
| |
|
 GitHub でソースを表示 GitHub でソースを表示
|
|
TF-Hub (https://tfhub.dev/tensorflow/cord-19/swivel-128d/3) の CORD-19 Swivel テキスト埋め込みモジュールは、COVID-19 に関連する自然言語テキストを分析する研究者をサポートするために構築されました。これらの埋め込みは、CORD-19 データセットの論文のタイトル、著者、抄録、本文、および参照タイトルをトレーニングしています。
この Colab では、以下について取り上げます。
- 埋め込み空間内の意味的に類似した単語の分析
- CORD-19 埋め込みを使用した SciCite データセットによる分類器のトレーニング
セットアップ
import functools
import itertools
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
from tqdm import trange
2024-01-11 19:07:47.276545: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 19:07:47.276588: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 19:07:47.278343: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
埋め込みを分析する
まず、異なる単語間の相関行列を計算してプロットし、埋め込みを分析してみましょう。異なる単語の意味をうまく捉えられるように埋め込みが学習できていれば、意味的に似た単語の埋め込みベクトルは近くにあるはずです。COVID-19 関連の用語をいくつか見てみましょう。
# Use the inner product between two embedding vectors as the similarity measure
def plot_correlation(labels, features):
corr = np.inner(features, features)
corr /= np.max(corr)
sns.heatmap(corr, xticklabels=labels, yticklabels=labels)
# Generate embeddings for some terms
queries = [
# Related viruses
'coronavirus', 'SARS', 'MERS',
# Regions
'Italy', 'Spain', 'Europe',
# Symptoms
'cough', 'fever', 'throat'
]
module = hub.load('https://tfhub.dev/tensorflow/cord-19/swivel-128d/3')
embeddings = module(queries)
plot_correlation(queries, embeddings)
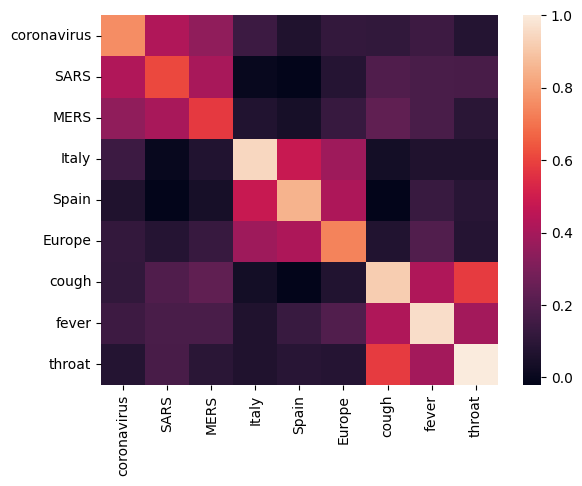
埋め込みが異なる用語の意味をうまく捉えていることが分かります。それぞれの単語は所属するクラスタの他の単語に類似していますが(「コロナウイルス」は「SARS」や「MERS」と高い関連性がある)、ほかのクラスタの単語とは異なります(「SARS」と「スペイン」の類似度はゼロに近い)。
では、これらの埋め込みを使用して特定のタスクを解決する方法を見てみましょう。
SciCite: 引用の意図の分類
このセクションでは、テキスト分類など下流のタスクに埋め込みを使う方法を示します。学術論文の引用の意図の分類には、TensorFlow Dataset の SciCite データセットを使用します。学術論文からの引用がある文章がある場合に、その引用の主な意図が背景情報、方法の使用、または結果の比較のうち、どれであるかを分類します。
builder = tfds.builder(name='scicite')
builder.download_and_prepare()
train_data, validation_data, test_data = builder.as_dataset(
split=('train', 'validation', 'test'),
as_supervised=True)
Let's take a look at a few labeled examples from the training set
NUM_EXAMPLES = 10
TEXT_FEATURE_NAME = builder.info.supervised_keys[0]
LABEL_NAME = builder.info.supervised_keys[1]
def label2str(numeric_label):
m = builder.info.features[LABEL_NAME].names
return m[numeric_label]
data = next(iter(train_data.batch(NUM_EXAMPLES)))
pd.DataFrame({
TEXT_FEATURE_NAME: [ex.numpy().decode('utf8') for ex in data[0]],
LABEL_NAME: [label2str(x) for x in data[1]]
})
引用の意図分類器をトレーニングする
分類器のトレーニングには、SciCite データセットに対して Keras を使用します。上に分類レイヤーを持ち、CORD-19 埋め込みを使用するモデルを構築してみましょう。
Hyperparameters
EMBEDDING = 'https://tfhub.dev/tensorflow/cord-19/swivel-128d/3'
TRAINABLE_MODULE = False
hub_layer = hub.KerasLayer(EMBEDDING, input_shape=[],
dtype=tf.string, trainable=TRAINABLE_MODULE)
model = tf.keras.Sequential()
model.add(hub_layer)
model.add(tf.keras.layers.Dense(3))
model.summary()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 128) 17301632
dense (Dense) (None, 3) 387
=================================================================
Total params: 17302019 (132.00 MB)
Trainable params: 387 (1.51 KB)
Non-trainable params: 17301632 (132.00 MB)
_________________________________________________________________
モデルをトレーニングして評価する
モデルをトレーニングして評価を行い、SciCite タスクでのパフォーマンスを見てみましょう。
EPOCHS = 35
BATCH_SIZE = 32
history = model.fit(train_data.shuffle(10000).batch(BATCH_SIZE),
epochs=EPOCHS,
validation_data=validation_data.batch(BATCH_SIZE),
