
Introdução
O TFX é uma plataforma de aprendizado de máquina (ML) em escala de produção do Google baseada no TensorFlow. Ele fornece uma estrutura de configuração e bibliotecas compartilhadas para integrar componentes comuns necessários para definir, iniciar e monitorar seu sistema de aprendizado de máquina.
TFX 1.0
Estamos felizes em anunciar a disponibilidade do TFX 1.0.0 . Esta é a versão inicial pós-beta do TFX, que fornece APIs e artefatos públicos estáveis. Você pode ter certeza de que seus futuros pipelines TFX continuarão funcionando após uma atualização dentro do escopo de compatibilidade definido neste RFC .
Instalação

![]()
pip install tfx
Pacotes noturnos
O TFX também hospeda pacotes noturnos em https://pypi-nightly.tensorflow.org no Google Cloud. Para instalar o pacote noturno mais recente, use o seguinte comando:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Isso instalará os pacotes noturnos para as principais dependências do TFX, como TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
Sobre o TFX
O TFX é uma plataforma para criar e gerenciar fluxos de trabalho de ML em um ambiente de produção. O TFX fornece o seguinte:
Um kit de ferramentas para criar pipelines de ML. Os pipelines do TFX permitem orquestrar seu fluxo de trabalho de ML em várias plataformas, como: Apache Airflow, Apache Beam e Kubeflow Pipelines.
Um conjunto de componentes padrão que você pode usar como parte de um pipeline ou como parte de seu script de treinamento de ML. Os componentes padrão do TFX fornecem funcionalidade comprovada para ajudá-lo a começar a criar um processo de ML facilmente.
Bibliotecas que fornecem a funcionalidade básica para muitos dos componentes padrão. Você pode usar as bibliotecas TFX para adicionar essa funcionalidade aos seus próprios componentes personalizados ou usá-los separadamente.
O TFX é um kit de ferramentas de aprendizado de máquina em escala de produção do Google baseado no TensorFlow. Ele fornece uma estrutura de configuração e bibliotecas compartilhadas para integrar componentes comuns necessários para definir, iniciar e monitorar seu sistema de aprendizado de máquina.
Componentes padrão TFX
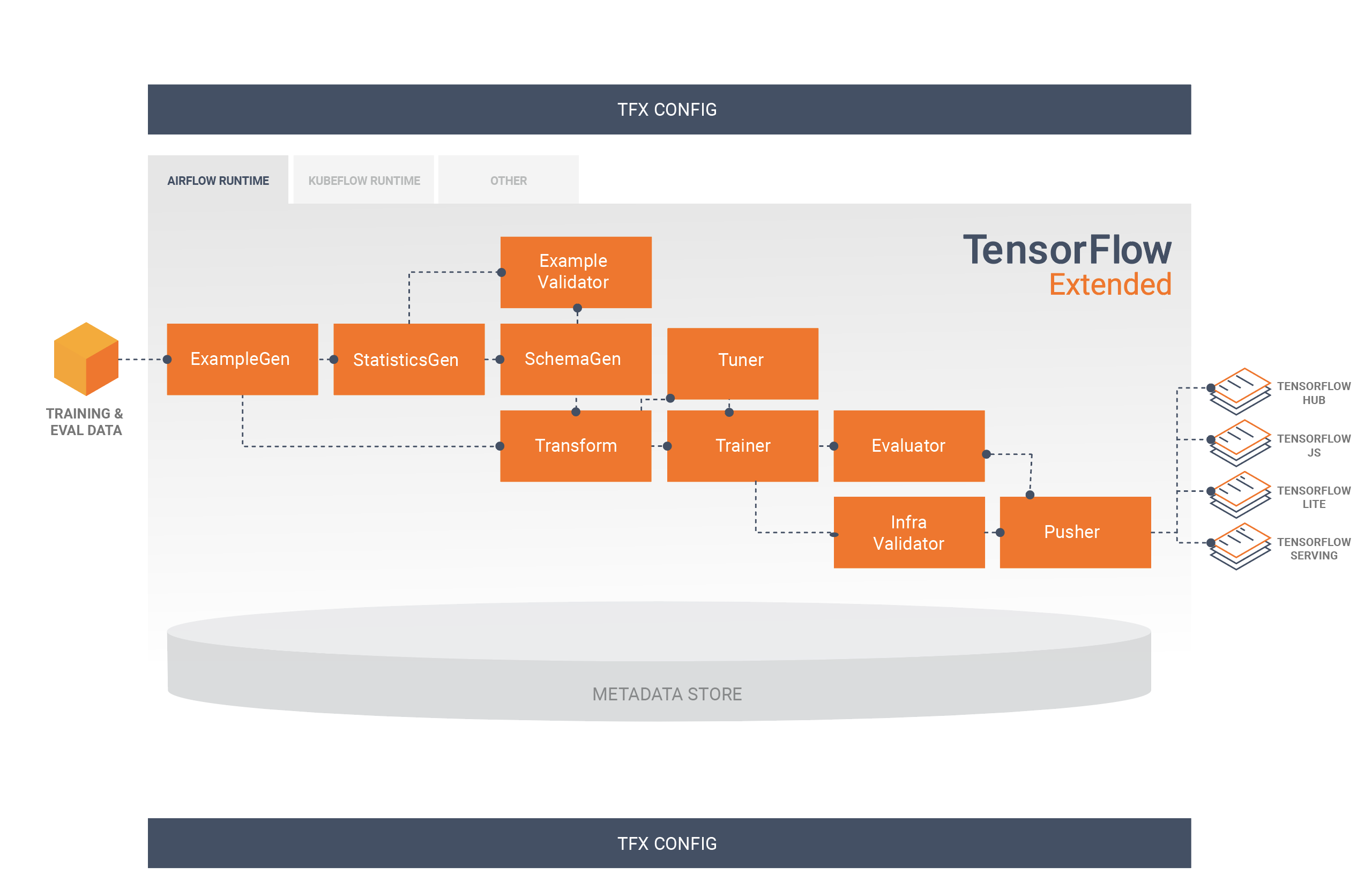
Um pipeline do TFX é uma sequência de componentes que implementam um pipeline de ML projetado especificamente para tarefas de aprendizado de máquina escaláveis e de alto desempenho. Isso inclui modelagem, treinamento, inferência de serviço e gerenciamento de implantações para destinos on-line, móveis nativos e JavaScript.
