
Telif Hakkı 2021 TF-Agents Yazarları.
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Tanıtım
Takviyeli öğrenme (RL), aracıların bir ortamda bir ödülü en üst düzeye çıkarmak için eylemler gerçekleştirmeyi öğrendiği genel bir çerçevedir. İki ana bileşen, çözülecek problemi temsil eden çevre ve öğrenme algoritmasını temsil eden etmendir.
Etmen ve çevre sürekli olarak birbirleriyle etkileşim halindedir. Her adımda, madde kendi ilke göre çevre üzerinde eylemde \(\pi(a_t|s_t)\), \(s_t\) ortamından mevcut gözlemdir, ve bir ödül alır \(r_{t+1}\) ve sonraki gözlem \(s_{t+1}\) ortamından . Amaç, ödüllerin toplamını (getiri) en üst düzeye çıkarmak için politikayı iyileştirmektir.
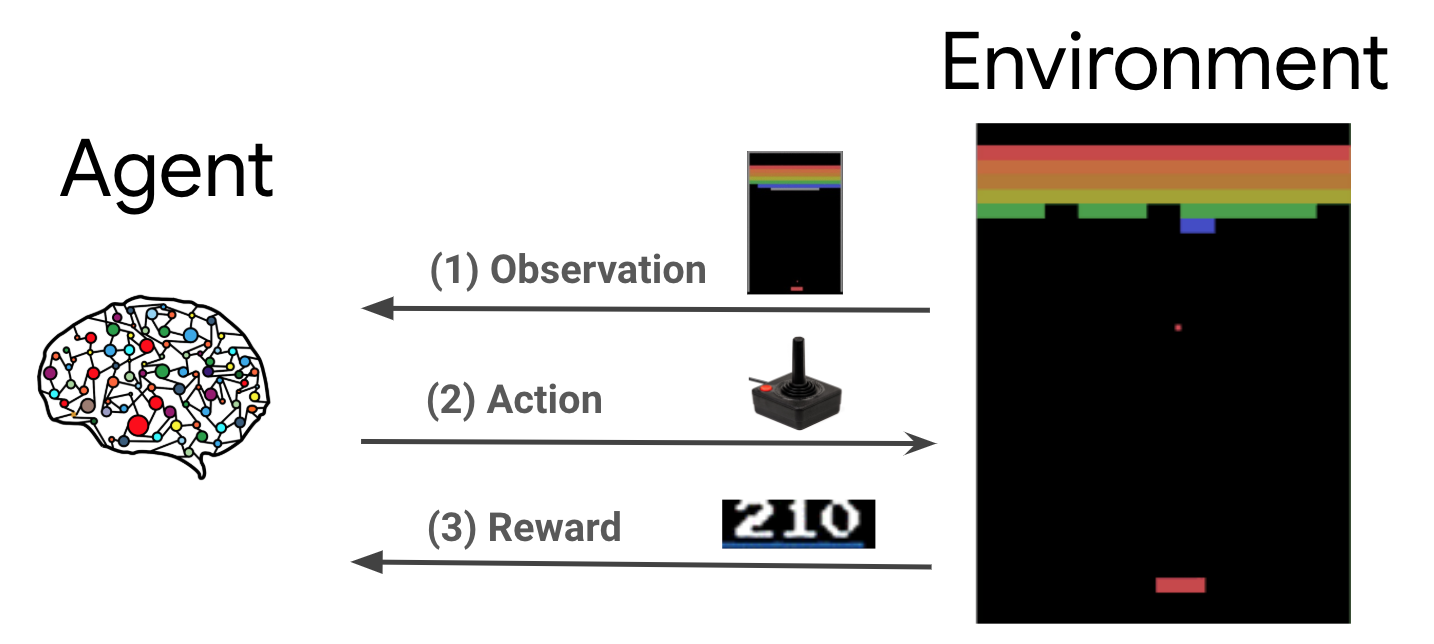
Bu çok genel bir çerçevedir ve oyunlar, robotik vb. gibi çeşitli sıralı karar verme problemlerini modelleyebilir.
Cartpole Çevre
Cartpole ortamı en iyi bilinen klasik takviye öğrenme sorunlarından biri ( "Merhaba, Dünya!" RL) 'dir. Sürtünmesiz bir yol boyunca hareket edebilen bir arabaya bir direk bağlanmıştır. Direk dik başlar ve amaç, arabayı kontrol ederek düşmesini önlemektir.
- Çevre ile ilgili gözlem \(s_t\) konumu ve arabasının hız ve açısı ve kutup açısal hızını temsil eden bir 4D vektördür.
- Madde 2 işlemlerden birini alma sistemi kontrol edebilir \(a_t\): sepeti doğru (1) ya da sol (-1) itin.
- Bir ödül \(r_{t+1} = 1\) kutup dik kalmasını her timestep için sağlanmıştır. Bölüm, aşağıdakilerden biri doğru olduğunda sona erer:
- bazı açı sınırı üzerinde kutup uçları
- araba dünya kenarlarının dışına doğru hareket eder
- 200 zaman adımı geçer.
Maddesinin amacı bir politika öğrenmektir \(\pi(a_t|s_t)\) bir bölüm içinde ödüllerin toplamı maksimize edecek şekilde \(\sum_{t=0}^{T} \gamma^t r_t\). İşte \(\gamma\) bir indirim faktördür \([0, 1]\) indirimler gelecek acil ödüller göre ödüllendirir. Bu parametre, politikaya odaklanmamıza yardımcı olur ve ödüllerin hızla elde edilmesini daha fazla önemser.
DQN Temsilcisi
DQN (Derin Q-Ağı) algoritması O ölçekte takviye öğrenme ve derin sinir ağları birleştirerek Atari oyunları geniş bir yelpazede (insanüstü seviyeye bazı) çözmeyi başardı 2015 yılında DeepMind tarafından geliştirilmiştir. Algoritma derin sinir ağları ve bir teknik denilen deneyim tekrar maçı Q-Öğrenme adında bir klasik RL algoritmasını geliştirerek geliştirilmiştir.
Q-Öğrenme
Q-Learning, bir Q-fonksiyonu kavramına dayanmaktadır. İlke Q fonksiyonlu (aka durumu etkili değer fonksiyonu) \(\pi\), \(Q^{\pi}(s, a)\)durum elde edilen ödüllerin tedbirler beklenen geri dönüş veya indirgenmiş toplamı \(s\) aksiyon alarak \(a\) birinci ve ilke şu \(\pi\) sonra. Optimal S fonksiyonlu tanımlayan \(Q^*(s, a)\) gözlem başlanarak elde edilebilir maksimum dönüş olarak \(s\)aksiyon alarak \(a\) ve bundan sonra en uygun ilkesini takip. Optimal S-fonksiyonu aşağıdaki Bellman optimumu denkleme uyar:
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
Devlet maksimum dönüş bu araçlar \(s\) ve eylem \(a\) hemen ödül toplamıdır \(r\) ve (göre indirgenmiş dönüş \(\gamma\)bölüm sonuna kadar daha sonra uygun bir politika izlenerek elde edildi) ( yani, sonraki durum maksimum ödül \(s'\)). Beklenti acil ödüllerin dağılımı üzerinde hem hesaplanır \(r\) ve olası bir sonraki devletler \(s'\).
Q-Öğrenme ardındaki temel fikir iteratif güncelleme olarak Tellal eniyilik denklemini kullanmaktır \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\)ve optimum için bu yakınsak olduğu gösterilebilir \(Q\)-Fonksiyon, yani \(Q_i \rightarrow Q^*\) olarak \(i \rightarrow \infty\) (bkz DQN kağıt ).
Derin Q-Öğrenme
En sorunları için, temsil etmek pratik değildir \(Q\)her kombinasyonu için değerleri içeren bir tablo olarak taşımasının avantajlı \(s\) ve \(a\). Bunun yerine, bu tür parametrelerle bir sinir ağı gibi işlev Approximator tren \(\theta\)Q-değerleri, yani tahmin etmek, \(Q(s, a; \theta) \approx Q^*(s, a)\). Bu, her adımı aşağıdaki kaybını minimize ederek yapılan edebilir \(i\):
\(\begin{equation}L_i(\theta_i) = \mathbb{E}_{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) burada \(y_i = r + \gamma \max_{a'} Q(s', a'; \theta_{i-1})\)
Burada, \(y_i\) TD (zamansal fark) hedef denir ve \(y_i - Q\) TD hatası denir. \(\rho\) geçişler üzerinde davranış dağılımı, dağıtım temsil \(\{s, a, r, s'\}\) ortamından topladı.
Bir önceki yineleme gelen parametreler olduğunu Not \(\theta_{i-1}\) sabit ve güncellenmiş değildir. Pratikte, son yineleme yerine birkaç yinelemeden ağ parametrelerinin anlık görüntüsünü kullanırız. Bu kopya hedef ağı denir.
S-İçi hırslı ilke ilgili öğrenir bu grimsi ilke algoritmasıdır \(a = \max_{a} Q(s, a; \theta)\) / ortamda hareket veri toplamak için farklı bir davranış ilkesini kullanarak. Bu davranış politikası genellikle olduğu \(\epsilon\)olasılık ile seçer açgözlü eylemdir -greedy politika \(1-\epsilon\) ve olasılık ile rastgele eylem \(\epsilon\) devlet aksiyon alanı iyi kapsama sağlamak için.
Tekrar Oynatmayı Deneyimleyin
DQN kaybındaki tam beklentiyi hesaplamaktan kaçınmak için stokastik gradyan inişini kullanarak onu en aza indirebiliriz. Kaybı sadece geçen geçiş kullanılarak hesaplanır Eğer \(\{s, a, r, s'\}\), bu standart Q-Öğrenme azaltır.
Atari DQN çalışması, ağ güncellemelerini daha kararlı hale getirmek için Experience Replay adlı bir teknik tanıttı. Veri toplama, her adımda, geçişler tekrar tampon adı verilen dairesel bir tampon eklenir. Ardından, eğitim sırasında, kaybı ve gradyanını hesaplamak için yalnızca en son geçişi kullanmak yerine, bunları tekrar arabelleğinden örneklenen mini toplu geçişleri kullanarak hesaplarız. Bunun iki avantajı vardır: birçok güncellemede her geçişi yeniden kullanarak daha iyi veri verimliliği ve bir toplu işte ilişkisiz geçişleri kullanarak daha iyi kararlılık.
TF-Agent'larda Cartpole üzerinde DQN
TF-Agents, aracının kendisi, ortam, politikalar, ağlar, yeniden yürütme arabellekleri, veri toplama döngüleri ve ölçümler gibi bir DQN aracısını eğitmek için gerekli tüm bileşenleri sağlar. Bu bileşenler Python işlevleri veya TensorFlow grafik işlemleri olarak uygulanır ve ayrıca bunlar arasında dönüştürme için sarmalayıcılarımız da vardır. Ek olarak, TF-Agents, TF'yi zorunlu modda kullanmamızı sağlayan TensorFlow 2.0 modunu destekler.
Daha sonra, bir göz atın TF-Ajanlar kullanarak Cartpole çevre üzerinde DQN ajan eğitimi için öğretici .