
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten poradnik bada częściowo lokalnym uczenie stowarzyszonego, gdzie niektóre parametry klient nigdy nie są łączone na serwerze. Jest to przydatne w przypadku modeli z parametrami specyficznymi dla użytkownika (np. modele faktoryzacji macierzy) oraz do szkolenia w ustawieniach o ograniczonej komunikacji. Budujemy na pojęć wprowadzonych w Federacji Learning dla obrazu klasyfikowania poradnik; jak w tym tutorialu, wprowadzamy API wysokiego poziomu w tff.learning dla stowarzyszonym szkolenia i oceny.
Zaczynamy od motywowania częściowo lokalnym uczenie stowarzyszonego na faktoryzacji macierzy . Opisujemy Federalne Odbudowy ( papier , blogu ), praktyczny algorytm częściowo lokalnym uczenia stowarzyszonym w skali. Przygotowujemy zestaw danych MovieLens 1M, budujemy częściowo lokalny model, szkolimy go i oceniamy.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Tło: faktoryzacja macierzy
Matrix faktoryzacji był historycznie popularne techniki uczenia rekomendacje i osadzanie reprezentacje przedmiotów oparte na interakcji użytkownika. Kanonicznym przykładem jest zalecenie film, gdzie istnieją \(n\) użytkowników i \(m\) filmy, a użytkownicy nie oceniono kilka filmów. Biorąc pod uwagę użytkownika, wykorzystujemy jego historię ocen i oceny podobnych użytkowników, aby przewidzieć oceny użytkownika dla filmów, których nie oglądali. Jeśli mamy model, który może przewidywać oceny, łatwo jest polecić użytkownikom nowe filmy, które im się spodobają.
Do tego zadania, jest to przydatne do reprezentowania ocen użytkowników jako \(n \times m\) macierzy \(R\):

Ta macierz jest na ogół rzadka, ponieważ użytkownicy zazwyczaj widzą tylko niewielką część filmów w zbiorze danych. Wyjście faktoryzacji macierzy są dwie matryce: AN \(n \times k\) matrycy \(U\) stanowiących \(k\)zanurzeń wymiarową dla każdego użytkownika, oraz \(m \times k\) matrycy \(I\) stanowiących \(k\)wymiarową zanurzeń artykuł dla każdej pozycji. Najprostszym Celem szkolenia jest zapewnienie, że kropka iloczyn użytkowników i pozycja zanurzeń prognozują obserwowanych ocen \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Jest to równoważne minimalizacji błędu średniokwadratowego między zaobserwowanymi ocenami a ocenami przewidywanymi na podstawie iloczynu skalarnego odpowiednich osadzonych użytkowników i elementów. Innym sposobem, aby zinterpretować to, że zapewnia to \(R \approx UI^T\) dla znanych ocen, stąd „faktoryzacji macierzy”. Jeśli jest to mylące, nie martw się — nie będziemy musieli znać szczegółów faktoryzacji macierzy do końca samouczka.
Eksploracja danych MovieLens
Zacznijmy od ładowania MovieLens 1M danych, która składa się z 1,000,209 ocen filmowe z 6040 użytkowników na 3706 filmów.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Załadujmy i zbadajmy kilka ramek danych Pandas DataFrames zawierających dane o ocenach i filmach.
ratings_df, movies_df = load_movielens_data()
Widzimy, że każdy przykład oceny ma ocenę od 1 do 5, odpowiedni UserID, odpowiedni MovieID i znacznik czasu.
ratings_df.head()
Każdy film ma tytuł i potencjalnie wiele gatunków.