Um pipeline TFX normalmente inclui os seguintes componentes:
ExampleGen é o componente de entrada inicial de um pipeline que ingere e, opcionalmente, divide o conjunto de dados de entrada.
StatisticsGen calcula estatísticas para o conjunto de dados.
SchemaGen examina as estatísticas e cria um esquema de dados.
ExampleValidator procura anomalias e valores ausentes no conjunto de dados.
O Transform executa a engenharia de recursos no conjunto de dados.
O treinador treina o modelo.
O Tuner ajusta os hiperparâmetros do modelo.
O Evaluator realiza uma análise profunda dos resultados do treinamento e ajuda você a validar seus modelos exportados, garantindo que eles sejam "bons o suficiente" para serem enviados para produção.
O InfraValidator verifica se o modelo realmente pode ser servido a partir da infraestrutura e evita que um modelo ruim seja enviado.
O Pusher implanta o modelo em uma infraestrutura de serviço.
O BulkInferrer executa o processamento em lote em um modelo com solicitações de inferência não rotuladas.
Este diagrama ilustra o fluxo de dados entre estes componentes:
Bibliotecas TFX
O TFX inclui bibliotecas e componentes de pipeline. Este diagrama ilustra as relações entre as bibliotecas do TFX e os componentes do pipeline:
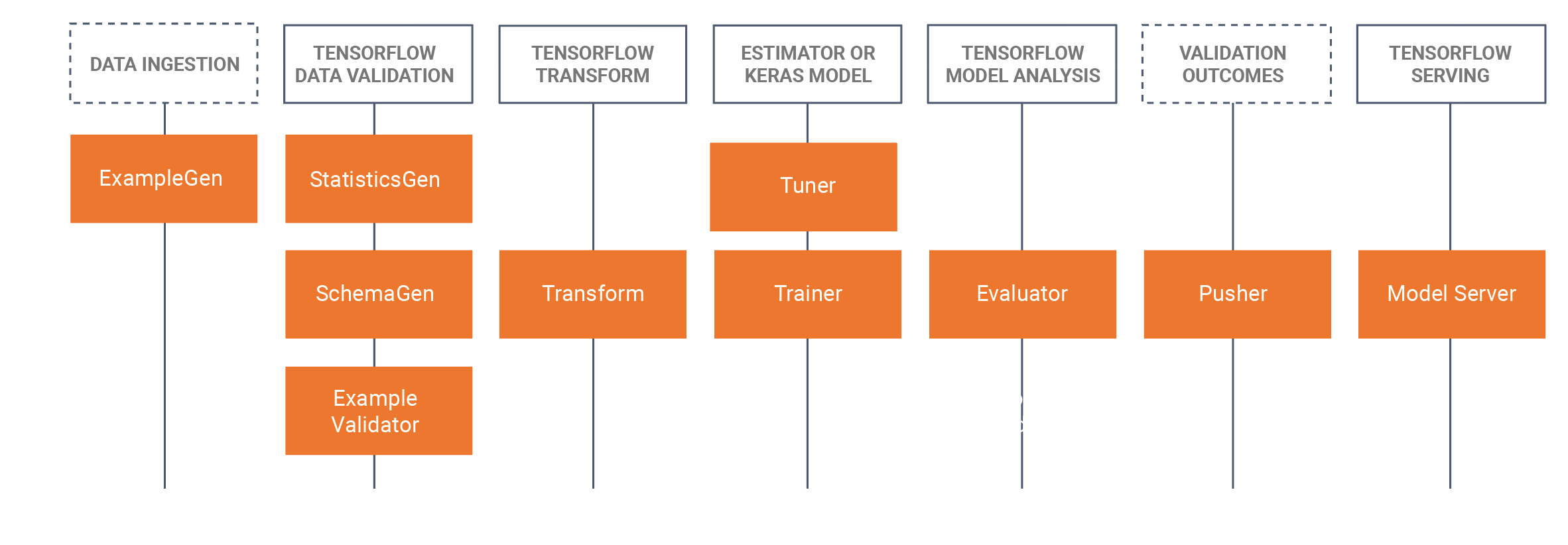
O TFX fornece vários pacotes Python que são as bibliotecas usadas para criar componentes de pipeline. Você usará essas bibliotecas para criar os componentes de seus pipelines para que seu código possa se concentrar nos aspectos exclusivos de seu pipeline.
As bibliotecas TFX incluem:
O TensorFlow Data Validation (TFDV) é uma biblioteca para analisar e validar dados de aprendizado de máquina. Ele foi projetado para ser altamente escalável e funcionar bem com TensorFlow e TFX. TFDV inclui:
- Cálculo escalável de estatísticas resumidas de dados de treinamento e teste.
- Integração com um visualizador para distribuição de dados e estatísticas, bem como comparação facetada de pares de conjuntos de dados (Facets).
- Geração automatizada de esquema de dados para descrever expectativas sobre dados, como valores, intervalos e vocabulários necessários.
- Um visualizador de esquema para ajudá-lo a inspecionar o esquema.
- Detecção de anomalias para identificar anomalias, como recursos ausentes, valores fora do intervalo ou tipos de recursos incorretos, para citar alguns.
- Um visualizador de anomalias para que você possa ver quais recursos têm anomalias e aprender mais para corrigi-las.
O TensorFlow Transform (TFT) é uma biblioteca para pré-processamento de dados com o TensorFlow. O TensorFlow Transform é útil para dados que exigem passagem completa, como:
- Normalize um valor de entrada por média e desvio padrão.
- Converta strings em inteiros gerando um vocabulário sobre todos os valores de entrada.
- Converta floats em inteiros atribuindo-os a buckets com base na distribuição de dados observada.
O TensorFlow é usado para treinar modelos com TFX. Ele ingere dados de treinamento e código de modelagem e cria um resultado SavedModel. Ele também integra um pipeline de engenharia de recursos criado pelo TensorFlow Transform para pré-processamento de dados de entrada.
KerasTuner é usado para ajustar hiperparâmetros para modelo.
