
حقوق الطبع والنشر 2021 The TF-Agents Authors.
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
مقدمة
التعلم المعزز (RL) هو إطار عام حيث يتعلم الوكلاء أداء الإجراءات في بيئة من أجل تعظيم المكافأة. المكونان الرئيسيان هما البيئة التي تمثل المشكلة المطلوب حلها والعامل الذي يمثل خوارزمية التعلم.
يتفاعل الوكيل والبيئة باستمرار مع بعضهما البعض. في كل خطوة الوقت، وكيل يأخذ العمل على البيئة على أساس سياستها \(\pi(a_t|s_t)\)، حيث \(s_t\) هو المراقبة الحالية من البيئة، ويحصل على مكافأة \(r_{t+1}\) ومراقبة المقبلة \(s_{t+1}\) من البيئة . الهدف هو تحسين السياسة لتعظيم مجموع المكافآت (العائد).
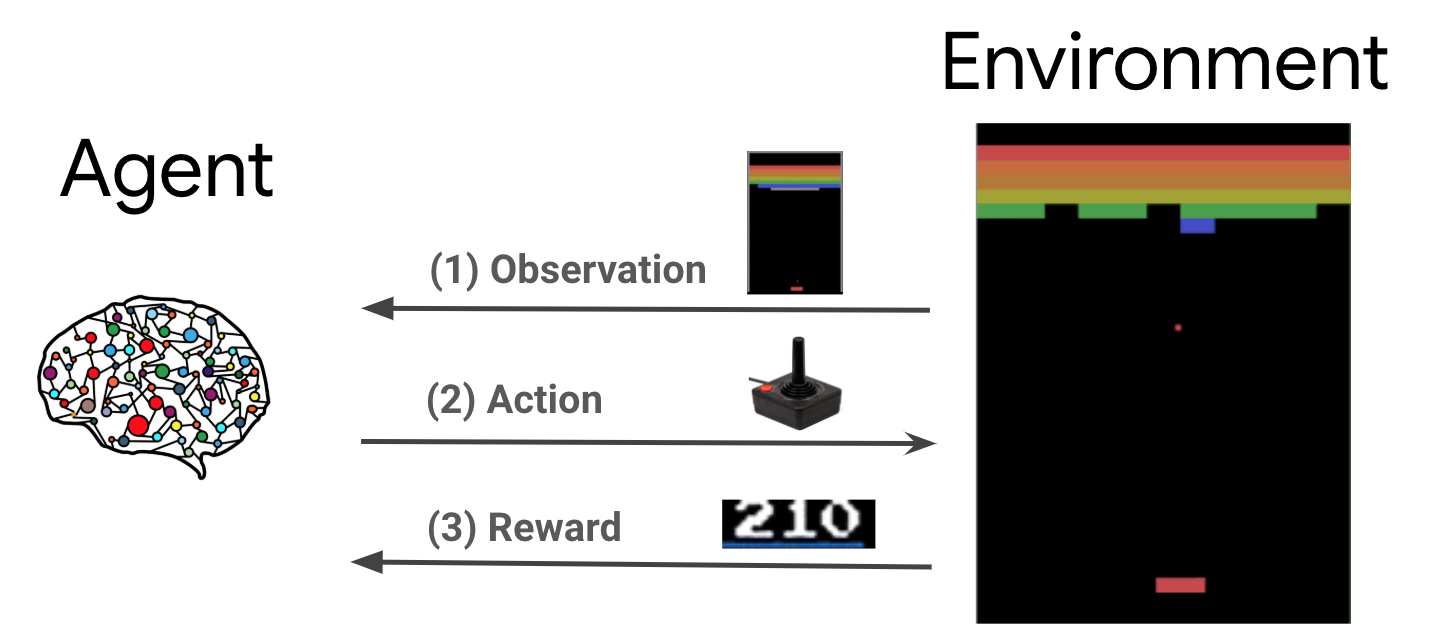
هذا إطار عام للغاية ويمكن أن يمثل مجموعة متنوعة من مشكلات اتخاذ القرار المتسلسل مثل الألعاب والروبوتات وما إلى ذلك.
