
কপিরাইট 2021 টিএফ-এজেন্ট লেখক।
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ভূমিকা
নিচের উদাহরনের মাধ্যমে দেখানো কিভাবে প্রশিক্ষণের নরম অভিনেতার ক্রিটিক উপর এজেন্ট Minitaur পরিবেশ।
আপনি মাধ্যমে কাজ করে থাকেন তাহলে DQN Colab এই খুব পরিচিত মনে করা উচিত নয়। উল্লেখযোগ্য পরিবর্তন অন্তর্ভুক্ত:
- DQN থেকে SAC এ এজেন্ট পরিবর্তন করা।
- Minitaur-এ প্রশিক্ষণ যা CartPole-এর চেয়ে অনেক বেশি জটিল পরিবেশ। Minitaur পরিবেশের লক্ষ্য একটি চতুর্মুখী রোবটকে এগিয়ে যাওয়ার জন্য প্রশিক্ষণ দেওয়া।
- ডিস্ট্রিবিউটেড রিইনফোর্সমেন্ট লার্নিং এর জন্য TF-Agents Actor-Learner API ব্যবহার করা।
API অভিজ্ঞতা রিপ্লে বাফার এবং পরিবর্তনশীল ধারক (প্যারামিটার সার্ভার) ব্যবহার করে বিতরণ করা ডেটা সংগ্রহ এবং একাধিক ডিভাইসে বিতরণ করা প্রশিক্ষণ উভয়কেই সমর্থন করে। API খুব সহজ এবং মডুলার হতে ডিজাইন করা হয়েছে. আমরা কাজে লাগাতে প্রতিধ্বনি উভয় রিপ্লে বাফার এবং পরিবর্তনশীল ধারক এবং জন্য মেমরি DistributionStrategy এপিআই জিপিইউ এবং TPUs বিতরণ প্রশিক্ষণের জন্য।
আপনি যদি নিম্নলিখিত নির্ভরতাগুলি ইনস্টল না করে থাকেন তবে চালান:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
সেটআপ
প্রথমে আমরা আমাদের প্রয়োজনীয় বিভিন্ন সরঞ্জাম আমদানি করব।
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
হাইপারপ্যারামিটার
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
পরিবেশ
RL-এর পরিবেশগুলি সেই কাজ বা সমস্যার প্রতিনিধিত্ব করে যা আমরা সমাধান করার চেষ্টা করছি। স্ট্যান্ডার্ড পরিবেশের সহজে ব্যবহার মেমরি-এজেন্ট এবং তৈরি করা যেতে পারে suites । আমরা বিভিন্ন আছে suites যেমন OpenAI জিম, Atari -এ, ডিএম নিয়ন্ত্রণ, ইত্যাদি উৎস থেকে পরিবেশের লোড একটি স্ট্রিং পরিবেশ নাম দেওয়া জন্য।
এখন Pybullet স্যুট থেকে Minituar পরিবেশ লোড করা যাক।
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

এই পরিবেশে লক্ষ্য হল এজেন্টকে একটি নীতি প্রশিক্ষিত করা যা Minitaur রোবটকে নিয়ন্ত্রণ করবে এবং এটি যত দ্রুত সম্ভব এগিয়ে যাবে। পর্বের শেষ 1000টি ধাপ এবং ফেরত হবে পুরো পর্ব জুড়ে পুরস্কারের সমষ্টি।
তথ্য আসুন বর্ণন পরিবেশ একটি হিসাবে প্রদান করে observation যা নীতি জেনারেট করতে ব্যবহার করা হবে actions ।
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
পর্যবেক্ষণ মোটামুটি জটিল. আমরা সমস্ত মোটরের জন্য কোণ, বেগ এবং টর্কের প্রতিনিধিত্বকারী 28টি মান পেয়েছি। বিনিময়ে পরিবেশের মধ্যে কর্মের জন্য 8 মান প্রত্যাশিত [-1, 1] । এই পছন্দসই মোটর কোণ হয়.
