
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
개요
이 튜토리얼은 Addons 패키지에서 Cyclical Learning Rate를 사용하는 방법을 보여줍니다.
주기적 학습률
신경망에 대한 훈련이 진행됨에 따라 학습률을 조정하는 것이 유익한 것으로 나타났습니다. 안장점 복구에서 역전파 동안 발생할 수 있는 수치적 불안정성 방지에 이르기까지 다양한 이점이 있습니다. 그러나 특정 훈련 타임스탬프와 관련하여 얼마나 조정해야 하는지 어떻게 알 수 있습니까? 2015년에 Leslie Smith는 손실 환경에서 더 빠르게 탐색하기 위해 학습률을 높이고 싶지만 수렴에 접근할 때 학습률을 낮추고 싶어한다는 사실을 알아냈습니다. 이 아이디어를 실현하기 위해, 그는 제안 순환 학습 요금 은 함수의주기에 대한 학습 속도를 조정할 것 (CLR을). 시각적 데모를 들어, 당신은 체크 아웃 할 수있다 이 블로그를 . 이제 CLR을 TensorFlow API로 사용할 수 있습니다. 자세한 내용은 원본 용지를 확인 여기에 .
설정
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
데이터세트 로드 및 준비
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
초매개변수 정의
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
모델 구축 및 모델 교육 유틸리티 정의
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
재현성을 위해 실험을 수행하는 데 사용할 초기 모델 가중치가 직렬화됩니다.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
CLR 없이 모델 훈련
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
CLR 일정 정의
tfa.optimizers.CyclicalLearningRate 옵티 마이저에 전달 될 수있는 직접 일정을 돌려 모듈. 일정은 입력으로 단계를 취하고 논문에 제시된 대로 CLR 공식을 사용하여 계산된 값을 출력합니다.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
여기서,는 학습율의 하한과 상한을 지정하고 그 일정 범위 사이에서 진동한다 ([1E-4, 1E-2] 인 경우). scale_fn 확장 주어진 사이클 내 학습 속도를 축소 할 함수를 정의하는 데 사용됩니다. step_size 단일 사이클의 기간을 정의합니다. step_size 2 수단은 하나의 사이클을 완료하는 데 4 반복의 총이 필요합니다. 에 대한 권장 값 step_size 다음과 같습니다 :
factor * steps_per_epoch 여기서 [2, 8]의 범위 내의 요소에있다.
같은에서 CLR 종이 , 레슬리도 속도를 학습에 대한 경계를 선택하는 간단하고 우아한 방법을 제시 하였다. 당신도 그것을 확인하는 것이 좋습니다. 이 블로그 게시물 방법에 대한 좋은 소개합니다.
다음, 당신은 어떻게 시각화 clr 일정 모습이 좋아.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
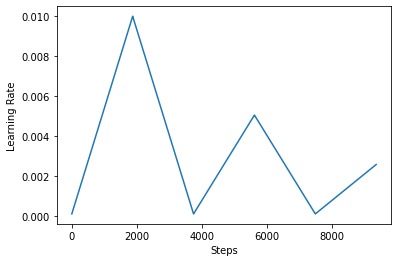
CLR의 효과를 더 잘 시각화하기 위해 증가된 단계 수로 일정을 그릴 수 있습니다.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
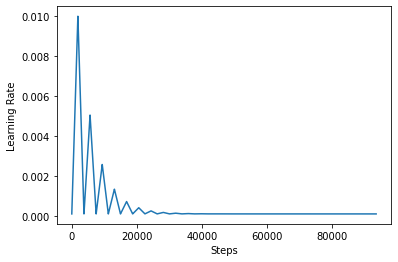
이 가이드에 사용되는 함수가라고 triangular2 CLR은 종이 제조 방법. 즉이 탐구하고 다른 두 가지 기능이 있습니다 triangular 및 exp (짧은 지수에 대한이).
CLR을 사용하여 모델 학습
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
예상대로 손실은 평소보다 높게 시작한 다음 사이클이 진행됨에 따라 안정화됩니다. 아래 도표를 통해 이를 시각적으로 확인할 수 있습니다.
손실 시각화
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
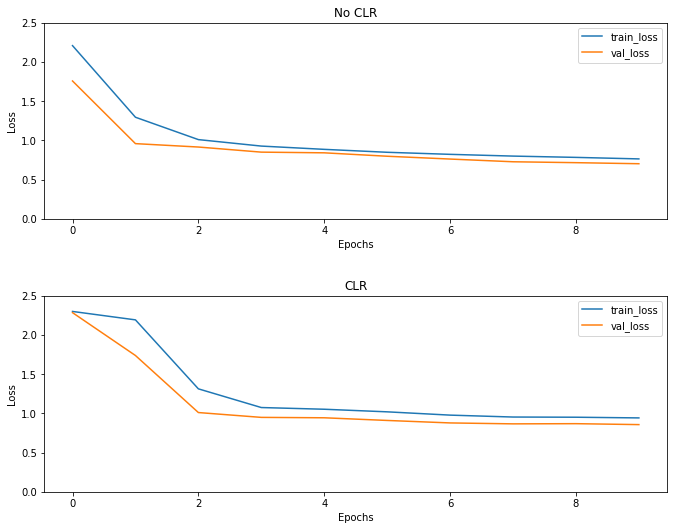
이 장난감 예를 들어, 당신은 CLR의 효과를 많이 보지 않았다하지만 뒤에 주요 성분 중 하나 주목해야 비록 슈퍼 수렴 하고, 수 정말 좋은 영향을 대규모 설정에서 훈련 할 때.