بيئة Cartpole
البيئة Cartpole هي واحدة من المشاكل تعزيز التعلم الكلاسيكية الأكثر شهرة (و"مرحبا، العالم!" من RL). يتم توصيل عمود بعربة يمكنها التحرك على طول مسار غير احتكاك. يبدأ العمود في وضع مستقيم والهدف هو منعه من السقوط من خلال التحكم في العربة.
- ملاحظة من البيئة \(s_t\) هي ناقلات 4D تمثل الموقف وسرعة العربة، وزاوية والسرعة الزاوية للقطب.
- وكيل ويمكن التحكم في النظام عن طريق اتخاذ واحد من 2 الإجراءات \(a_t\): دفع عربة الحق (+1) أو اليسار (-1).
- مكافأة \(r_{t+1} = 1\) هو منصوص عليه في كل خطوة زمنية أن القطب لا يزال في وضع مستقيم. تنتهي الحلقة عند تحقق أحد الأمور التالية:
- تتعدى أطراف القطب بعض حدود الزاوية
- تتحرك العربة خارج حواف العالم
- 200 خطوة زمنية تمر.
والهدف من وكيل هو أن نتعلم سياسة \(\pi(a_t|s_t)\) وذلك لتحقيق أقصى قدر من مجموع المكافآت في حلقة \(\sum_{t=0}^{T} \gamma^t r_t\). هنا \(\gamma\) هو عامل خصم في \([0, 1]\) أن تخفيض المستقبل يكافئ نسبة إلى المكافآت الفورية. تساعدنا هذه المعلمة في تركيز السياسة ، مما يجعلها تهتم أكثر بالحصول على المكافآت بسرعة.
وكيل DQN
و DQN (ديب Q-شبكة) خوارزمية تم تطويره من قبل DeepMind في عام 2015. وكانت قادرة على حل مجموعة واسعة من الألعاب أتاري (البعض إلى مستوى فوق طاقة البشر) من خلال الجمع بين تعزيز التعلم والشبكات العصبية العميقة على نطاق واسع. وقد تم تطوير الخوارزمية من خلال تعزيز خوارزمية RL الكلاسيكية يسمى Q-التعلم مع الشبكات العصبية العميقة وتقنية تسمى تجربة اعادتها.
Q- التعلم
Q-Learning يعتمد على مفهوم Q-function. على وظيفة Q (ويعرف أيضا باسم ظيفة قيمة للعمل الدولة) سياسة \(\pi\)، \(Q^{\pi}(s, a)\)والتدابير العائد المتوقع أو المبلغ يخصم من المكافآت التي تم الحصول عليها من الدولة \(s\) عن طريق اتخاذ إجراءات \(a\) أولا وبعد سياسة \(\pi\) بعد ذلك. نحدد الأمثل Q-وظيفة \(Q^*(s, a)\) كحد أقصى من العائدات التي يمكن الحصول عليها بدءا من الملاحظة \(s\)، واتخاذ الإجراءات \(a\) وبعد سياسة الأمثل بعد ذلك. وQ-وظيفة الأمثل يطيع المنادي المثالية المعادلة التالية:
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
وهذا يعني أن أقصى عائد من دولة \(s\) والعمل \(a\) هي مجموع مكافأة فورية \(r\) وعودة (مخفضة كتبها \(\gamma\)) التي تم الحصول عليها عن طريق اتباع سياسة الأمثل بعد ذلك حتى نهاية الحلقة ( أي أن الحد الأقصى للمكافأة من القادم دولة \(s'\)). يتم احتساب التوقع على حد سواء على توزيع المكافآت الفورية \(r\) والدول المقبلة المحتملة \(s'\).
الفكرة الأساسية وراء Q-التعلم هو استخدام المعادلة المثالية المنادي كتحديث تكرارية \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\)، وأنه يمكن إثبات أن هذا CONVERGES لالأمثل \(Q\)-function، أي \(Q_i \rightarrow Q^*\) كما \(i \rightarrow \infty\) (انظر ورقة DQN ).
