
حقوق الطبع والنشر 2021 The TF-Agents Authors.
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
مقدمة
هذا المثال يبين كيفية تدريب تعزيز عامل على البيئة Cartpole باستخدام مكتبة كلاء TF، على غرار DQN البرنامج التعليمي .
سنوجهك عبر جميع المكونات في خط أنابيب التعلم المعزز (RL) للتدريب والتقييم وجمع البيانات.
اقامة
إذا لم تكن قد قمت بتثبيت التبعيات التالية ، فقم بتشغيل:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Hyperparameters
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
بيئة
تمثل البيئات في RL المهمة أو المشكلة التي نحاول حلها. البيئات القياسية يمكن أن تنشأ بسهولة في وكلاء TF باستخدام suites . لدينا مختلف suites لتحميل البيئات من مصادر مثل OpenAI رياضة، أتاري، تحكم DM، وما إلى ذلك، يطلق عليها اسم بيئة السلسلة.
الآن دعنا نحمّل بيئة CartPole من مجموعة OpenAI Gym.
env = suite_gym.load(env_name)
يمكننا تقديم هذه البيئة لنرى كيف تبدو. يتم توصيل عمود يتأرجح بحرية بعربة. الهدف هو تحريك العربة يمينًا أو يسارًا لإبقاء العمود مشيرًا لأعلى.
env.reset()
PIL.Image.fromarray(env.render())
و time_step = environment.step(action) يأخذ بيان action في البيئة. في TimeStep الصفوف (tuple) عاد تحتوي على الملاحظة التالية البيئة ومكافأة لهذا الإجراء. و time_step_spec() و action_spec() الأساليب في بيئة تعود للمواصفات (أنواع والأشكال والحدود) من time_step و action على التوالي.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
لذلك ، نرى أن الملاحظة عبارة عن مصفوفة مكونة من 4 عوامات: موضع العربة وسرعتها ، وموضع الزاوية وسرعتها للقطب. منذ اثنين فقط إجراءات ممكنة (خطوة إلى اليمين أو تحرك إلى اليمين)، و action_spec هو العددية حيث 0 تعني "غادر الخطوة" و 1 يعني "التحرك الحق".
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
عادة نخلق بيئتين: واحدة للتدريب والأخرى للتقييم. يتم كتابة معظم البيئات في بيثون النقي، ولكن يمكن تحويلها بسهولة إلى TensorFlow باستخدام TFPyEnvironment المجمع. يستخدم API البيئة الأصلية لصفائف نمباي، و TFPyEnvironment تحويل هذه إلى / من Tensors بالنسبة لك لأكثر سهولة التفاعل مع السياسات TensorFlow والوكلاء.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
وكيلات
ويمثل الخوارزمية التي نستخدمها لحل مشكلة RL باعتبارها Agent . بالإضافة إلى تعزيز عامل، TF-وكلاء يوفر تطبيقات القياسية من مجموعة متنوعة من Agents مثل DQN ، DDPG ، TD3 ، PPO و SAC .
لإنشاء تعزيز وكيل، نحتاج أولا ل Actor Network التي يمكن أن تتعلم لتوقع عمل معين ملاحظة من البيئة.
يمكننا بسهولة خلق Actor Network باستخدام المواصفات من الملاحظات والإجراءات. يمكننا تحديد الطبقات في الشبكة التي، في هذا المثال، هو fc_layer_params مجموعة حجة لالصفوف (tuple) من ints تمثل الأحجام من كل طبقة سرية (راجع قسم Hyperparameters أعلاه).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
ونحن أيضا بحاجة إلى optimizer لتدريب شبكة أنشأنا فقط، و train_step_counter متغير لتعقب كم مرة تم تحديث الشبكة.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
سياسات
في وكلاء TF، تمثل سياسات فكرة القياسية السياسات في RL: إعطاء time_step إنتاج عمل أو توزيع أكثر من الإجراءات. الأسلوب الرئيسي هو policy_step = policy.action(time_step) حيث policy_step هو الصفوف (tuple) اسمه PolicyStep(action, state, info) . و policy_step.action هو action ليتم تطبيقها على البيئة، و state تمثل الدولة لسياسات جليل (RNN) و info قد تحتوي على معلومات المساعدة مثل الاحتمالات سجل من الإجراءات.