O TensorFlow Model Analysis (TFMA) é uma biblioteca para avaliar modelos do TensorFlow. Ele é usado junto com o TensorFlow para criar um EvalSavedModel, que se torna a base para sua análise. Ele permite que os usuários avaliem seus modelos em grandes quantidades de dados de forma distribuída, usando as mesmas métricas definidas em seu treinador. Essas métricas podem ser calculadas em diferentes fatias de dados e visualizadas em notebooks Jupyter.
Os metadados do TensorFlow (TFMD) fornecem representações padrão para metadados que são úteis ao treinar modelos de machine learning com o TensorFlow. Os metadados podem ser produzidos manualmente ou automaticamente durante a análise de dados de entrada e podem ser consumidos para validação, exploração e transformação de dados. Os formatos de serialização de metadados incluem:
- Um esquema que descreve dados tabulares (por exemplo, tf.Examples).
- Uma coleção de estatísticas resumidas sobre esses conjuntos de dados.
ML Metadata (MLMD) é uma biblioteca para gravar e recuperar metadados associados a fluxos de trabalho de desenvolvedores de ML e cientistas de dados. Na maioria das vezes, os metadados usam representações TFMD. O MLMD gerencia a persistência usando SQL-Lite , MySQL e outros armazenamentos de dados semelhantes.
Tecnologias de suporte
Requeridos
- O Apache Beam é um modelo unificado de código aberto para definir pipelines de processamento paralelo de dados em lote e streaming. O TFX usa o Apache Beam para implementar pipelines de dados paralelos. O pipeline é então executado por um dos back-ends de processamento distribuído compatíveis do Beam, que incluem Apache Flink, Apache Spark, Google Cloud Dataflow e outros.
Opcional
Os orquestradores, como o Apache Airflow e o Kubeflow, facilitam a configuração, a operação, o monitoramento e a manutenção de um pipeline de ML.
O Apache Airflow é uma plataforma para criar, agendar e monitorar de forma programática fluxos de trabalho. O TFX usa o Airflow para criar fluxos de trabalho como gráficos acíclicos direcionados (DAGs) de tarefas. O agendador do Airflow executa tarefas em uma matriz de workers enquanto segue as dependências especificadas. Utilitários avançados de linha de comando facilitam a execução de cirurgias complexas em DAGs. A rica interface do usuário facilita a visualização de pipelines em execução na produção, o monitoramento do progresso e a solução de problemas quando necessário. Quando os fluxos de trabalho são definidos como código, eles se tornam mais fáceis de manter, versáteis, testáveis e colaborativos.
O Kubeflow é dedicado a tornar as implantações de fluxos de trabalho de aprendizado de máquina (ML) no Kubernetes simples, portáteis e escaláveis. O objetivo do Kubeflow não é recriar outros serviços, mas fornecer uma maneira direta de implantar os melhores sistemas de código aberto para ML em diversas infraestruturas. Os Kubeflow Pipelines permitem a composição e execução de fluxos de trabalho reproduzíveis no Kubeflow, integrados com experimentação e experiências baseadas em notebook. Os serviços do Kubeflow Pipelines no Kubernetes incluem o repositório de metadados hospedado, mecanismo de orquestração baseado em contêiner, servidor de notebook e interface do usuário para ajudar os usuários a desenvolver, executar e gerenciar pipelines de ML complexos em escala. O SDK do Kubeflow Pipelines permite a criação e o compartilhamento de componentes e a composição de pipelines de forma programática.
Portabilidade e interoperabilidade
O TFX foi projetado para ser portátil para vários ambientes e estruturas de orquestração, incluindo Apache Airflow , Apache Beam e Kubeflow . Também é portátil para diferentes plataformas de computação, incluindo plataformas locais e em nuvem, como o Google Cloud Platform (GCP) . Em particular, o TFX interopera com serviços do GCP gerenciados por servidores, como o Cloud AI Platform for Training and Prediction e o Cloud Dataflow para processamento distribuído de dados para vários outros aspectos do ciclo de vida de ML.
Modelo x SavedModel
Modelo
Um modelo é a saída do processo de treinamento. É o registro serializado dos pesos que foram aprendidos durante o processo de treinamento. Esses pesos podem ser usados posteriormente para calcular previsões para novos exemplos de entrada. Para TFX e TensorFlow, 'modelo' refere-se aos pontos de verificação que contêm os pesos aprendidos até aquele ponto.
Observe que 'model' também pode se referir à definição do gráfico de computação do TensorFlow (ou seja, um arquivo Python) que expressa como uma previsão será calculada. Os dois sentidos podem ser usados alternadamente com base no contexto.
Modelo salvo
- O que é um SavedModel : uma serialização universal, de linguagem neutra, hermética e recuperável de um modelo do TensorFlow.
- Por que é importante : permite que sistemas de nível superior produzam, transformem e consumam modelos do TensorFlow usando uma única abstração.
SavedModel é o formato de serialização recomendado para atender a um modelo do TensorFlow em produção ou exportar um modelo treinado para um aplicativo móvel ou JavaScript nativo. Por exemplo, para transformar um modelo em um serviço REST para fazer previsões, você pode serializar o modelo como um SavedModel e servi-lo usando o TensorFlow Serving. Consulte Servindo um modelo do TensorFlow para obter mais informações.
Esquema
Alguns componentes do TFX usam uma descrição de seus dados de entrada chamada de esquema . O esquema é uma instância de schema.proto . Os esquemas são um tipo de buffer de protocolo , mais conhecido como "protobuf". O esquema pode especificar tipos de dados para valores de recursos, se um recurso deve estar presente em todos os exemplos, intervalos de valores permitidos e outras propriedades. Um dos benefícios de usar o TensorFlow Data Validation (TFDV) é que ele gerará automaticamente um esquema ao inferir tipos, categorias e intervalos dos dados de treinamento.
Aqui está um trecho de um protobuf de esquema:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Os seguintes componentes usam o esquema:
- Validação de dados do TensorFlow
- Transformação do TensorFlow
Em um pipeline TFX típico, a validação de dados do TensorFlow gera um esquema, que é consumido pelos outros componentes.