সাধারণত আমরা দুটি পরিবেশ তৈরি করি: একটি প্রশিক্ষণের সময় ডেটা সংগ্রহের জন্য এবং একটি মূল্যায়নের জন্য। পরিবেশগুলি বিশুদ্ধ পাইথনে লেখা হয় এবং নম্পি অ্যারে ব্যবহার করে, যা অ্যাক্টর লার্নার API সরাসরি ব্যবহার করে।
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
বিতরণ কৌশল
ডেটা সমান্তরালতা ব্যবহার করে একাধিক জিপিইউ বা টিপিইউ-এর মতো একাধিক ডিভাইস জুড়ে ট্রেনের ধাপ গণনা চালু করতে আমরা DistributionStrategy API ব্যবহার করি। ট্রেনের ধাপ:
- প্রশিক্ষণ তথ্য একটি ব্যাচ গ্রহণ
- এটিকে সমস্ত ডিভাইস জুড়ে বিভক্ত করে
- সামনের ধাপ গণনা করে
- একত্রিত করে এবং ক্ষতির MEAN গণনা করে
- পশ্চাদগামী পদক্ষেপ গণনা করে এবং একটি গ্রেডিয়েন্ট পরিবর্তনশীল আপডেট সম্পাদন করে
TF-Agents Learner API এবং DistributionStrategy API-এর সাহায্যে নিচের ট্রেনিং লজিকের কোনো পরিবর্তন না করেই GPU-তে ট্রেনের ধাপ (মিররড স্ট্র্যাটেজি ব্যবহার করে) থেকে TPU-তে (TPUStrategy ব্যবহার করে) স্যুইচ করা বেশ সহজ।
GPU সক্রিয় করা হচ্ছে
আপনি যদি একটি GPU তে চালানোর চেষ্টা করতে চান তবে আপনাকে প্রথমে নোটবুকের জন্য GPU গুলি সক্ষম করতে হবে:
- এডিট→নোটবুক সেটিংসে নেভিগেট করুন
- হার্ডওয়্যার অ্যাক্সিলারেটর ড্রপ-ডাউন থেকে GPU নির্বাচন করুন
একটি কৌশল বাছাই
ব্যবহার করুন strategy_utils একটি কৌশল তৈরি করতে। ফণার নীচে, পরামিতি পাস করা:
-
use_gpu = Falseআয়tf.distribute.get_strategy(), যা CPU- র ব্যবহার -
use_gpu = Trueআয়tf.distribute.MirroredStrategy(), যা সব জিপিইউ যে এক মেশিনে TensorFlow কাছে দৃশ্যমান ব্যবহার
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
সকল ভেরিয়েবল এবং এজেন্ট অধীনে নির্মিত করা প্রয়োজন strategy.scope() , যেমন আপনি নীচের দেখতে পাবেন।
প্রতিনিধি
একটি SAC এজেন্ট তৈরি করতে, আমাদের প্রথমে এমন নেটওয়ার্ক তৈরি করতে হবে যা এটি প্রশিক্ষণ দেবে। SAC একজন অভিনেতা-সমালোচক এজেন্ট, তাই আমাদের দুটি নেটওয়ার্কের প্রয়োজন হবে।
সমালোচক জন্য আমাদের সাথে মান অনুমান দেব Q(s,a) । অর্থাৎ, এটি একটি পর্যবেক্ষণ এবং একটি ক্রিয়া ইনপুট হিসাবে গ্রহণ করবে এবং এটি আমাদের একটি অনুমান দেবে যে প্রদত্ত রাজ্যের জন্য সেই ক্রিয়াটি কতটা ভাল ছিল।
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
আমরা একটি প্রশিক্ষণের জন্য এই সমালোচক ব্যবহার করবে actor নেটওয়ার্কের যা আমাদের একটি পর্যবেক্ষণ দেওয়া ক্রিয়া জেনারেট করতে অনুমতি দেবে।
ActorNetwork একটি TANH-squashed জন্য পরামিতি ভবিষ্যদ্বাণী করা হবে MultivariateNormalDiag বন্টন। এই বন্টনটি তখন নমুনা করা হবে, বর্তমান পর্যবেক্ষণের উপর শর্তযুক্ত, যখনই আমাদের অ্যাকশন তৈরি করতে হবে।
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
এই নেটওয়ার্কগুলি হাতে রেখে আমরা এখন এজেন্টকে ইনস্ট্যান্টিয়েট করতে পারি।
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
রিপ্লে বাফার