movies_df.head()
Zawsze dobrze jest zrozumieć podstawowe statystyki zbioru danych:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
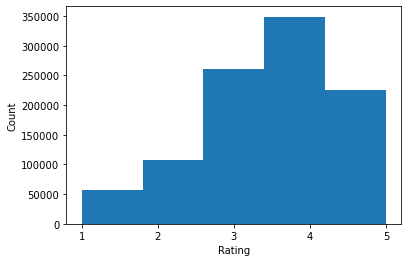
Average rating: 3.581564453029317 Median rating: 4.0
Potrafimy też kreślić najpopularniejsze gatunki filmowe.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
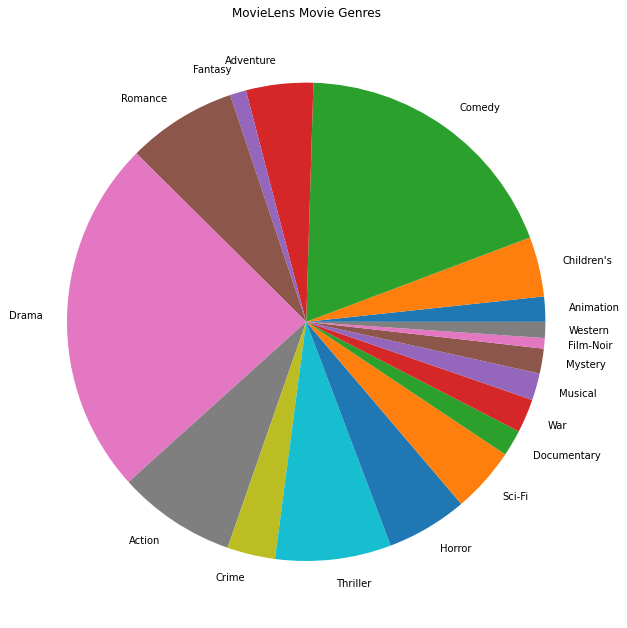
Dane te są w naturalny sposób podzielone na oceny różnych użytkowników, więc spodziewalibyśmy się pewnej heterogeniczności danych między klientami. Poniżej przedstawiamy najczęściej oceniane gatunki filmowe dla różnych użytkowników. Możemy zaobserwować znaczne różnice między użytkownikami.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Wstępne przetwarzanie danych MovieLens
Będziemy teraz przygotować zestaw danych MovieLens jako lista tf.data.Dataset s reprezentujący dane każdego użytkownika do użytku z TFF.
Realizujemy dwie funkcje:
-
create_tf_datasets: trwa rekomendację DataFrame i tworzy listę użytkownik-splittf.data.Datasets. -
split_tf_datasets: pobiera listę zestawów danych i dzieli je na pociąg / val / test przez użytkownika, więc Val zestawy / test zawiera tylko ocen od użytkowników niewidocznych podczas treningu. Zazwyczaj w standardzie scentralizowanego faktoryzacji macierzy faktycznie podzielone tak, że zbiory val / testowe zawierają odstawianego ocen od obserwowanych użytkowników, ponieważ niewidzialne użytkownicy nie muszą zanurzeń użytkowników. W naszym przypadku zobaczymy później, że podejście, którego używamy do włączenia faktoryzacji macierzy w FL, umożliwia również szybką rekonstrukcję osadzeń użytkowników dla niewidocznych użytkowników.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
W ramach szybkiego sprawdzenia możemy wydrukować partię danych treningowych. Widzimy, że każdy pojedynczy przykład zawiera MovieID pod kluczem „x” i ocenę pod kluczem „y”. Pamiętaj, że nie będziemy potrzebować UserID, ponieważ każdy użytkownik widzi tylko własne dane.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
Możemy wykreślić histogram pokazujący liczbę ocen przypadających na użytkownika.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
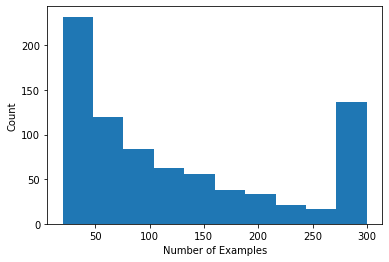
Teraz, po załadowaniu i zbadaniu danych, omówimy, jak wprowadzić faktoryzację macierzy do uczenia federacyjnego. Po drodze będziemy motywować częściowo lokalne sfederowane uczenie się.