Desenvolvendo com TFX
O TFX fornece uma plataforma poderosa para todas as fases de um projeto de aprendizado de máquina, desde pesquisa, experimentação e desenvolvimento em sua máquina local até a implantação. Para evitar a duplicação de código e eliminar o potencial de distorção de treinamento/exibição , é altamente recomendável implementar seu pipeline do TFX para treinamento de modelo e implantação de modelos treinados e usar componentes Transform que aproveitam a biblioteca TensorFlow Transform para treinamento e inferência. Ao fazer isso, você usará o mesmo código de pré-processamento e análise de forma consistente e evitará diferenças entre os dados usados para treinamento e os dados alimentados para seus modelos treinados em produção, além de se beneficiar de escrever esse código uma vez.
Exploração, visualização e limpeza de dados
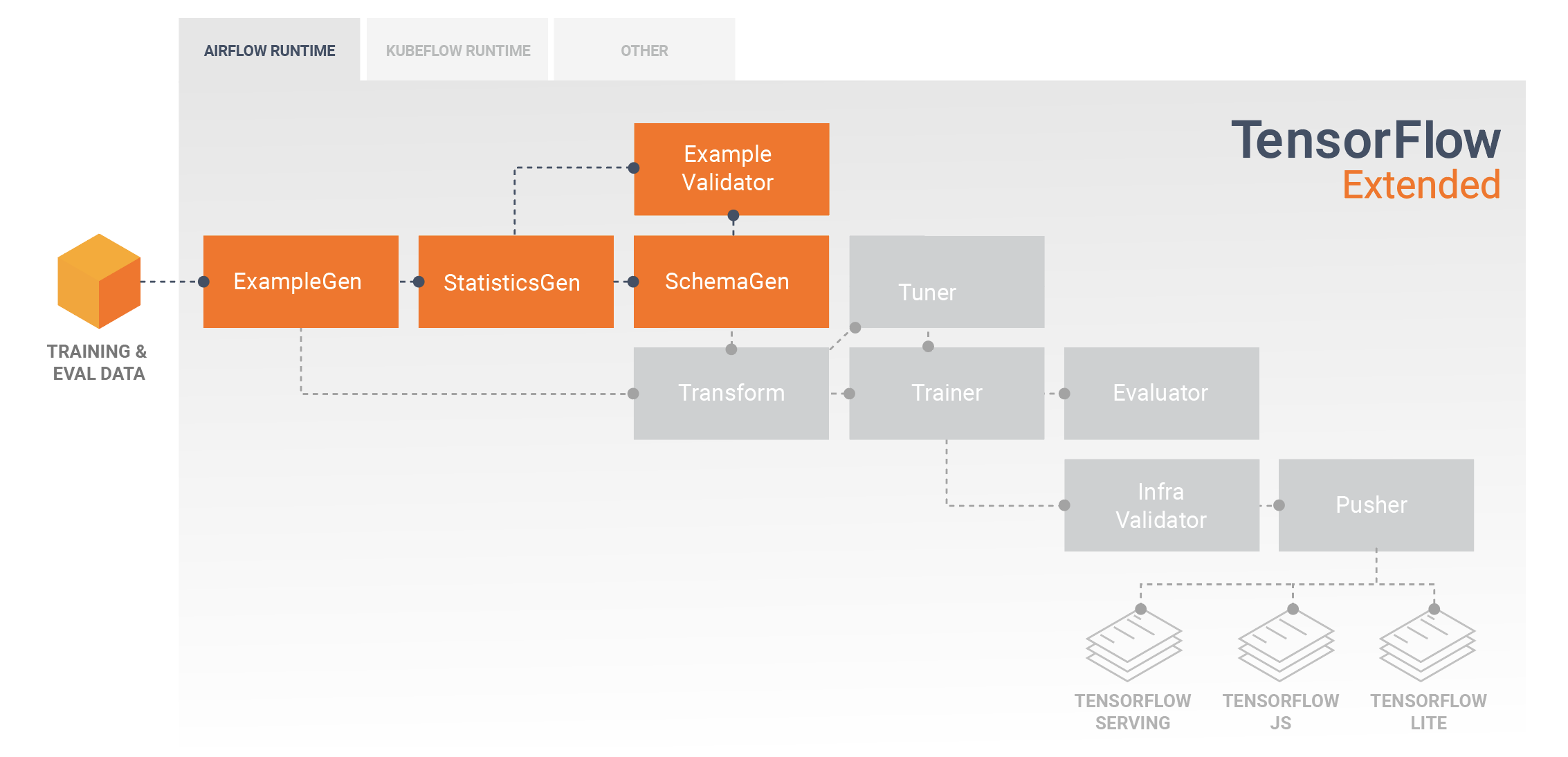
Os pipelines do TFX normalmente começam com um componente ExampleGen , que aceita dados de entrada e os formata como tf.Examples. Muitas vezes, isso é feito depois que os dados são divididos em conjuntos de dados de treinamento e avaliação para que haja, na verdade, duas cópias dos componentes ExampleGen, uma para treinamento e uma para avaliação. Isso geralmente é seguido por um componente StatisticsGen e um componente SchemaGen , que examinará seus dados e inferirá um esquema de dados e estatísticas. O esquema e as estatísticas serão consumidos por um componente ExampleValidator , que procurará anomalias, valores ausentes e tipos de dados incorretos em seus dados. Todos esses componentes aproveitam os recursos da biblioteca TensorFlow Data Validation .
A validação de dados do TensorFlow (TFDV) é uma ferramenta valiosa ao fazer a exploração inicial, visualização e limpeza do seu conjunto de dados. O TFDV examina seus dados e infere os tipos de dados, categorias e intervalos e, em seguida, ajuda automaticamente a identificar anomalias e valores ausentes. Ele também fornece ferramentas de visualização que podem ajudá-lo a examinar e entender seu conjunto de dados. Após a conclusão do pipeline, você pode ler metadados do MLMD e usar as ferramentas de visualização do TFDV em um notebook Jupyter para analisar seus dados.
Após o treinamento e a implantação do modelo inicial, o TFDV pode ser usado para monitorar novos dados de solicitações de inferência para seus modelos implantados e procurar anomalias e/ou desvios. Isso é especialmente útil para dados de séries temporais que mudam ao longo do tempo como resultado de tendência ou sazonalidade e pode ajudar a informar quando há problemas de dados ou quando os modelos precisam ser treinados novamente em novos dados.
Visualização de dados
Depois de concluir sua primeira execução de seus dados por meio da seção de seu pipeline que usa TFDV (normalmente StatisticsGen, SchemaGen e ExampleValidator), você pode visualizar os resultados em um notebook estilo Jupyter. Para execuções adicionais, você pode comparar esses resultados à medida que faz ajustes, até que seus dados sejam ideais para seu modelo e aplicativo.
Você primeiro consultará ML Metadata (MLMD) para localizar os resultados dessas execuções desses componentes e, em seguida, usará a API de suporte de visualização no TFDV para criar as visualizações em seu notebook. Isso inclui tfdv.load_statistics() e tfdv.visualize_statistics() Usando essa visualização, você pode entender melhor as características de seu conjunto de dados e, se necessário, modificar conforme necessário.
Modelos de Desenvolvimento e Treinamento
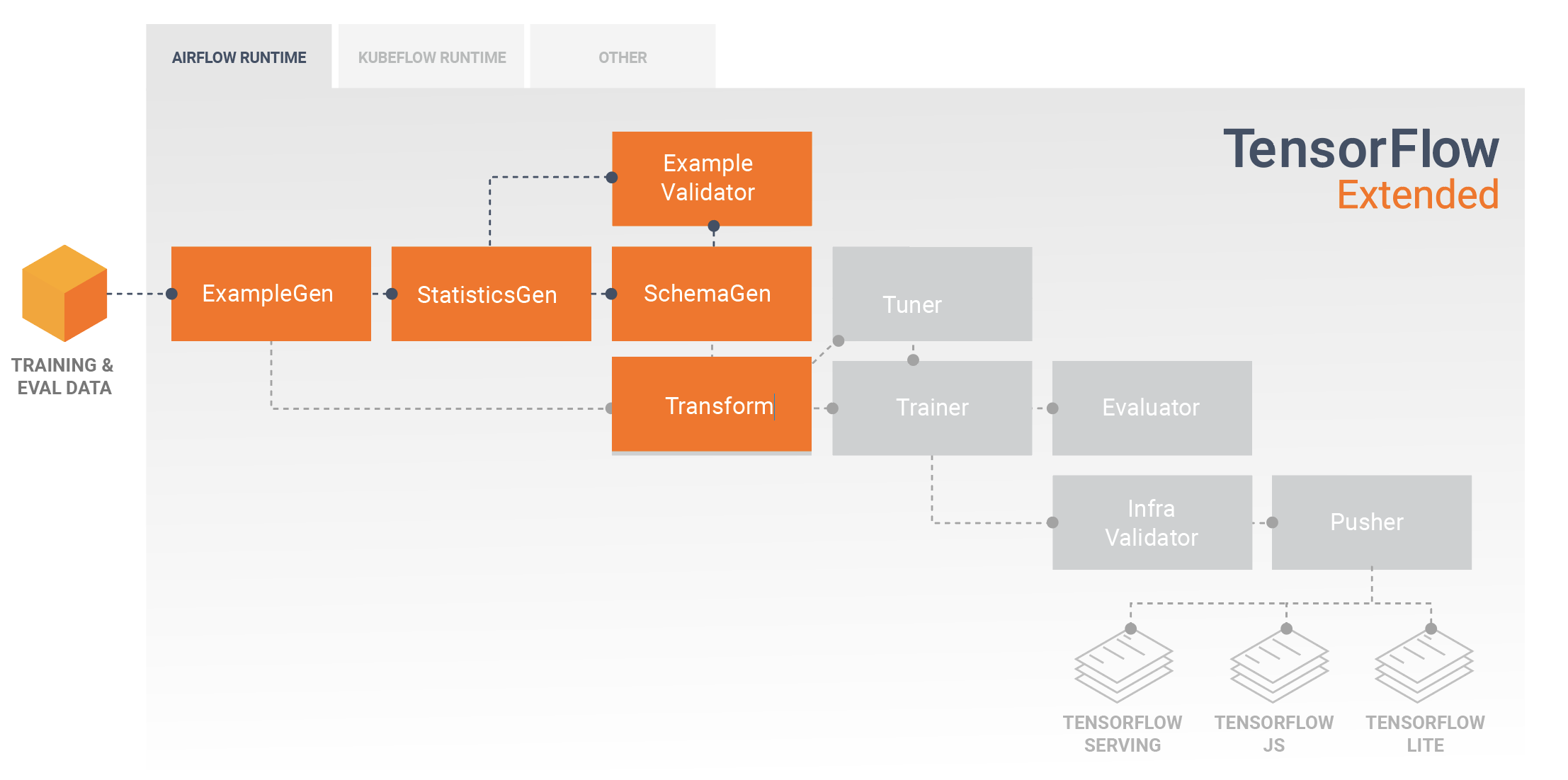
Um pipeline TFX típico incluirá um componente Transform , que realizará a engenharia de recursos aproveitando os recursos da biblioteca TensorFlow Transform (TFT) . Um componente Transform consome o esquema criado por um componente SchemaGen e aplica transformações de dados para criar, combinar e transformar os recursos que serão usados para treinar seu modelo. A limpeza de valores ausentes e a conversão de tipos também devem ser feitas no componente Transform se houver a possibilidade de que eles também estejam presentes nos dados enviados para solicitações de inferência. Há algumas considerações importantes ao projetar o código do TensorFlow para treinamento em TFX.