অর্ডার পরিবেশ থেকে সংগৃহীত ডেটা ট্র্যাক রাখতে করার জন্য, আমরা ব্যবহার করবে প্রতিধ্বনি , Deepmind দ্বারা একটি, দক্ষ প্রসার্য এবং সহজ-থেকে-ব্যবহার রিপ্লে সিস্টেম। এটি অভিনেতাদের দ্বারা সংগৃহীত অভিজ্ঞতার ডেটা সঞ্চয় করে এবং প্রশিক্ষণের সময় লার্নারের দ্বারা গ্রাস করা হয়।
এই টিউটোরিয়াল, এই কম গুরুত্বপূর্ণ max_size - কিন্তু ASYNC সংগ্রহ ও প্রশিক্ষণ দিয়ে একটি বিতরণ সেটিং, আপনি সম্ভবত নিয়ে পরীক্ষা করতে চান rate_limiters.SampleToInsertRatio , উদাহরণস্বরূপ 2 এবং 1000 এর মধ্যে একটি samples_per_insert কোথাও ব্যবহার করছে:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
রিপ্লে বাফার tensors এই সঞ্চিত হবে, যা ব্যবহার করে এজেন্ট থেকে প্রাপ্ত করা যাবে বর্ণনা চশমা ব্যবহার করে নির্মিত হয় tf_agent.collect_data_spec ।
যেহেতু এসএসি এজেন্ট উভয় বর্তমান এবং পরবর্তী পর্যবেক্ষণ ক্ষতি গনা প্রয়োজন, আমরা সেট sequence_length=2 ।
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
এখন আমরা Reverb রিপ্লে বাফার থেকে একটি TensorFlow ডেটাসেট তৈরি করি। প্রশিক্ষণের জন্য অভিজ্ঞতার নমুনা দেওয়ার জন্য আমরা এটি শিক্ষার্থীদের কাছে প্রেরণ করব।
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
নীতিমালা
মেমরি-এজেন্ট, নীতি আরএল মধ্যে নীতি মান ধারণা প্রতিনিধিত্ব: একটি প্রদত্ত time_step একটি কর্ম বা কর্মের উপর একটি বিতরণ উত্পাদন। প্রধান পদ্ধতি policy_step = policy.step(time_step) যেখানে policy_step একটি নামাঙ্কিত tuple হয় PolicyStep(action, state, info) । policy_step.action হয় action পরিবেশ প্রয়োগ করা, state stateful (RNN) নীতি ও প্রতিমন্ত্রী প্রতিনিধিত্ব করে info যেমন কর্ম লগ সম্ভাব্যতা যেমন অক্জিলিয়ারী তথ্য থাকতে পারে।
এজেন্ট দুটি নীতি ধারণ করে:
-
agent.policy- প্রধান নীতি মূল্যায়ন এবং স্থাপনার জন্য ব্যবহার করা হয়। -
agent.collect_policy- একটি দ্বিতীয় নীতি তথ্য সংগ্রহের জন্য ব্যবহার করা হয়।
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
নীতিগুলি এজেন্টদের থেকে স্বাধীনভাবে তৈরি করা যেতে পারে। উদাহরণ হিসেবে বলা যায়, ব্যবহার tf_agents.policies.random_py_policy একটি নীতি যা এলোমেলোভাবে প্রতিটি time_step জন্য একটি অ্যাকশন নির্বাচন করব তৈরি করুন।
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
অভিনেতা
অভিনেতা একটি নীতি এবং একটি পরিবেশের মধ্যে মিথস্ক্রিয়া পরিচালনা করে।
- অভিনেতা উপাদান (যেমন পরিবেশের একটি দৃষ্টান্ত ধারণ
py_environment) ও নীতি ভেরিয়েবল একটি কপি। - প্রতিটি অভিনেতা কর্মী পলিসি ভেরিয়েবলের স্থানীয় মান অনুযায়ী ডেটা সংগ্রহের ধাপগুলির একটি ক্রম চালায়।
- চলক আপডেট কল করার আগে স্পষ্টভাবে প্রশিক্ষণ লিপিতে পরিবর্তনশীল ধারক ক্লায়েন্ট উদাহরণস্বরূপ ব্যবহার করা হয়
actor.run() - পর্যবেক্ষণ করা অভিজ্ঞতা প্রতিটি ডেটা সংগ্রহের ধাপে রিপ্লে বাফারে লেখা হয়।
