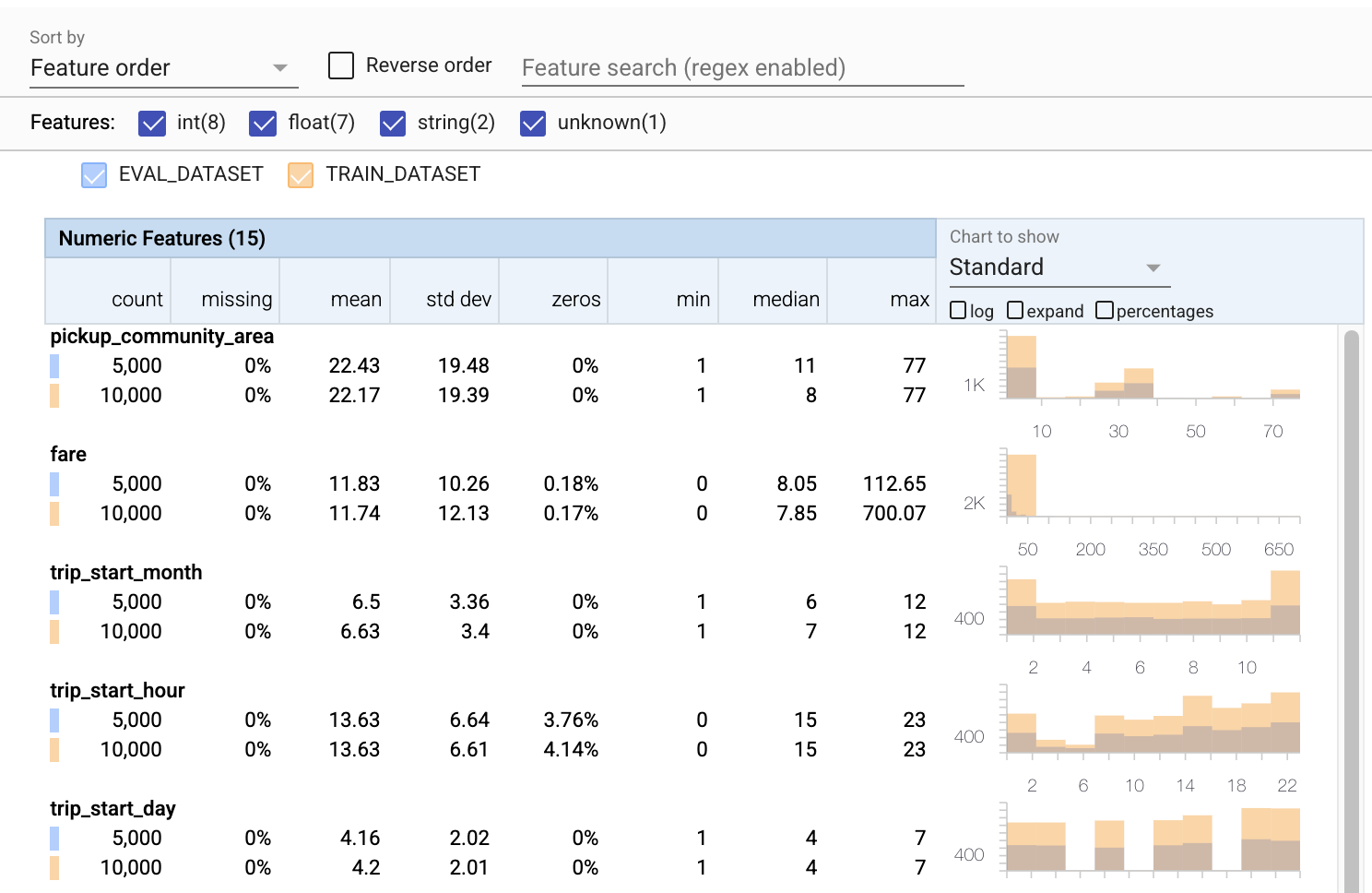
Até agora, analisamos apenas os dados de treinamento. É importante que nossos dados de avaliação sejam consistentes com nossos dados de treinamento, inclusive que usem o mesmo esquema. Também é importante que os dados de avaliação incluam exemplos de aproximadamente os mesmos intervalos de valores para nossos recursos numéricos que nossos dados de treinamento, para que nossa cobertura da superfície de perda durante a avaliação seja aproximadamente a mesma que durante o treinamento. O mesmo vale para características categóricas. Caso contrário, podemos ter problemas de treinamento que não são identificados durante a avaliação, pois não avaliamos parte de nossa superfície de perda.
