
זכויות יוצרים 2020 מחברי TF-Agents.
להתחיל
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
להכין
אם לא התקנת את התלויות הבאות, הרץ:
pip install tf-agents
יבוא
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
מבוא
בעיית השודדים הרב-זרועיים (MAB) היא מקרה מיוחד של למידת חיזוק: סוכן אוסף תגמולים בסביבה על ידי נקיטת פעולות מסוימות לאחר צפייה במצב מסוים של הסביבה. ההבדל העיקרי בין RL כללי ל-MAB הוא שב-MAB, אנו מניחים שהפעולה שננקטת על ידי הסוכן אינה משפיעה על המצב הבא של הסביבה. לכן, סוכנים אינם דוגלים במעברי מדינה, אינם מעניקים תגמולים לפעולות העבר או "מתכננים מראש" כדי להגיע למדינות עתירות תגמולים.
כמו בתחומים אחרים RL, המטרה של סוכן MAB היא למצוא מדיניות שאוסף כפרס האפשר. זאת תהיה טעות, עם זאת, לנסות תמיד לנצל את הפעולה שמבטיחה את התגמול הגבוה ביותר, כי אז יש סיכוי שנפספס פעולות טובות יותר אם לא נחקור מספיק. זוהי הבעיה העיקרית להיפתר (MAB), המכונה לעתים קרובות את הדילמה-ניצול חקר.
סביבות Bandit, מדיניות, וסוכני MAB ניתן למצוא תיקיות משנה של tf_agents / שודדים .
סביבות
In-סוכני TF, כיתת הסביבה משרתת את התפקיד של מתן מידע על המצב הנוכחי (זה נקרא תצפית או הקשר), קבלת פעולה כקלט, ביצוע מעבר למדינה, וכן פלט פרס. שיעור זה גם דואג לאפס כאשר פרק מסתיים, כדי שניתן יהיה להתחיל פרק חדש. זה ממומש על ידי קריאת reset פונקציה כאשר מדינה שכותרתו "אחרון" של הפרק.
לפרטים נוספים, ראה הדרכת סביבות סוכני TF .
כפי שהוזכר לעיל, MAB שונה מ-RL כללי בכך שפעולות אינן משפיעות על התצפית הבאה. הבדל נוסף הוא שב-Bandits, אין "פרקים": כל צעד זמן מתחיל בתצפית חדשה, ללא תלות בצעדי זמן קודמים.
כדי לבצע תצפיות בטוחות הם עצמאיים כדי משם להפשיט את מושג פרק RL, אנו מציגים subclasses של PyEnvironment ו TFEnvironment : BanditPyEnvironment ו BanditTFEnvironment . מחלקות אלו חושפות שתי פונקציות חבר פרטיות שנותרו ליישם על ידי המשתמש:
@abc.abstractmethod
def _observe(self):
ו
@abc.abstractmethod
def _apply_action(self, action):
_observe הפונקציה מחזירה תצפית. לאחר מכן, המדיניות בוחרת פעולה על סמך תצפית זו. _apply_action מקבלת פעולה כקלט, ומחזירה את הפרס המקביל. פונקציות חבר פרטיות אלה נקראות על ידי פונקציות reset ו step , בהתאמה.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
אמור לעיל סככה בכיתה מופשטת ביניים PyEnvironment של _reset ו _step הפונקציות וחושף את הפונקציות המופשטות _observe ו _apply_action להיות מיושמים על ידי subclasses.
כיתת סביבה פשוטה לדוגמה
המחלקה הבאה נותנת סביבה מאוד פשוטה שבה התצפית היא מספר שלם אקראי בין -2 ל-2, ישנן 3 פעולות אפשריות (0, 1, 2), והתגמול הוא תוצר הפעולה והתצפית.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
כעת אנו יכולים להשתמש בסביבה הזו כדי לקבל תצפיות, ולקבל תגמולים על הפעולות שלנו.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
סביבות TF
אפשר להגדיר סביבת הבנדיט ידי subclassing BanditTFEnvironment , או, באופן דומה לסביבות RL, אפשר להגדיר BanditPyEnvironment ועוטפים אותו עם TFPyEnvironment . למען הפשטות, אנו הולכים עם האפשרות השנייה במדריך זה.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
מדיניות
מדיניות בתוך בעיית הבנדיט עובד באותה צורה כמו בעיה RL: הוא מספק פעולה (או חלוקה של פעולות), נתון תצפית כקלט.