অভিনেতারা যখন ডেটা সংগ্রহের ধাপগুলি চালায়, তারা পর্যবেক্ষকের কাছে (স্টেট, অ্যাকশন, পুরষ্কার) এর ট্র্যাজেক্টোরি পাস করে, যা সেগুলিকে ক্যাশ করে এবং রিভার্ব রিপ্লে সিস্টেমে লিখে দেয়।
আমরা ফ্রেমের জন্য নির্দিষ্ট আবক্র সংরক্ষণ করছেন [(t0, T1) (T1, T2) (T2, T3), ...] কারণ stride_length=1 ।
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
আমরা এলোমেলো নীতির সাথে একজন অভিনেতা তৈরি করি এবং রিপ্লে বাফারের সাথে অভিজ্ঞতা সংগ্রহ করি।
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
প্রশিক্ষণের সময় আরও অভিজ্ঞতা সংগ্রহ করতে সংগ্রহ নীতির সাথে একজন অভিনেতাকে ইনস্ট্যান্ট করুন।
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
একজন অভিনেতা তৈরি করুন যা প্রশিক্ষণের সময় নীতি মূল্যায়ন করতে ব্যবহৃত হবে। আমরা মধ্যে পাস actor.eval_metrics(num_eval_episodes) পরে মেট্রিক্স লগইন করুন।
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
শিক্ষার্থীরা
লার্নার উপাদানটিতে এজেন্ট থাকে এবং রিপ্লে বাফার থেকে অভিজ্ঞতার ডেটা ব্যবহার করে নীতি ভেরিয়েবলের গ্রেডিয়েন্ট ধাপ আপডেট করে। এক বা একাধিক প্রশিক্ষণের ধাপের পর, শিক্ষার্থী পরিবর্তনশীল ধারকটিতে পরিবর্তনশীল মানগুলির একটি নতুন সেট পুশ করতে পারে।
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
মেট্রিক্স এবং মূল্যায়ন
আমরা সঙ্গে Eval অভিনেতার instantiated actor.eval_metrics যা নীতি মূল্যায়নের সময় সবচেয়ে বেশি ব্যবহৃত বৈশিষ্ট্যের মান তৈরি করে উপরে:
- গড় রিটার্ন। রিটার্ন হল একটি পর্বের জন্য একটি পরিবেশে একটি নীতি চালানোর সময় প্রাপ্ত পুরষ্কারের সমষ্টি এবং আমরা সাধারণত এটিকে কয়েকটি পর্বে গড় করি।
- গড় পর্বের দৈর্ঘ্য।
এই মেট্রিক্স তৈরি করতে আমরা অভিনেতা চালাই।
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
পরীক্ষা করে দেখুন মেট্রিক্স মডিউল বিভিন্ন বৈশিষ্ট্যের মান অন্যান্য মান বাস্তবায়নের জন্য।
এজেন্ট প্রশিক্ষণ
প্রশিক্ষণ লুপে পরিবেশ থেকে তথ্য সংগ্রহ এবং এজেন্টের নেটওয়ার্ক অপ্টিমাইজ করা উভয়ই জড়িত। পথের পাশাপাশি, আমরা কীভাবে কাজ করছি তা দেখতে আমরা মাঝে মাঝে এজেন্টের নীতি মূল্যায়ন করব।
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
ভিজ্যুয়ালাইজেশন
প্লট
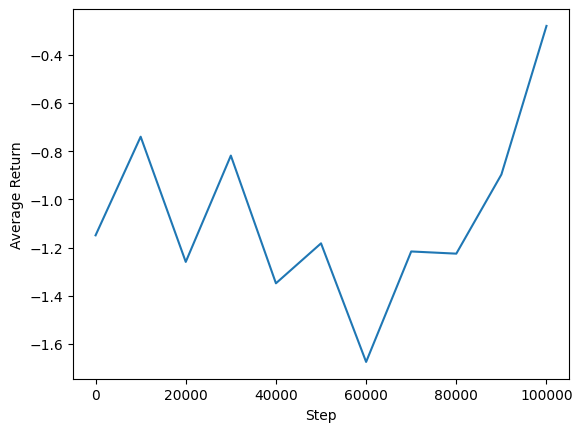
আমাদের এজেন্টের কর্মক্ষমতা দেখতে আমরা গড় রিটার্ন বনাম বিশ্বব্যাপী পদক্ষেপের পরিকল্পনা করতে পারি। ইন Minitaur , পুরস্কার ফাংশন কতদূর minitaur 1000 পদক্ষেপে পদচারনা এবং শক্তি ব্যয় penalizes উপর ভিত্তি করে।
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
ভিডিও
প্রতিটি ধাপে পরিবেশ রেন্ডার করে একটি এজেন্টের কর্মক্ষমতা কল্পনা করা সহায়ক। এটি করার আগে, আসুন প্রথমে এই কোল্যাবে ভিডিও এম্বেড করার জন্য একটি ফাংশন তৈরি করি।
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
নিম্নলিখিত কোডটি কয়েকটি পর্বের জন্য এজেন্টের নীতিকে কল্পনা করে:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)