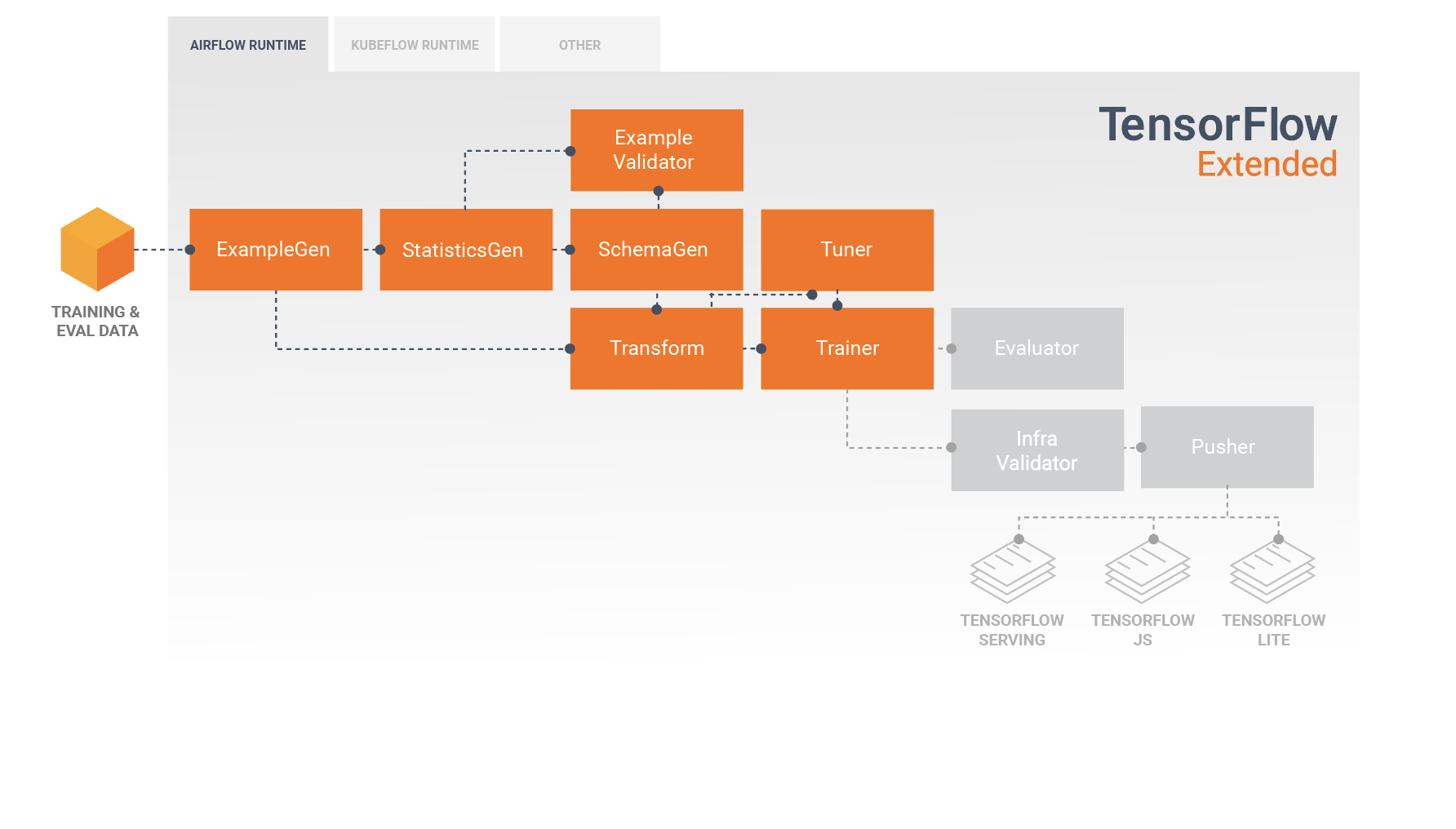
O resultado de um componente Transform é um SavedModel que será importado e usado em seu código de modelagem no TensorFlow, durante um componente Trainer . Este SavedModel inclui todas as transformações de engenharia de dados que foram criadas no componente Transform, para que as transformações idênticas sejam executadas usando exatamente o mesmo código durante o treinamento e a inferência. Usando o código de modelagem, incluindo o SavedModel do componente Transform, você pode consumir seus dados de treinamento e avaliação e treinar seu modelo.
Ao trabalhar com modelos baseados em Estimador, a última seção do seu código de modelagem deve salvar seu modelo como um SavedModel e um EvalSavedModel. Salvar como EvalSavedModel garante que as métricas usadas no tempo de treinamento também estejam disponíveis durante a avaliação (observe que isso não é necessário para modelos baseados em keras). Salvar um EvalSavedModel requer que você importe a biblioteca TensorFlow Model Analysis (TFMA) em seu componente Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Um componente Tuner opcional pode ser adicionado antes do Trainer para ajustar os hiperparâmetros (por exemplo, número de camadas) para o modelo. Com o modelo fornecido e o espaço de busca dos hiperparâmetros, o algoritmo de ajuste encontrará os melhores hiperparâmetros com base no objetivo.