Wprowadzanie faktoryzacji macierzy do FL
Chociaż faktoryzacja macierzy była tradycyjnie używana w ustawieniach scentralizowanych, jest ona szczególnie istotna w uczeniu sfederowanym: oceny użytkowników mogą znajdować się na osobnych urządzeniach klienckich, a my możemy chcieć uczyć się osadzania i rekomendacji dla użytkowników i elementów bez scentralizowania danych. Ponieważ każdy użytkownik ma swoje osadzenia użytkownika, naturalne jest, że każdy klient przechowuje osadzenia użytkownika — skaluje się to znacznie lepiej niż centralny serwer przechowujący wszystkie osadzenia użytkownika.
Jedna z propozycji wprowadzenia faktoryzacji macierzy do FL jest następująca:
- Serwer przechowuje i przesyła matrycy poz \(I\) do próbą klientów każdą rundę
- Klienci zaktualizować elementu macierzy i ich osobisty użytkownik osadzanie \(U_u\) użyciu SGD na powyższy cel
- Aktualizacje \(I\) są agregowane na serwerze, aktualizowanie kopii serwera \(I\) do następnej rundy
Takie podejście jest częściowo lokalny -to jest pewne parametry klienckie nigdy agregowane przez serwer. Chociaż to podejście jest atrakcyjne, wymaga od klientów utrzymywania stanu w różnych rundach, a mianowicie ich osadzenia przez użytkowników. Sfederowane algorytmy stanowe są mniej odpowiednie w przypadku ustawień FL na różnych urządzeniach: w tych ustawieniach wielkość populacji jest często znacznie większa niż liczba klientów, którzy biorą udział w każdej rundzie, a klient zwykle uczestniczy co najwyżej raz w procesie szkolenia. Poza tym opierając się na państwa, które nie mogą być inicjowane, algorytmy stanowe mogą powodować obniżenie wydajności w środowiskach różnych urządzeniach ze względu na stan coraz Państwie, gdy klienci są często próbą. Co ważne, w ustawieniu faktoryzacji macierzy, algorytm stanowy prowadzi do tego, że wszyscy niewidoczni klienci pomijają przeszkolone osadzania użytkowników, a podczas szkolenia na dużą skalę większość użytkowników może być niewidoczna. Więcej informacji na temat motywacji do algorytmów bezstanowych w przekroju urządzenia FL patrz Wang i in. 2021 ust. 3.1.1 i Reddi i in. 2020 ust. 5.1 .
Stowarzyszony Rekonstrukcja ( Singhal i in., 2021 ) jest bezstanowy alternatywny do wyżej wymienionej metody. Kluczową ideą jest to, że zamiast przechowywać osadzenia użytkownika w różnych rundach, klienci odtwarzają osadzenia użytkownika w razie potrzeby. Gdy FedRecon zostanie zastosowany do faktoryzacji macierzy, szkolenie przebiega w następujący sposób:
- Serwer przechowuje i przesyła matrycy poz \(I\) do próbą klientów każdą rundę
- Każdy klient zamarza \(I\) i szkoli ich obsługi osadzania \(U_u\) przy użyciu jednego lub więcej etapów SGD (przebudowy)
- Każdy klient zamarza \(U_u\) i pociągi \(I\) przy użyciu jednego lub więcej etapów SGD
- Aktualizacje \(I\) są agregowane w poprzek użytkowników, aktualizowanie kopii serwera \(I\) do następnej rundy
Takie podejście nie wymaga od klientów utrzymywania stanu w kolejnych rundach. Autorzy wskazują również w artykule, że metoda ta prowadzi do szybkiej rekonstrukcji osadzeń użytkownika dla niewidzianych klientów (rozdz. 4.2, ryc. 3 i tabela 1), umożliwiając większości klientów nieuczestniczących w szkoleniu posiadanie wytrenowanego modelu , umożliwiając rekomendacje dla tych klientów. Zobacz Federalne Rekonstrukcja Google AI Blog stanowiska dla kilku kluczowych wyników.
