
Авторские права 2020 Авторы TF-Agents.
Начать
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Настраивать
Если вы не установили следующие зависимости, запустите:
pip install tf-agents
Импорт
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Введение
Проблема многорукого бандита (MAB) - это частный случай обучения с подкреплением: агент собирает награды в среде, предпринимая определенные действия после наблюдения за некоторым состоянием окружающей среды. Основное различие между обычным RL и MAB заключается в том, что в MAB мы предполагаем, что действие, предпринимаемое агентом, не влияет на следующее состояние среды. Следовательно, агенты не моделируют переходы между состояниями, кредитные вознаграждения за прошлые действия и не «планируют заранее», чтобы перейти к состояниям, богатым вознаграждением.
Как и в других областях RL, цель в МАБ агента найти политику , которая собирает столько награды , насколько это возможно. Однако было бы ошибкой всегда пытаться использовать действие, обещающее наивысшую награду, потому что тогда есть шанс, что мы упустим лучшие действия, если недостаточно исследуем. Это главная проблема , которую необходимо решить в (МАБ), который часто называют разведка-добыча дилеммой.
Бандитские среды, политика и агенты для МАВ могут быть найдены в поддиректории tf_agents / бандитов .
Среды
В TF-агентах, класс окружающей среды играет роль предоставления информации о текущем состоянии (это называется наблюдением или контекстом), получая действие в качестве входных данных, выполняя переход состояния, и выводит вознаграждение. Этот класс также выполняет сброс настроек по окончании эпизода, чтобы можно было начать новый эпизод. Это осуществляется путем вызова reset функции , когда состояние обозначается как «последний» эпизод.
Для получения более подробной информации, обратитесь к TF-агенты сред учебник .
Как упоминалось выше, MAB отличается от обычного RL тем, что действия не влияют на следующее наблюдение. Еще одно отличие состоит в том, что в Bandits нет «эпизодов»: каждый временной шаг начинается с нового наблюдения, независимо от предыдущих временных шагов.
Для того, чтобы убедиться , что наблюдения независимы и абстрагироваться от понятия эпизодов RL, мы вводим подклассы PyEnvironment и TFEnvironment : BanditPyEnvironment и BanditTFEnvironment . Эти классы предоставляют две закрытые функции-члены, которые еще предстоит реализовать пользователю:
@abc.abstractmethod
def _observe(self):
и
@abc.abstractmethod
def _apply_action(self, action):
_observe функция возвращает наблюдение. Затем политика выбирает действие на основе этого наблюдения. _apply_action принимает это действие в качестве входных данных, и возвращает соответствующее вознаграждение. Эти частные функции - члены вызываются функции reset и step , соответственно.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Вышеприведенного промежуточного инвентарь абстрактного класса PyEnvironment «s _reset и _step функция и предоставляет абстрактные функции _observe и _apply_action быть реализованы подклассами.
Простой пример класса среды
Следующий класс дает очень простую среду, для которой наблюдение представляет собой случайное целое число от -2 до 2, есть 3 возможных действия (0, 1, 2), а награда является результатом действия и наблюдения.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Теперь мы можем использовать эту среду, чтобы получать наблюдения и получать вознаграждение за свои действия.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Среды TF
Можно определить окружение бандита по подклассов BanditTFEnvironment , или, подобно среде RL, можно определить BanditPyEnvironment и обернуть его TFPyEnvironment . Для простоты в этом уроке мы выберем последний вариант.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Политики
Политика в задаче бандитской работает точно так же , как и в задаче RL: она обеспечивает действие (или распределение акций), учитывая наблюдение в качестве входных данных.
Для получения более подробной информации см учебник TF-агентов политики .
Как и в условиях, существует два способа построения политики: Можно создать PyPolicy и обернуть его с TFPyPolicy , или непосредственно создать TFPolicy . Здесь мы выбрали прямой метод.
Поскольку этот пример довольно прост, мы можем определить оптимальную политику вручную. Действие зависит только от знака наблюдения: 0 - если отрицательно, а 2 - положительно.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Теперь мы можем запросить наблюдение из среды, вызвать политику для выбора действия, затем среда выдаст награду:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Способ реализации окружения бандитов гарантирует, что каждый раз, когда мы делаем шаг, мы не только получаем награду за совершенное действие, но и за следующее наблюдение.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Агенты
Теперь, когда у нас есть бандитская среда и бандитские политики, пришло время также определить бандитских агентов, которые позаботятся об изменении политики на основе обучающих выборок.
API для бандитских агентов не отличается от агентов RL: агент просто должен реализовать _initialize и _train методов, а также определить policy и collect_policy .
Более сложная среда
Прежде чем мы напишем нашего бандитского агента, нам нужно создать среду, которую немного сложнее понять. Для того, чтобы оживить вещи только немного, следующая среда либо всегда будет давать reward = observation * action или reward = -observation * action . Это будет принято при инициализации среды.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Более сложная политика
Более сложная среда требует более сложной политики. Нам нужна политика, которая определяет поведение базовой среды. Политика должна обрабатывать три ситуации:
- Агент еще не обнаружил, знает, какая версия среды запущена.
- Агент обнаружил, что запущена исходная версия среды.
- Агент обнаружил, что перевернутая версия среды запущена.
Определим tf_variable имени _situation хранить эту информацию , закодированную в виде значений в [0, 2] , а затем сделайте ведут себя политики соответственно.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
Агент
Теперь пора определить агента, который обнаруживает признаки среды и соответствующим образом устанавливает политику.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
В приведенном выше коде, агент определяет политику, и переменная situation является общим агентом и политики.
Кроме того , параметр experience в _train функции траектории:
Траектории
В TF-агентах, trajectories называются кортежи , которые содержат образцы из предыдущих шагов. Затем эти образцы используются агентом для обучения и обновления политики. В RL траектории должны содержать информацию о текущем состоянии, следующем состоянии и о том, закончился ли текущий эпизод. Поскольку в мире бандитов нам эти вещи не нужны, мы настраиваем вспомогательную функцию для создания траектории:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Обучение агента
Теперь все детали готовы к обучению нашего бандитского агента.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Из выходных данных видно, что после второго шага (если только наблюдение не было 0 на первом шаге), политика выбирает действие правильным образом, и, таким образом, полученное вознаграждение всегда неотрицательно.
Пример реального контекстного бандита
В остальной части этого урока мы используем предварительно Реализуемые среды и агент библиотеки ТФА Агенты Бандитов.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Стационарная стохастическая среда с линейными функциями выплат.
Среда используется в этом примере является StationaryStochasticPyEnvironment . Эта среда принимает в качестве параметра (обычно шумную) функцию для предоставления наблюдений (контекст), и для каждой руки принимает (также зашумленную) функцию, которая вычисляет вознаграждение на основе данного наблюдения. В нашем примере мы выбираем контекст равномерно из d-мерного куба, а функции вознаграждения являются линейными функциями контекста плюс некоторый гауссов шум.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
Агент LinUCB
Агент ниже реализует LinUCB алгоритм.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Метрика сожаления
Наиболее важный показатель бандитского сожаление, рассчитываются как разница между вознаграждением , собранным агентом и ожидаемой наградой политики оракула , который имеет доступ к награде функциям окружающей среды. RegretMetric , таким образом , нуждается в функции baseline_reward_fn , которая вычисляет наилучшую достижимую ожидаемую награду данного наблюдения. В нашем примере нам нужно взять максимум бесшумных эквивалентов функций вознаграждения, которые мы уже определили для среды.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Обучение
Теперь мы собрали вместе все компоненты, которые мы представили выше: среду, политику и агент. Мы проводим политику в отношении данных окружающей среды и выхода подготовки с помощью водителя, и обучить агент по данным.
Обратите внимание, что есть два параметра, которые вместе определяют количество сделанных шагов. num_iterations определяет , сколько раз мы запускаем цикл тренера, в то время как водитель будет принимать steps_per_loop шагов на итерацию. Основная причина сохранения обоих этих параметров заключается в том, что некоторые операции выполняются за итерацию, а некоторые - драйвером на каждом шаге. Так , например, агент train функция вызывается только один раз в итерацию. Компромисс здесь заключается в том, что если мы тренируемся чаще, то наша политика «свежее», с другой стороны, обучение более крупными партиями может быть более эффективным по времени.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
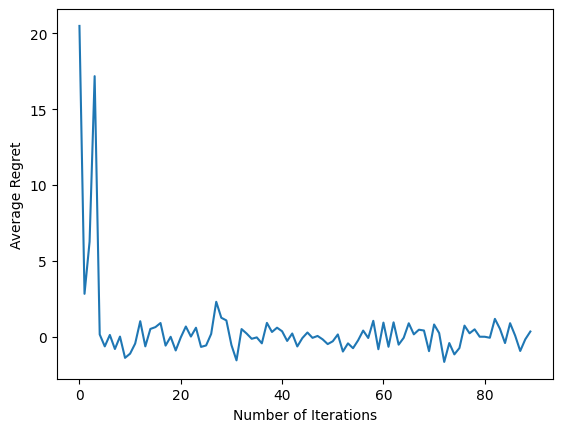
После выполнения последнего фрагмента кода полученный график (надеюсь) показывает, что среднее количество сожалений уменьшается по мере того, как агент обучается, а политика становится лучше в определении правильного действия с учетом наблюдения.
Что дальше?
Чтобы увидеть больше рабочие примеры, пожалуйста , см бандитов / агентов / примеры каталога , который имеет готовые к запуску примеров для различных агентов и сред.
Библиотека TF-Agents также способна обрабатывать многорукие бандиты с индивидуальными функциями. С этой целью, мы отсылаем читателя к за-руку бандита учебник .