Analisando e Entendendo o Desempenho do Modelo
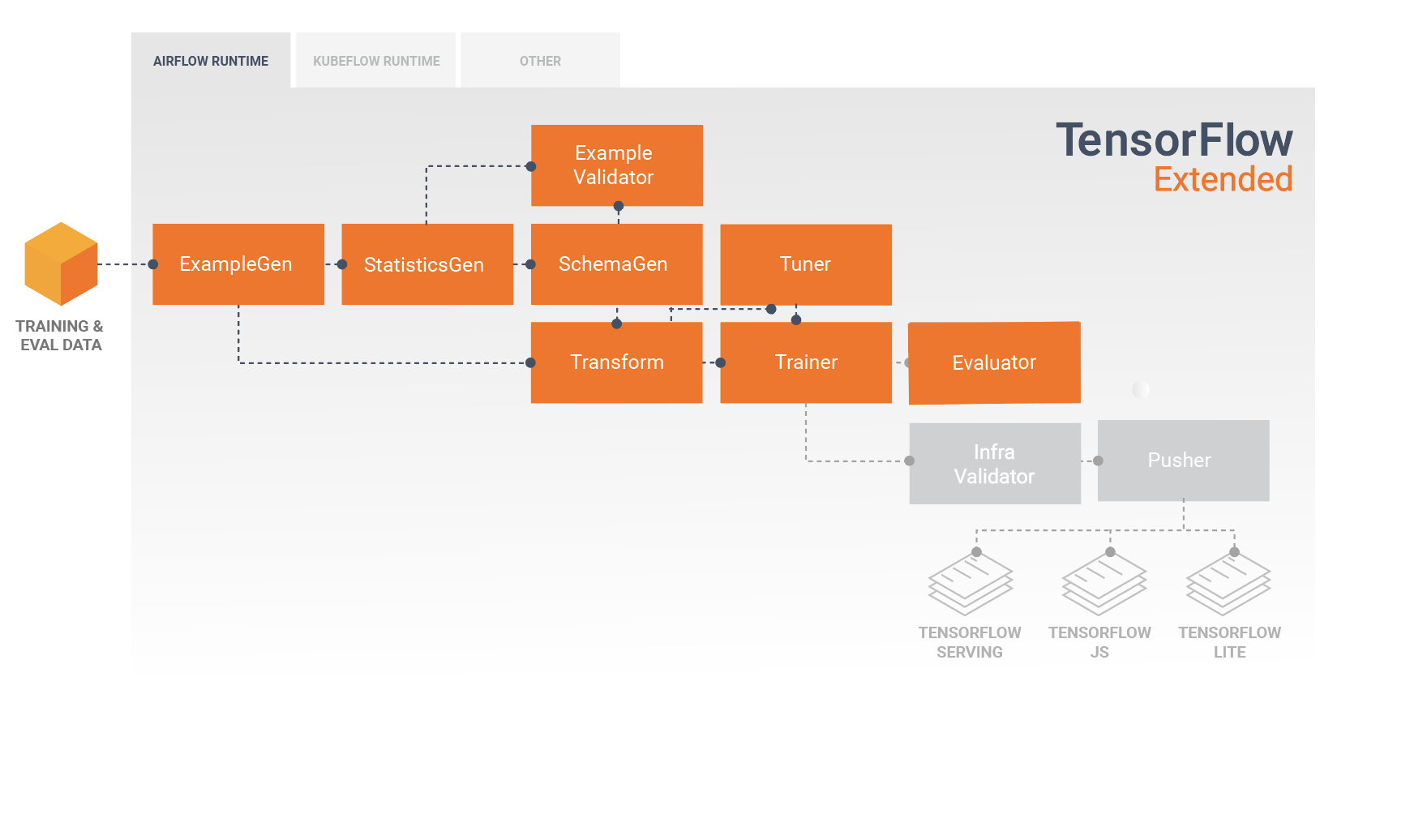
Após o desenvolvimento e treinamento inicial do modelo, é importante analisar e realmente entender o desempenho do seu modelo. Um pipeline TFX típico incluirá um componente Evaluator , que aproveita os recursos da biblioteca TensorFlow Model Analysis (TFMA) , que fornece um conjunto de ferramentas poderosas para esta fase de desenvolvimento. Um componente Evaluator consome o modelo que você exportou acima e permite especificar uma lista de tfma.SlicingSpec que você pode usar ao visualizar e analisar o desempenho do seu modelo. Cada SlicingSpec define uma fatia de seus dados de treinamento que você deseja examinar, como categorias específicas para recursos categóricos ou intervalos específicos para recursos numéricos.
Por exemplo, isso seria importante para tentar entender o desempenho do seu modelo para diferentes segmentos de seus clientes, que podem ser segmentados por compras anuais, dados geográficos, faixa etária ou sexo. Isso pode ser especialmente importante para conjuntos de dados com caudas longas, onde o desempenho de um grupo dominante pode mascarar um desempenho inaceitável para grupos importantes, porém menores. Por exemplo, seu modelo pode ter um bom desempenho para funcionários médios, mas falhar miseravelmente para a equipe executiva, e pode ser importante para você saber disso.
Análise e visualização de modelos
Depois de concluir sua primeira execução de seus dados treinando seu modelo e executando o componente Evaluator (que aproveita o TFMA ) nos resultados do treinamento, você pode visualizar os resultados em um notebook estilo Jupyter. Para execuções adicionais, você pode comparar esses resultados à medida que faz os ajustes, até que os resultados sejam ideais para seu modelo e aplicação.
Você primeiro consultará ML Metadata (MLMD) para localizar os resultados dessas execuções desses componentes e, em seguida, usará a API de suporte de visualização no TFMA para criar as visualizações em seu notebook. Isso inclui tfma.load_eval_results e tfma.view.render_slicing_metrics Usando esta visualização, você pode entender melhor as características de seu modelo e, se necessário, modificar conforme necessário.
Validando o desempenho do modelo
Como parte da análise do desempenho de um modelo, talvez você queira validar o desempenho em relação a uma linha de base (como o modelo em exibição no momento). A validação do modelo é realizada passando um modelo candidato e um modelo de linha de base para o componente Avaliador . O Avaliador calcula as métricas (por exemplo, AUC, perda) para o candidato e a linha de base, juntamente com um conjunto correspondente de métricas de diferença. Os limites podem então ser aplicados e usados para empurrar seus modelos para produção.