לפרטים נוספים, ראה הדרכה המדיניות-סוכני TF .
כמו עם סביבות, יש שתי דרכים לבנות מדיניות: אפשר ליצור PyPolicy ועוטפים אותו עם TFPyPolicy , או ישירות ליצור TFPolicy . כאן אנו בוחרים ללכת בשיטה הישירה.
מכיוון שדוגמה זו די פשוטה, אנו יכולים להגדיר את המדיניות האופטימלית באופן ידני. הפעולה תלויה רק בסימן התצפית, 0 כאשר הוא שלילי ו-2 כאשר הוא חיובי.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
כעת נוכל לבקש תצפית מהסביבה, לקרוא למדיניות לבחור פעולה, ואז הסביבה תוציא את התגמול:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
אופן יישום סביבות השודדים מבטיח שבכל פעם שאנחנו עושים צעד, אנחנו לא רק מקבלים את הפרס על הפעולה שעשינו, אלא גם את התצפית הבאה.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
סוכנים
עכשיו, כשיש לנו סביבות שודדים ומדיניות שודדים, הגיע הזמן להגדיר גם סוכני שודדים, שדואגים לשנות את המדיניות על סמך דגימות אימון.
ה- API עבור סוכנים הבנדיט אינה שונה מזו של סוכנים RL: הסוכן רק צריך ליישם את _initialize ו _train שיטות, ולהגדיר policy לבין collect_policy .
סביבה מסובכת יותר
לפני שנכתוב את סוכן השודדים שלנו, אנחנו צריכים שתהיה לנו סביבה שקצת יותר קשה להבין אותה. כדי לתבל את הדברים קצת, הסביבה הבאה או תמיד לתת reward = observation * action או reward = -observation * action . זה יוחלט עם אתחול הסביבה.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
מדיניות מסובכת יותר
סביבה מסובכת יותר מחייבת מדיניות מסובכת יותר. אנחנו צריכים מדיניות שמזהה את התנהגות הסביבה הבסיסית. ישנם שלושה מצבים שהפוליסה צריכה לטפל בהם:
- הסוכן לא זיהה יודע עדיין איזו גרסה של הסביבה פועלת.
- הסוכן זיהה שהגרסה המקורית של הסביבה פועלת.
- הסוכן זיהה שהגרסה ההפוכה של הסביבה פועלת.
אנו מגדירים tf_variable בשם _situation לאחסן את המידע הזה מקודד כערכים [0, 2] , ולאחר מכן לבצע את מתנהגים מדיניות בהתאם.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
הסוכן
כעת הגיע הזמן להגדיר את הסוכן שיזהה את סימן הסביבה וקובע את המדיניות כראוי.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
בקוד למעלה, הסוכן מגדיר את המדיניות, ואת משתנת situation משותף הסוכן ואת המדיניות.
כמו כן, פרמטר experience של _train הפונקציה הוא מסלול:
מסלולים
In-סוכני TF, trajectories נקראים tuples המכיל דגימות מן השלבים קודמים שצולמו. דגימות אלה משמשות לאחר מכן את הסוכן כדי להכשיר ולעדכן את המדיניות. ב-RL, המסלולים חייבים להכיל מידע על המצב הנוכחי, המצב הבא והאם הפרק הנוכחי הסתיים. מכיוון שבעולם השודדים אנחנו לא צריכים את הדברים האלה, הגדרנו פונקציית עוזר ליצירת מסלול:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
הכשרת סוכן
עכשיו כל החלקים מוכנים לאימון סוכן השודדים שלנו.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
מהפלט ניתן לראות שלאחר השלב השני (אלא אם כן התצפית הייתה 0 בשלב הראשון), הפוליסה בוחרת את הפעולה בצורה הנכונה וכך התגמול שנגבה תמיד אינו שלילי.