Definiowanie modelu
Następnie zdefiniujemy lokalny model faktoryzacji macierzy, który zostanie przeszkolony na urządzeniach klienckich. Model ten będzie zawierać pełną matrycy poz \(I\) oraz pojedyncze osadzenia użytkownik \(U_u\) dla klienta \(u\). Należy pamiętać, że klienci nie będą musieli przechowywać pełnej macierzy użytkownik \(U\).
Zdefiniujemy następujące elementy:
-
UserEmbedding: prosty Keras warstwy reprezentujące pojedynczenum_latent_factorswymiarowa użytkownika osadzanie. -
get_matrix_factorization_model: funkcja, która zwracatff.learning.reconstruction.Modelzawierające logikę modelu, w tym warstw, które są agregowane globalnie na serwerze, które warstwy pozostają lokalne. Te dodatkowe informacje są nam potrzebne do zainicjowania procesu szkoleniowego federacyjnej rekonstrukcji. Tutaj produkujemytff.learning.reconstruction.Modelz modelu Keras wykorzystaniemtff.learning.reconstruction.from_keras_model. Podobny dotff.learning.Model, możemy również realizować niestandardowetff.learning.reconstruction.Modelpoprzez implementację interfejsu klasy.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Analogiczna do interfejsu dla Federalne uśredniania interfejs dla Federalne Odbudowy oczekuje model_fn bez argumentów zwraca tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Będziemy obok określić loss_fn i metrics_fn , gdzie loss_fn to funkcja no-argumentem powrocie stratę Keras używać do pociągu modelu i metrics_fn to funkcja no-argumentem powrocie listę metryk Keras do oceny. Są one potrzebne do zbudowania obliczeń szkoleniowych i ewaluacyjnych.
Użyjemy błędu średniokwadratowego jako straty, jak wspomniano powyżej. Do oceny użyjemy dokładności oceny (kiedy przewidywany iloczyn skalarny modelu jest zaokrąglany do najbliższej liczby całkowitej, jak często jest on zgodny z oceną na etykiecie?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Szkolenie i ocena
Teraz mamy już wszystko, czego potrzebujemy do zdefiniowania procesu szkoleniowego. Jedna istotna różnica z interfejsem do Federalne uśredniania jest to, że możemy teraz przejść w reconstruction_optimizer_fn , które zostaną wykorzystane podczas rekonstrukcji lokalne parametry (w naszym przypadku, zanurzeń użytkownika). To zazwyczaj rozsądne użycie SGD tutaj, z podobnym lub nieco niższe niż tempo uczenia klienta optymalizatora szybkość uczenia się. Poniżej przedstawiamy działającą konfigurację. Nie zostało to dokładnie dostrojone, więc możesz swobodnie bawić się różnymi wartościami.
