
کلاس نهایی عمومی DynamicPartition
"داده" را با استفاده از شاخص های "پارتیشن" به تانسورهای "تعداد_پارتیشن" تقسیم می کند.
برای هر تاپل فهرست «js» با اندازه «partitions.ndim»، برش «داده[js، ...]» بخشی از «خروجیها[پارتیشنها[js]]» میشود. برشهای با «پارتیشن[js] = i» در «خروجیها[i]» به ترتیب واژگانی «js» قرار میگیرند، و بعد اول «خروجیها[i]» تعداد ورودیهای «پارتیشنها» برابر است با "من". در جزئیات،
outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:]
outputs[i] = pack([data[js, ...] for js if partitions[js] == i])
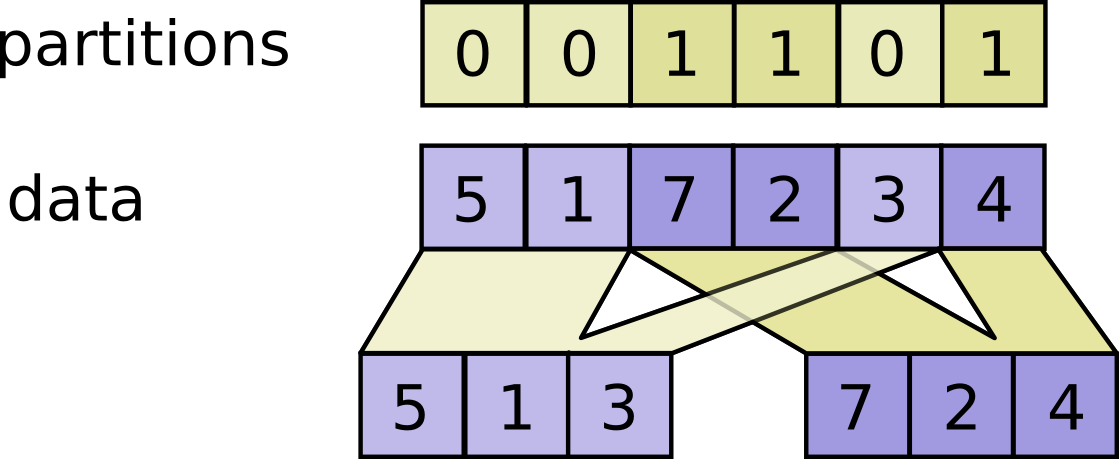
به عنوان مثال:
# Scalar partitions.
partitions = 1
num_partitions = 2
data = [10, 20]
outputs[0] = [] # Empty with shape [0, 2]
outputs[1] = [[10, 20]]
# Vector partitions.
partitions = [0, 0, 1, 1, 0]
num_partitions = 2
data = [10, 20, 30, 40, 50]
outputs[0] = [10, 20, 50]
outputs[1] = [30, 40]
افزایش می دهد: * "InvalidArgumentError" در موارد زیر: - اگر پارتیشن ها در محدوده "[0، num_partiions)" نیستند - اگر "partitions.shape" با پیشوند آرگومان "data.shape" مطابقت ندارد.
روش های عمومی
| استاتیک <T> DynamicPartition <T> | |
| Iterator< عملوند <T>> | اشاره گر () |
| لیست< خروجی <T>> | خروجی ها () |
روش های ارثی
روش های عمومی
ایجاد پارتیشن داینامیک استاتیک عمومی <T> ( دامنه دامنه ، داده های عملوند <T>، پارتیشن های عملوند <عدد صحیح>، پارتیشن های طولانی numPartition)
روش Factory برای ایجاد کلاسی که یک عملیات DynamicPartition جدید را بسته بندی می کند.
مولفه های
| محدوده | محدوده فعلی |
|---|---|
| پارتیشن ها | هر شکلی شاخصهایی در محدوده «[0، num_partitions)». |
| numپارتیشن ها | تعداد پارتیشن های خروجی |
برمی گرداند
- یک نمونه جدید از DynamicPartition