Validando que um modelo pode ser servido
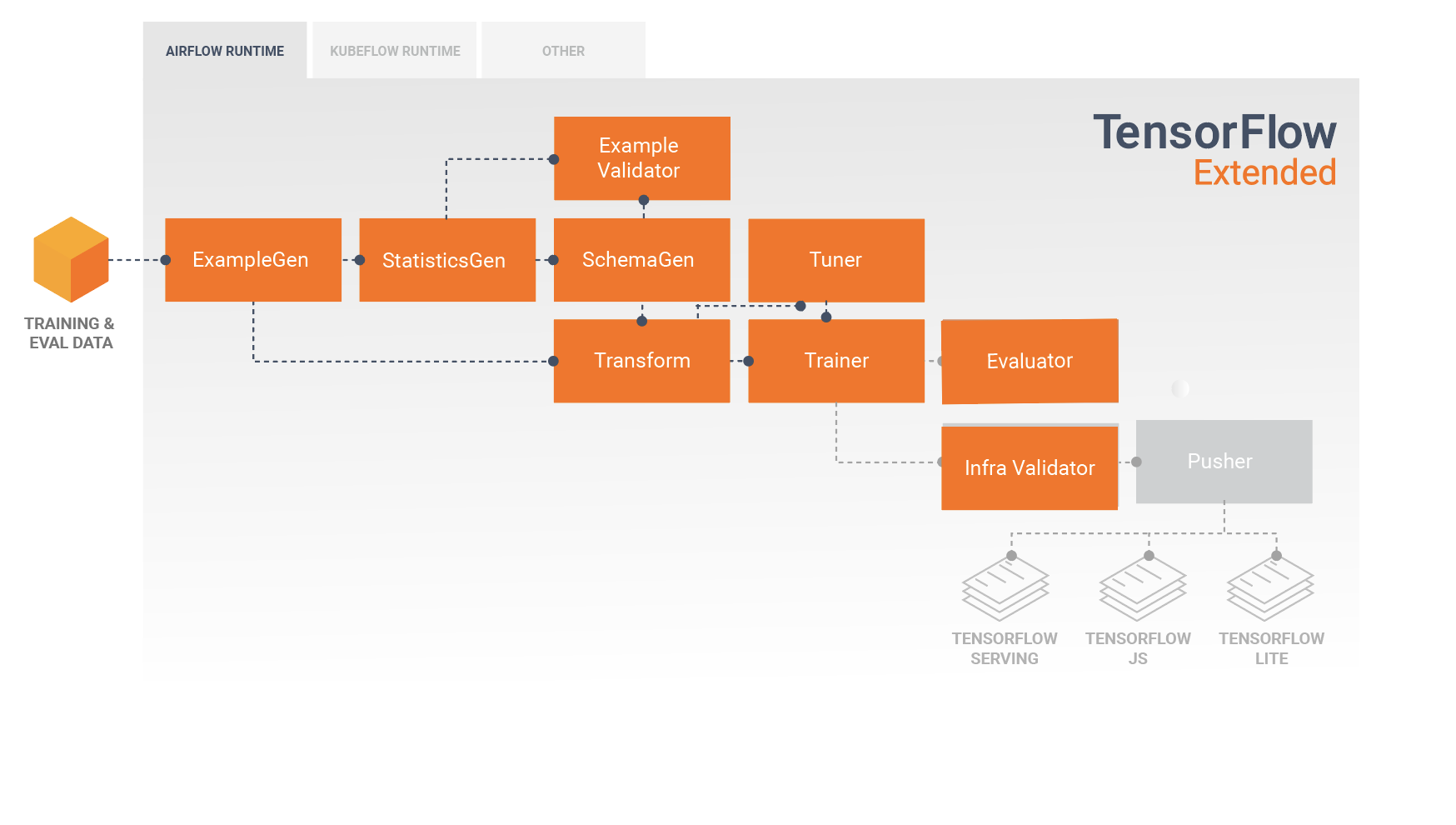
Antes de implantar o modelo treinado, convém validar se o modelo realmente pode ser servido na infraestrutura de serviço. Isso é especialmente importante em ambientes de produção para garantir que o modelo recém-publicado não impeça o sistema de atender às previsões. O componente InfraValidator fará uma implantação canário de seu modelo em um ambiente de área restrita e, opcionalmente, enviará solicitações reais para verificar se seu modelo funciona corretamente.
Metas de implantação
Depois de desenvolver e treinar um modelo com o qual você está satisfeito, agora é hora de implantá-lo em um ou mais destinos de implantação onde ele receberá solicitações de inferência. O TFX oferece suporte à implantação em três classes de destinos de implantação. Modelos treinados que foram exportados como SavedModels podem ser implantados em qualquer um ou em todos esses destinos de implantação.
Inferência: veiculação do TensorFlow
O TensorFlow Serving (TFS) é um sistema de serviço flexível e de alto desempenho para modelos de aprendizado de máquina, projetado para ambientes de produção. Ele consome um SavedModel e aceitará solicitações de inferência nas interfaces REST ou gRPC. Ele é executado como um conjunto de processos em um ou mais servidores de rede, usando uma das várias arquiteturas avançadas para lidar com sincronização e computação distribuída. Consulte a documentação do TFS para obter mais informações sobre como desenvolver e implantar soluções TFS.
Em um pipeline típico, um SavedModel que foi treinado em um componente Trainer seria primeiro infravalidado em um componente InfraValidator . O InfraValidator inicia um servidor de modelo TFS canário para realmente servir o SavedModel. Se a validação for aprovada, um componente Pusher finalmente implantará o SavedModel em sua infraestrutura do TFS. Isso inclui lidar com várias versões e atualizações de modelo.
Inferência em aplicativos móveis e IoT nativos: TensorFlow Lite
O TensorFlow Lite é um conjunto de ferramentas dedicado a ajudar os desenvolvedores a usar seus modelos TensorFlow treinados em aplicativos móveis e IoT nativos. Ele consome os mesmos SavedModels que o TensorFlow Serving e aplica otimizações como quantização e poda para otimizar o tamanho e o desempenho dos modelos resultantes para os desafios de execução em dispositivos móveis e IoT. Consulte a documentação do TensorFlow Lite para obter mais informações sobre como usar o TensorFlow Lite.
Inferência em JavaScript: TensorFlow JS
O TensorFlow JS é uma biblioteca JavaScript para treinamento e implantação de modelos de ML no navegador e no Node.js. Ele consome os mesmos SavedModels que o TensorFlow Serving e o TensorFlow Lite e os converte para o formato da Web TensorFlow.js. Consulte a documentação do TensorFlow JS para obter mais detalhes sobre como usar o TensorFlow JS.
Criando um pipeline TFX com fluxo de ar
Verifique a oficina de fluxo de ar para obter detalhes
Criando um pipeline TFX com Kubeflow
Configurar
O Kubeflow requer um cluster Kubernetes para executar os pipelines em escala. Consulte a diretriz de implantação do Kubeflow que orienta as opções de implantação do cluster Kubeflow.
Configurar e executar o pipeline do TFX
Siga o tutorial TFX on Cloud AI Platform Pipeline para executar o pipeline de exemplo do TFX no Kubeflow. Os componentes do TFX foram conteinerizados para compor o pipeline do Kubeflow e a amostra ilustra a capacidade de configurar o pipeline para ler grandes conjuntos de dados públicos e executar etapas de treinamento e processamento de dados em escala na nuvem.
Interface de linha de comando para ações de pipeline
O TFX fornece uma CLI unificada que ajuda a executar uma gama completa de ações de pipeline, como criar, atualizar, executar, listar e excluir pipelines em vários orquestradores, incluindo Apache Airflow, Apache Beam e Kubeflow. Para obter detalhes, siga estas instruções .