- Observe que cada recurso agora inclui estatísticas para os conjuntos de dados de treinamento e avaliação.
- Observe que os gráficos agora têm os conjuntos de dados de treinamento e avaliação sobrepostos, facilitando a comparação.
- Observe que os gráficos agora incluem uma visualização de porcentagens, que pode ser combinada com o log ou as escalas lineares padrão.
- Observe que a média e a mediana para
trip_milessão diferentes para os conjuntos de dados de treinamento e de avaliação. Isso causará problemas? - Uau, as
tipsmáximas são muito diferentes para os conjuntos de dados de treinamento e de avaliação. Isso causará problemas? - Clique em expandir no gráfico de recursos numéricos e selecione a escala de log. Revise o recurso
trip_secondse observe a diferença no max. A avaliação perderá partes da superfície de perda?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Verifique se há anomalias de avaliação
Nosso conjunto de dados de avaliação corresponde ao esquema do nosso conjunto de dados de treinamento? Isso é especialmente importante para recursos categóricos, onde queremos identificar o intervalo de valores aceitáveis.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Corrigir anomalias de avaliação no esquema
Ops! Parece que temos alguns novos valores para company em nossos dados de avaliação, que não tínhamos em nossos dados de treinamento. Também temos um novo valor para payment_type . Essas devem ser consideradas anomalias, mas o que decidimos fazer sobre elas depende do nosso conhecimento de domínio dos dados. Se uma anomalia realmente indicar um erro de dados, os dados subjacentes devem ser corrigidos. Caso contrário, podemos simplesmente atualizar o esquema para incluir os valores no conjunto de dados eval.
A menos que alteremos nosso conjunto de dados de avaliação, não podemos corrigir tudo, mas podemos corrigir coisas no esquema que aceitamos à vontade. Isso inclui relaxar nossa visão do que é e o que não é uma anomalia para recursos específicos, bem como atualizar nosso esquema para incluir valores ausentes para recursos categóricos. O TFDV nos permitiu descobrir o que precisamos consertar.
Vamos fazer essas correções agora e depois revisar mais uma vez.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Ei, olha isso! Verificamos que os dados de treinamento e avaliação agora são consistentes! Obrigado TFDV ;)
Ambientes de esquema
Também dividimos um conjunto de dados 'de veiculação' para este exemplo, portanto, devemos verificar isso também. Por padrão, todos os conjuntos de dados em um pipeline devem usar o mesmo esquema, mas geralmente há exceções. Por exemplo, no aprendizado supervisionado, precisamos incluir rótulos em nosso conjunto de dados, mas quando veiculamos o modelo para inferência, os rótulos não serão incluídos. Em alguns casos, é necessário introduzir pequenas variações de esquema.
Os ambientes podem ser usados para expressar tais requisitos. Em particular, os recursos no esquema podem ser associados a um conjunto de ambientes usando default_environment , in_environment e not_in_environment .