Sprawdź dokumentację po więcej szczegółów i opcji.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Możemy również zdefiniować obliczenia do oceny naszego wytrenowanego modelu globalnego.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Możemy zainicjować stan procesu uczenia i zbadać go. Co najważniejsze, widzimy, że ten stan serwera przechowuje tylko zmienne pozycji (obecnie inicjowane losowo), a nie żadne osadzania użytkowników.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Możemy również spróbować ocenić nasz losowo zainicjowany model na klientach walidacji. Sfederowana ocena rekonstrukcji obejmuje następujące elementy:
- Serwer wysyła matrycy poz \(I\) do próbą oceny klientów
- Każdy klient zamarza \(I\) i szkoli ich obsługi osadzania \(U_u\) przy użyciu jednego lub więcej etapów SGD (przebudowy)
- Każdy klient straty oblicza i metryki za pomocą serwera \(I\) i zrekonstruowany \(U_u\) na niewidocznej części swoich lokalnych danych
- Straty i wskaźniki są uśredniane dla użytkowników w celu obliczenia ogólnej straty i wskaźników
Pamiętaj, że kroki 1 i 2 są takie same, jak w przypadku szkolenia. Połączenie to jest bardzo ważne, ponieważ trenuje w ten sam sposób możemy ocenić prowadzi do swego rodzaju meta-uczenia się, czy nauka jak się uczyć. W tym przypadku model uczy się, jak uczyć się zmiennych globalnych (macierz pozycji), które prowadzą do wydajnej rekonstrukcji zmiennych lokalnych (osadzenia użytkownika). Więcej na ten temat, patrz rozdz. 4,2 papieru.
Ważne jest również, aby kroki 2 i 3 były wykonywane przy użyciu rozłącznych części lokalnych danych klientów, aby zapewnić rzetelną ocenę. Domyślnie zarówno proces uczenia, jak i obliczenia ewaluacyjne wykorzystują każdy inny przykład do rekonstrukcji i wykorzystują drugą połowę po rekonstrukcji. Takie zachowanie można dostosować za pomocą dataset_split_fn argumentu (będziemy badać to jeszcze później).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Możemy następnie spróbować przeprowadzić rundę treningu. Aby wszystko było bardziej realistyczne, w każdej rundzie będziemy losowo pobierać próbki 50 klientów bez wymiany. Nadal powinniśmy oczekiwać, że wskaźniki dotyczące pociągów będą słabe, ponieważ przeprowadzamy tylko jedną rundę szkolenia.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Teraz skonfigurujmy pętlę treningową, aby trenować przez wiele rund.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
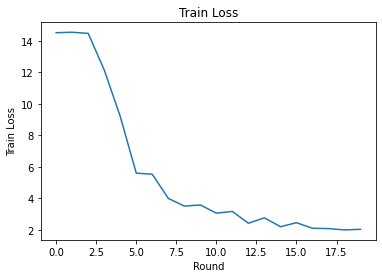
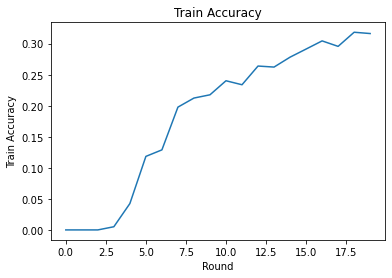
Możemy wykreślić straty w treningu i celność na rundy. Hiperparametry w tym notatniku nie zostały dokładnie dostrojone, więc możesz wypróbować różnych klientów na rundę, współczynniki uczenia się, liczbę rund i całkowitą liczbę klientów, aby poprawić te wyniki.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
Wreszcie, po zakończeniu strojenia możemy obliczyć metryki niewidocznego zestawu testowego.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Dalsze poszukiwania
Niezła robota przy skompletowaniu tego zeszytu. Proponujemy następujące ćwiczenia, aby dalej badać częściowo lokalną federację uczenia się, z grubsza uporządkowaną według rosnącej trudności:
Typowe implementacje uśredniania sfederowanego wymagają wielu lokalnych przebiegów (epok) nad danymi (oprócz wykonywania jednego przebiegu danych w wielu partiach). W przypadku federacyjnej rekonstrukcji możemy chcieć kontrolować liczbę kroków oddzielnie dla treningu rekonstrukcji i treningu po rekonstrukcji. Mijając
dataset_split_fnargument szkoleniowych i ewaluacji budowniczych obliczeniowych umożliwia kontrolę ilości kroków i epok ponad obu odbudowy i rekonstrukcji po zbiorach danych. Jako ćwiczenie spróbuj wykonać 3 lokalne epoki treningu rekonstrukcyjnego, z limitem 50 kroków i 1 lokalną epokę treningu porekonstrukcyjnego, z limitem 50 kroków. Podpowiedź: przekonasztff.learning.reconstruction.build_dataset_split_fnpomocne. Gdy już to zrobisz, spróbuj dostroić te hiperparametry i inne powiązane, takie jak tempo uczenia się i rozmiar partii, aby uzyskać lepsze wyniki.Domyślnym zachowaniem szkolenia i oceny federacyjnej rekonstrukcji jest podzielenie lokalnych danych klientów na pół dla każdej rekonstrukcji i po rekonstrukcji. W przypadkach, w których klienci mają bardzo mało danych lokalnych, rozsądne może być ponowne wykorzystanie danych do rekonstrukcji i postrekonstrukcji tylko w procesie szkolenia (nie do oceny, doprowadzi to do niesprawiedliwej oceny). Spróbuj wprowadzeniu tej zmiany w procesie szkolenia, zapewnienie
dataset_split_fndla oceny nadal utrzymuje Odbudowy i po rekonstrukcji danych rozłączne. Podpowiedź:tff.learning.reconstruction.simple_dataset_split_fnmoże być przydatna.Powyżej, produkowane
tff.learning.Modelz modelu Keras użyciutff.learning.reconstruction.from_keras_model. Możemy również zaimplementować model niestandardowy przy użyciu czystego TensorFlow 2.0 przez wdrożenie interfejsu modelu . Spróbuj modyfikacjęget_matrix_factorization_modelna budowę i powrotu klasę, która rozciągatff.learning.reconstruction.Model, realizując swoje metody. UWAGA: kod źródłowytff.learning.reconstruction.from_keras_modelprzedstawia przykładowe rozszerzenietff.learning.reconstruction.Modelklasy. Odnoszą się również do realizacji niestandardowych modelu w samouczku klasyfikacji EMNIST obrazu dla podobnego wysiłku w rozszerzenietff.learning.Model.W tym samouczku zmotywowaliśmy częściowo lokalne federacyjne uczenie się w kontekście faktoryzacji macierzy, gdzie wysyłanie osadzonych użytkowników na serwer spowodowałoby trywialne ujawnienie preferencji użytkownika. Możemy również zastosować Federated Reconstruction w innych ustawieniach jako sposób na wytrenowanie bardziej osobistych modeli (ponieważ część modelu jest całkowicie lokalna dla każdego użytkownika) przy jednoczesnym ograniczeniu komunikacji (ponieważ parametry lokalne nie są przesyłane na serwer). Ogólnie rzecz biorąc, korzystając z interfejsu przedstawionego tutaj, możemy wziąć dowolny model sfederowany, który zwykle byłby w pełni wytrenowany globalnie, i zamiast tego podzielić jego zmienne na zmienne globalne i zmienne lokalne. Przykład zbadane w papierze Federalne Odbudowy jest osobista obok przewidywania słowo: tutaj każdy użytkownik ma swój własny lokalny zestaw zanurzeń na słowo out-of-Słownik wyrazów, dzięki czemu model do slangu użytkowników przechwytywania obrazu i osiągnąć personalizacji bez dodatkowej komunikacji. W ramach ćwiczenia spróbuj zaimplementować (jako model Keras lub niestandardowy model TensorFlow 2.0) inny model do użytku z federacyjną rekonstrukcją. Sugestia: zaimplementuj model klasyfikacji EMNIST z osadzaniem użytkownika osobistego, w którym osadzanie użytkownika osobistego jest połączone z funkcjami obrazu CNN przed ostatnią warstwą modelu Dense. Można ponownie użyć dużo kodu z tego poradnika (np
UserEmbeddingklasy) i obrazu klasyfikacji poradnik .
Jeśli wciąż szukasz więcej na częściowo lokalnym uczenia stowarzyszonym sprawdzeniu Federalne Reconstruction papieru i open source kod eksperymentu .