
Copyright 2020 Gli autori degli agenti TF.
Iniziare
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Impostare
Se non hai installato le seguenti dipendenze, esegui:
pip install tf-agents
Importazioni
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
introduzione
Il problema Multi-Armed Bandit (MAB) è un caso speciale di Reinforcement Learning: un agente raccoglie ricompense in un ambiente intraprendendo alcune azioni dopo aver osservato uno stato dell'ambiente. La principale differenza tra RL generale e MAB è che in MAB, assumiamo che l'azione intrapresa dall'agente non influenzi lo stato successivo dell'ambiente. Pertanto, gli agenti non modellano le transizioni di stato, accreditano i premi alle azioni passate o "pianificano in anticipo" per arrivare a stati ricchi di premi.
Come in altri settori RL, l'obiettivo di un agente di MAB è quello di trovare una politica che raccoglie il più ricompensa possibile. Sarebbe un errore, tuttavia, cercare sempre di sfruttare l'azione che promette la ricompensa più alta, perché poi c'è la possibilità che ci perdiamo azioni migliori se non esploriamo abbastanza. Questo è il principale problema da risolvere in (MAB), spesso chiamato il dilemma esplorazione sfruttamento.
Ambienti Bandit, politiche e agenti per MAB si trovano nelle sottodirectory di tf_agents / banditi .
ambienti
Nel TF-Agenti, la classe ambientale serve il ruolo di dare informazioni sullo stato attuale (questo è chiamato osservazione o contesto), ricevendo un'azione come input, l'esecuzione di una transizione di stato, e l'output di una ricompensa. Questa classe si occupa anche di ripristinare quando termina un episodio, in modo che possa iniziare un nuovo episodio. Ciò si realizza chiamando il reset funzione quando uno stato è etichettato come "ultima" della puntata.
Per maggiori dettagli, vedere le TF-Agenti ambienti dimostrativi .
Come accennato in precedenza, MAB differisce dalla RL generale in quanto le azioni non influenzano l'osservazione successiva. Un'altra differenza è che in Bandits non ci sono "episodi": ogni passaggio temporale inizia con una nuova osservazione, indipendentemente dai passaggi temporali precedenti.
Per assicurarsi che le osservazioni sono indipendenti e per via astratta del concetto di episodi RL, introduciamo sottoclassi di PyEnvironment e TFEnvironment : BanditPyEnvironment e BanditTFEnvironment . Queste classi espongono due funzioni membro private che devono ancora essere implementate dall'utente:
@abc.abstractmethod
def _observe(self):
e
@abc.abstractmethod
def _apply_action(self, action):
La _observe funzione restituisce un'osservazione. Quindi, la politica sceglie un'azione basata su questa osservazione. Il _apply_action riceve l'azione come input e restituisce il premio corrispondente. Queste funzioni membro private sono chiamati con le funzioni reset e step , rispettivamente.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Le suddette intermedi implementa classe astratta PyEnvironment s' _reset e _step funzioni ed espone le funzioni astratte _observe e _apply_action da attuare da sottoclassi.
Una semplice classe di ambiente di esempio
La classe seguente fornisce un ambiente molto semplice per il quale l'osservazione è un numero intero casuale compreso tra -2 e 2, ci sono 3 possibili azioni (0, 1, 2) e la ricompensa è il prodotto dell'azione e dell'osservazione.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Ora possiamo usare questo ambiente per ottenere osservazioni e ricevere ricompense per le nostre azioni.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Ambienti TF
Si può definire un ambiente bandito dalla sottoclasse BanditTFEnvironment , o, in modo simile ad ambienti RL, si può definire una BanditPyEnvironment e avvolgerlo con TFPyEnvironment . Per semplicità, andiamo con quest'ultima opzione in questo tutorial.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Politiche
Una politica in un problema bandito funziona allo stesso modo come in un problema RL: fornisce un'azione (o una distribuzione di azioni), proposta un'osservazione come input.
Per maggiori dettagli, vedere il tutorial di TF-Agents politica .
Come con gli ambienti, ci sono due modi per costruire una politica: si può creare un PyPolicy e avvolgerlo con TFPyPolicy , o creare direttamente un TFPolicy . Qui scegliamo di andare con il metodo diretto.
Poiché questo esempio è abbastanza semplice, possiamo definire manualmente la politica ottimale. L'azione dipende solo dal segno dell'osservazione, 0 quando è negativo e 2 quando è positivo.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Ora possiamo richiedere un'osservazione dall'ambiente, chiamare la politica per scegliere un'azione, quindi l'ambiente restituirà la ricompensa:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Il modo in cui vengono implementati gli ambienti dei banditi garantisce che ogni volta che facciamo un passo, non riceviamo solo la ricompensa per l'azione che abbiamo intrapreso, ma anche l'osservazione successiva.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
agenti
Ora che abbiamo gli ambienti banditi e le policy bandit, è il momento di definire anche gli agenti bandit, che si occupano di modificare la policy in base ai campioni di addestramento.
L'API per gli agenti bandito non differisce da quella degli agenti RL: l'agente ha solo bisogno di attuare il _initialize e _train metodi, e definire una policy e una collect_policy .
Un ambiente più complicato
Prima di scrivere il nostro agente bandito, dobbiamo creare un ambiente un po' più difficile da capire. Per vivacizzare le cose solo un po ', l'ambiente prossimo sarà o sempre dare reward = observation * action o reward = -observation * action . Questo verrà deciso quando l'ambiente sarà inizializzato.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Una politica più complicata
Un ambiente più complicato richiede una politica più complicata. Abbiamo bisogno di una politica che rilevi il comportamento dell'ambiente sottostante. Ci sono tre situazioni che la politica deve gestire:
- L'agente non ha ancora rilevato quale versione dell'ambiente è in esecuzione.