يحتوي الوكلاء على سياستين: السياسة الرئيسية المستخدمة للتقييم / النشر (agent.policy) وسياسة أخرى تُستخدم لجمع البيانات (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
المقاييس والتقييم
المقياس الأكثر شيوعًا المستخدم لتقييم السياسة هو متوسط العائد. العائد هو مجموع المكافآت التي تم الحصول عليها أثناء تشغيل سياسة في بيئة للحلقة ، وعادةً ما نقوم بتوسيط هذا على عدة حلقات. يمكننا حساب متوسط مقياس العائد على النحو التالي.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
إعادة العازلة
من أجل تتبع البيانات التي تم جمعها من البيئة، وسوف نستخدم تردد ، ونظام إعادة كفاءة، للمد، وسهلة الاستخدام من قبل Deepmind. يخزن بيانات الخبرة عندما نجمع المسارات ويتم استهلاكها أثناء التدريب.
هي التي شيدت عازلة اعادتها ذلك باستخدام المواصفات واصفا التنسورات التي سيتم تخزينها، والتي يمكن الحصول عليها من وكيل باستخدام tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
بالنسبة لمعظم وكلاء، و collect_data_spec هو Trajectory اسمه الصفوف (tuple) التي تحتوي على الملاحظة، والعمل، ومكافأة الخ
جمع البيانات
نظرًا لأن REINFORCE تتعلم من حلقات كاملة ، فإننا نحدد وظيفة لتجميع حلقة باستخدام سياسة جمع البيانات المحددة وحفظ البيانات (الملاحظات والإجراءات والمكافآت وما إلى ذلك) كمسارات في المخزن المؤقت لإعادة العرض. نحن هنا نستخدم 'PyDriver' لتشغيل حلقة تجميع التجربة. يمكنك معرفة المزيد حول السائق وكلاء TF في منطقتنا السائقين البرنامج التعليمي .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
تدريب الوكيل
تتضمن حلقة التدريب كلاً من جمع البيانات من البيئة وتحسين شبكات الوكيل. على طول الطريق ، سنقوم من حين لآخر بتقييم سياسة الوكيل لنرى كيف نفعل ذلك.
سيستغرق تشغيل ما يلي حوالي 3 دقائق.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
التصور
المؤامرات
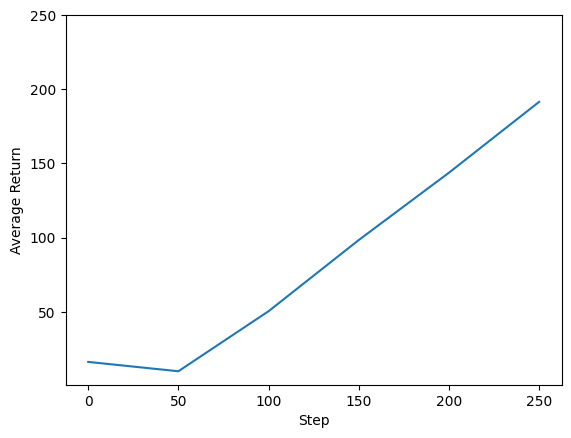
يمكننا رسم مخطط الإرجاع مقابل الخطوات العالمية لمعرفة أداء وكيلنا. في Cartpole-v0 ، والبيئة تمنح مكافأة قدرها +1 لكل خطوة الوقت يبقى القطب تصل، وبما أن الحد الأقصى لعدد الخطوات هو 200، وأقصى عائد ممكن أيضا 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
أشرطة فيديو
من المفيد تصور أداء الوكيل عن طريق عرض البيئة في كل خطوة. قبل القيام بذلك ، دعنا أولاً ننشئ وظيفة لتضمين مقاطع الفيديو في هذا الكولاب.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
يوضح الكود التالي سياسة الوكيل لبضع حلقات:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss