
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
개요
이 노트북은 TensorFlow 애드온에서 TripletSemiHardLoss 함수를 사용하는 방법을 보여줍니다.
리소스:
TripletLoss
FaceNet 논문에 처음 소개된 TripletLoss는 신경망을 훈련하여 같은 클래스의 특성을 밀접하게 포함하면서 서로 다른 클래스의 임베딩 간의 거리를 최대화합니다. 이를 위해 하나의 음수 샘플과 하나의 양수 샘플과 함께 앵커가 선택됩니다. 
손실 함수는 Euclidean 거리 함수로 설명됩니다.
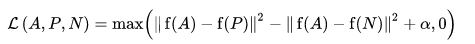
A는 앵커 입력이고, P는 양의 샘플 입력이고, N은 음의 샘플 입력이며, 알파는 트리플릿이 너무 "쉬워지는" 시점을 지정하기 위해 사용하는 한계입니다. .
SemiHard 온라인 학습
이 논문에서 볼 수 있듯이 가장 좋은 결과는 "Semi-Hard"로 알려진 트리플릿에서 얻습니다. 트리플릿은 음이 양보다 앵커에서 더 멀리 있는 트리플릿으로 정의되지만, 여전히 양의 손실을 생성합니다. 이러한 트리플릿을 효율적으로 찾기 위해 온라인 학습을 활용하고 각 배치에서 Semi-Hard 예제를 통해서만 훈련합니다.
설정
pip install -q -U tensorflow-addonsimport io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
데이터 준비하기
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset mnist/3.0.1 (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead pass `try_gcs=True` to `tfds.load` or set `data_dir=gs://tfds-data/datasets`. Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
모델 빌드하기

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
훈련 및 평가하기
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 7s 4ms/step - loss: 0.5884 Epoch 2/5 1875/1875 [==============================] - 7s 3ms/step - loss: 0.4532 Epoch 3/5 1875/1875 [==============================] - 7s 3ms/step - loss: 0.4175 Epoch 4/5 1875/1875 [==============================] - 7s 3ms/step - loss: 0.3938 Epoch 5/5 1875/1875 [==============================] - 7s 3ms/step - loss: 0.3898
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Embedding Projector
벡터 및 메타 데이터 파일은 https://projector.tensorflow.org/에서 로드하고 시각화할 수 있습니다.
UMAP으로 시각화하면 포함된 테스트 데이터의 결과를 볼 수 있습니다. 