Por exemplo, neste conjunto de dados, o recurso de tips está incluído como rótulo para treinamento, mas está ausente nos dados de veiculação. Sem ambiente especificado, ele aparecerá como uma anomalia.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Vamos lidar com o recurso de tips abaixo. Também temos um valor INT em nossos segundos de viagem, onde nosso esquema esperava um FLOAT. Ao nos conscientizar dessa diferença, o TFDV ajuda a descobrir inconsistências na forma como os dados são gerados para treinamento e atendimento. É muito fácil não ter conhecimento de problemas como esse até que o desempenho do modelo sofra, às vezes catastroficamente. Pode ou não ser um problema significativo, mas em qualquer caso, isso deve ser motivo para uma investigação mais aprofundada.
Nesse caso, podemos converter com segurança valores INT em FLOATs, então queremos dizer ao TFDV para usar nosso esquema para inferir o tipo. Vamos fazer isso agora.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Agora temos apenas o recurso de tips (que é nosso rótulo) aparecendo como uma anomalia ('Coluna descartada'). É claro que não esperamos ter rótulos em nossos dados de veiculação, então vamos dizer ao TFDV para ignorar isso.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Verifique se há desvio e inclinação
Além de verificar se um conjunto de dados está de acordo com as expectativas definidas no esquema, o TFDV também fornece funcionalidades para detectar desvios e desvios. O TFDV executa essa verificação comparando as estatísticas dos diferentes conjuntos de dados com base nos comparadores de desvio/inclinação especificados no esquema.
Deriva
A detecção de desvio é compatível com recursos categóricos e entre intervalos consecutivos de dados (ou seja, entre intervalo N e intervalo N+1), como entre diferentes dias de dados de treinamento. Expressamos o desvio em termos de distância L-infinito e você pode definir a distância limite para receber avisos quando o desvio for maior do que o aceitável. Definir a distância correta é tipicamente um processo iterativo que requer conhecimento de domínio e experimentação.
Inclinar
O TFDV pode detectar três tipos diferentes de desvio em seus dados - desvio de esquema, desvio de recurso e desvio de distribuição.
Inclinação do esquema
A distorção do esquema ocorre quando os dados de treinamento e veiculação não estão em conformidade com o mesmo esquema. Espera-se que os dados de treinamento e de serviço sigam o mesmo esquema. Quaisquer desvios esperados entre os dois (como o recurso de rótulo estar presente apenas nos dados de treinamento, mas não na veiculação) devem ser especificados por meio do campo de ambientes no esquema.
Inclinação do recurso
A distorção de recurso ocorre quando os valores de recurso nos quais um modelo treina são diferentes dos valores de recurso que ele vê no momento da exibição. Por exemplo, isso pode acontecer quando:
- Uma fonte de dados que fornece alguns valores de recurso é modificada entre o treinamento e o tempo de veiculação
- Há uma lógica diferente para gerar recursos entre treinamento e serviço. Por exemplo, se você aplicar alguma transformação apenas em um dos dois caminhos de código.
Distorção de distribuição
A distorção de distribuição ocorre quando a distribuição do conjunto de dados de treinamento é significativamente diferente da distribuição do conjunto de dados de serviço. Uma das principais causas do desvio de distribuição é usar código diferente ou fontes de dados diferentes para gerar o conjunto de dados de treinamento. Outra razão é um mecanismo de amostragem defeituoso que escolhe uma subamostra não representativa dos dados de serviço para treinar.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
Neste exemplo, vemos algum desvio, mas está bem abaixo do limite que definimos.
Congele o esquema
Agora que o esquema foi revisado e curado, vamos armazená-lo em um arquivo para refletir seu estado "congelado".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Quando usar o TFDV
É fácil pensar que o TFDV se aplica apenas ao início do seu pipeline de treinamento, como fizemos aqui, mas na verdade ele tem muitos usos. Aqui estão mais alguns:
- Validar novos dados para inferência para garantir que não começamos a receber recursos ruins de repente
- Validar novos dados para inferência para garantir que nosso modelo tenha sido treinado nessa parte da superfície de decisão
- Validar nossos dados depois de transformá-los e fazer engenharia de recursos (provavelmente usando TensorFlow Transform ) para garantir que não fizemos algo errado