- L'agente ha rilevato che la versione originale dell'ambiente è in esecuzione.
- L'agente ha rilevato che la versione capovolta dell'ambiente è in esecuzione.
Definiamo un tf_variable nome _situation per memorizzare queste informazioni codificate come valori in [0, 2] , quindi effettuare la politica di conseguenza comportarsi.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
L'agente
Ora è il momento di definire l'agente che rileva il segno dell'ambiente e imposta la politica in modo appropriato.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
Nel codice sopra, l'agente definisce la politica, e la variabile situation è condivisa dall'agente e la politica.
Inoltre, il parametro experience del _train funzione è una traiettoria:
traiettorie
Nel TF-agenti, trajectories sono chiamati tuple che contengono campioni dai passaggi precedenti adottate. Questi campioni vengono quindi utilizzati dall'agente per addestrare e aggiornare la politica. In RL, le traiettorie devono contenere informazioni sullo stato corrente, sullo stato successivo e se l'episodio corrente è terminato. Poiché nel mondo Bandit non abbiamo bisogno di queste cose, abbiamo impostato una funzione di supporto per creare una traiettoria:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Formazione di un agente
Ora tutti i pezzi sono pronti per addestrare il nostro agente bandito.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Dall'output si può vedere che dopo il secondo passaggio (a meno che l'osservazione non sia stata 0 nel primo passaggio), la politica sceglie l'azione nel modo giusto e quindi il premio raccolto è sempre non negativo.
Un vero esempio di bandito contestuale
Nel resto di questo tutorial, usiamo le pre-implementati gli ambienti e gli agenti della biblioteca TF-Agenti Bandits.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Ambiente stocastico stazionario con funzioni di payoff lineare
L'ambiente utilizzato in questo esempio è lo StationaryStochasticPyEnvironment . Questo ambiente prende come parametro una funzione (solitamente rumorosa) per dare osservazioni (contesto), e per ogni braccio assume una funzione (anche rumorosa) che calcola la ricompensa in base all'osservazione data. Nel nostro esempio, campioniamo il contesto in modo uniforme da un cubo d-dimensionale e le funzioni di ricompensa sono funzioni lineari del contesto, più del rumore gaussiano.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
L'agente LinUCB
L'agente sotto implementa l' LinUCB algoritmo.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Metrica del rammarico
Metrica più importante Bandits' è rimpianto, calcolato come differenza tra il premio raccolti dall'agente e la ricompensa prevista di una politica di oracolo che ha accesso alle funzioni di ricompensa dell'ambiente. Il RegretMetric necessita quindi funzione baseline_reward_fn che calcola il premio atteso realizzabile proposta un'osservazione. Per il nostro esempio, dobbiamo prendere il massimo degli equivalenti senza rumore delle funzioni di ricompensa che abbiamo già definito per l'ambiente.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Addestramento
Ora mettiamo insieme tutti i componenti che abbiamo introdotto sopra: l'ambiente, la politica e l'agente. Corriamo la politica sui dati ambiente e la formazione di uscita con l'aiuto di un pilota, e formiamo l'agente sui dati.
Si noti che ci sono due parametri che insieme specificano il numero di passaggi eseguiti. num_iterations specifica quante volte si corre il ciclo trainer, mentre il conducente avrà steps_per_loop passi per ogni iterazione. Il motivo principale per mantenere entrambi questi parametri è che alcune operazioni vengono eseguite per iterazione, mentre altre vengono eseguite dal driver in ogni fase. Ad esempio, l'agente train funzione viene richiamata una sola volta per ogni iterazione. Il compromesso qui è che se ci alleniamo più spesso la nostra politica è "più fresca", d'altra parte, la formazione in lotti più grandi potrebbe essere più efficiente in termini di tempo.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
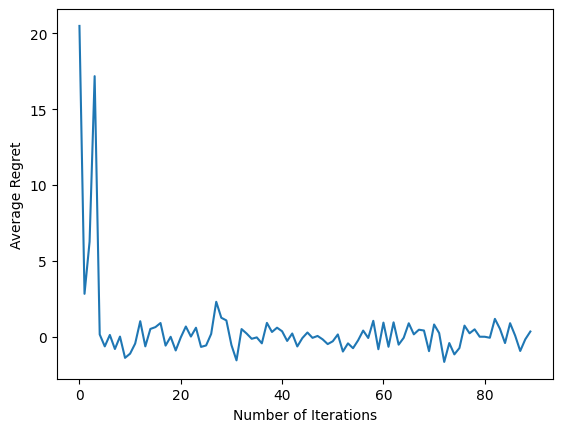
Dopo aver eseguito l'ultimo frammento di codice, il grafico risultante (si spera) mostra che il rimpianto medio sta diminuendo man mano che l'agente viene addestrato e la politica migliora nel capire quale sia l'azione giusta, data l'osservazione.
Qual è il prossimo?
Per vedere esempi di più di lavoro, si prega di vedere il banditi / agenti / esempi di directory che ha esempi ready-to-run per gli agenti e ambienti diversi.
La libreria TF-Agents è anche in grado di gestire banditi multi-armati con funzionalità per braccio. A tal fine, rimandiamo il lettore al bandito per-braccio esercitazione .