דוגמה של שודד קונטקסטואלי אמיתי
בשאר הדרכה זו, אנו משתמשים לפועל מראש הסביבות ו סוכנים של ספריית Bandits-סוכני TF.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
סביבה סטוכסטית נייחת עם פונקציות תשלום ליניאריות
הסביבה שמוצגת בדוגמה זו היא StationaryStochasticPyEnvironment . סביבה זו לוקחת כפרמטר פונקציה (בדרך כלל רועשת) למתן תצפיות (הקשר), ולכל זרוע לוקחת פונקציה (גם רועשת) שמחשבת את התגמול על סמך התצפית הנתונה. בדוגמה שלנו, אנו דוגמים את ההקשר באופן אחיד מקובייה דו-ממדית, ופונקציות התגמול הן פונקציות ליניאריות של ההקשר, בתוספת קצת רעש גאוסי.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
סוכן LinUCB
הסוכן להלן מיישם את LinUCB האלגוריתם.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
מדד חרטה
המדד חשוב ביותר של השודדים הוא חרטה, מחושב כהפרש בין התגמול שנאסף על ידי הסוכן ואת הפרס צפוי של מדיניות אורקל שיש לו גישה לפונקציות התגמול של הסביבה. RegretMetric ובכך צריך פונקציה baseline_reward_fn המחשבת את הפרס הצפוי השגה הטובה נתון תצפית. לדוגמה שלנו, עלינו לקחת את המקסימום של המקבילות ללא רעש של פונקציות התגמול שכבר הגדרנו עבור הסביבה.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
הַדְרָכָה
כעת ריכזנו את כל המרכיבים שהצגנו לעיל: הסביבה, המדיניות והסוכן. אנו מפעילים המדיניות על נתון אימוני הסביבה פלט בעזרת נהג, ולאמן הסוכן על הנתונים.
שימו לב שיש שני פרמטרים המציינים יחד את מספר הצעדים שננקטו. num_iterations מציין כמה פעמים אנחנו רצים בלולאה המאמנת, בעוד הנהג ייקח steps_per_loop צעדים לכול איטרציה. הסיבה העיקרית מאחורי שמירת שני הפרמטרים הללו היא שחלק מהפעולות נעשות לפי איטרציה, בעוד שחלקן נעשות על ידי הנהג בכל שלב. לדוגמה, של סוכן train פונקציה נקראת פעם אחת בלבד לכל איטרציה. הפשרה כאן היא שאם נתאמן לעתים קרובות יותר, המדיניות שלנו היא "רעננה יותר", מצד שני, אימון בקבוצות גדולות יותר עשוי להיות יעיל יותר בזמן.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
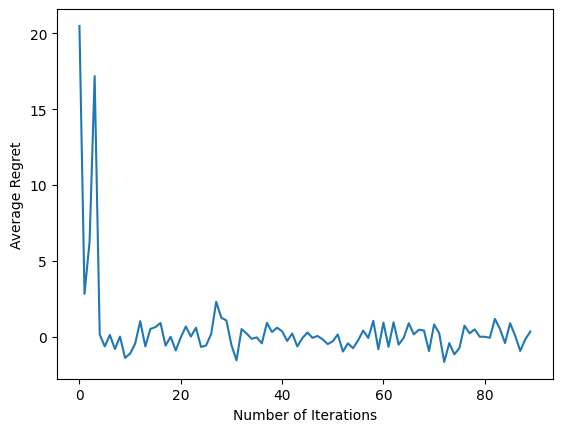
לאחר הפעלת קטע הקוד האחרון, העלילה שהתקבלה (בתקווה) מראה שהחרטה הממוצעת יורדת ככל שהסוכן מאומן והמדיניות משתפרת בבירור מהי הפעולה הנכונה, בהתחשב בתצפית.
מה הלאה?
כדי לראות דוגמא עבודה יותר, עיין שודדים / סוכנים / דוגמא במדריך כי יש מוכנות לרוץ דוגמא לסוכנים וסביבות שונים.
ספריית TF-Agents מסוגלת גם לטפל בשודדים מרובי זרועות עם תכונות לכל זרוע. לשם כך, אנו מפנים את הקורא הבנדיט לכול זרוע ההדרכה .