Q- التعلم العميق
بالنسبة لمعظم المشاكل، فمن غير عملي لتمثيل \(Q\)-function كجدول التي تحتوي على قيم لكل مجموعة من \(s\) و \(a\). بدلا من ذلك، نحن تدريب مقراب وظيفة، مثل الشبكة العصبية مع المعلمات \(\theta\)، لتقدير القيم Q، أي \(Q(s, a; \theta) \approx Q^*(s, a)\). يمكن أن يتم ذلك عن طريق التقليل من الخسائر التالية في كل خطوة \(i\):
\(\begin{equation}L_i(\theta_i) = \mathbb{E}_{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) حيث \(y_i = r + \gamma \max_{a'} Q(s', a'; \theta_{i-1})\)
هنا، \(y_i\) يسمى الهدف TD (الفرق الزمني)، و \(y_i - Q\) يسمى خطأ TD. \(\rho\) يمثل توزيع السلوك، وتوزيع أكثر من التحولات \(\{s, a, r, s'\}\) التي تم جمعها من البيئة.
علما بأن المعلمات من السابق التكرار \(\theta_{i-1}\) ثابتة ويتم تحديث. في الممارسة العملية ، نستخدم لقطة لمعلمات الشبكة من عدد قليل من التكرارات بدلاً من التكرار الأخير. وهذا ما يسمى نسخة من الشبكة المستهدفة.
Q-التعلم هو خوارزمية خارج السياسة التي يتعلم عن سياسة الجشع \(a = \max_{a} Q(s, a; \theta)\) أثناء استخدام سياسة سلوك مختلفة للتصرف في البيئة / جمع البيانات. هذه السياسة السلوك عادة ما يكون \(\epsilon\)سياسة -greedy أن يختار العمل الجشع مع احتمال \(1-\epsilon\) وعمل عشوائي مع احتمال \(\epsilon\) لضمان تغطية جيدة من المساحة للعمل الدولة.
تجربة الإعادة
لتجنب حساب التوقع الكامل في خسارة DQN ، يمكننا تقليله باستخدام النسب المتدرج العشوائي. إذا تم احتساب خسارة فقط باستخدام الانتقال الماضي \(\{s, a, r, s'\}\)، وهذا يقلل إلى معيار Q-التعلم.
قدم عمل Atari DQN تقنية تسمى Experience Replay لجعل تحديثات الشبكة أكثر استقرارًا. في كل خطوة الوقت لجمع البيانات، يتم إضافة الانتقال الى منطقة عازلة دائرية تسمى المخزن المؤقت اعادتها. ثم أثناء التدريب ، بدلاً من استخدام الانتقال الأخير فقط لحساب الخسارة وتدرجها ، نقوم بحسابها باستخدام مجموعة صغيرة من الانتقالات التي تم أخذ عينات منها من المخزن المؤقت لإعادة التشغيل. هذا له ميزتان: كفاءة أفضل للبيانات عن طريق إعادة استخدام كل انتقال في العديد من التحديثات ، واستقرار أفضل باستخدام انتقالات غير مرتبطة في دفعة.
DQN على Cartpole في وكلاء TF
يوفر TF-Agents جميع المكونات اللازمة لتدريب وكيل DQN ، مثل الوكيل نفسه ، والبيئة ، والسياسات ، والشبكات ، ومخازن إعادة التشغيل ، وحلقات جمع البيانات ، والمقاييس. يتم تنفيذ هذه المكونات كوظائف Python أو عمليات الرسم البياني TensorFlow ، ولدينا أيضًا أغلفة للتحويل فيما بينها. بالإضافة إلى ذلك ، يدعم TF-Agents وضع TensorFlow 2.0 ، والذي يمكننا من استخدام TF في الوضع الحتمي.
بعد ذلك، نلقي نظرة على البرنامج التعليمي لتدريب وكيل DQN على البيئة Cartpole باستخدام وكلاء TF .