verbose=1)
Epoch 1/35 15/257 [>.............................] - ETA: 0s - loss: 1.0672 - accuracy: 0.4938 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1705000078.803553 91317 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 257/257 [==============================] - 3s 5ms/step - loss: 0.8821 - accuracy: 0.6047 - val_loss: 0.7713 - val_accuracy: 0.6779 Epoch 2/35 257/257 [==============================] - 2s 5ms/step - loss: 0.6886 - accuracy: 0.7248 - val_loss: 0.6688 - val_accuracy: 0.7391 Epoch 3/35 257/257 [==============================] - 2s 4ms/step - loss: 0.6186 - accuracy: 0.7598 - val_loss: 0.6251 - val_accuracy: 0.7434 Epoch 4/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5853 - accuracy: 0.7732 - val_loss: 0.6061 - val_accuracy: 0.7489 Epoch 5/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5660 - accuracy: 0.7814 - val_loss: 0.5878 - val_accuracy: 0.7620 Epoch 6/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5534 - accuracy: 0.7863 - val_loss: 0.5813 - val_accuracy: 0.7664 Epoch 7/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5449 - accuracy: 0.7869 - val_loss: 0.5716 - val_accuracy: 0.7762 Epoch 8/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5383 - accuracy: 0.7898 - val_loss: 0.5693 - val_accuracy: 0.7740 Epoch 9/35 257/257 [==============================] - 2s 4ms/step - loss: 0.5327 - accuracy: 0.7896 - val_loss: 0.5627 - val_accuracy: 0.7817 Epoch 10/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5291 - accuracy: 0.7939 - val_loss: 0.5602 - val_accuracy: 0.7795 Epoch 11/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5254 - accuracy: 0.7940 - val_loss: 0.5575 - val_accuracy: 0.7838 Epoch 12/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5229 - accuracy: 0.7944 - val_loss: 0.5563 - val_accuracy: 0.7795 Epoch 13/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5198 - accuracy: 0.7959 - val_loss: 0.5545 - val_accuracy: 0.7817 Epoch 14/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5179 - accuracy: 0.7952 - val_loss: 0.5511 - val_accuracy: 0.7806 Epoch 15/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5160 - accuracy: 0.7979 - val_loss: 0.5552 - val_accuracy: 0.7773 Epoch 16/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5144 - accuracy: 0.7972 - val_loss: 0.5504 - val_accuracy: 0.7784 Epoch 17/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5130 - accuracy: 0.7974 - val_loss: 0.5511 - val_accuracy: 0.7806 Epoch 18/35 257/257 [==============================] - 1s 5ms/step - loss: 0.5111 - accuracy: 0.7967 - val_loss: 0.5487 - val_accuracy: 0.7806 Epoch 19/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5099 - accuracy: 0.7979 - val_loss: 0.5501 - val_accuracy: 0.7806 Epoch 20/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5090 - accuracy: 0.7978 - val_loss: 0.5483 - val_accuracy: 0.7817 Epoch 21/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5075 - accuracy: 0.7989 - val_loss: 0.5478 - val_accuracy: 0.7784 Epoch 22/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5068 - accuracy: 0.7984 - val_loss: 0.5449 - val_accuracy: 0.7849 Epoch 23/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5058 - accuracy: 0.8008 - val_loss: 0.5451 - val_accuracy: 0.7849 Epoch 24/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5052 - accuracy: 0.8011 - val_loss: 0.5466 - val_accuracy: 0.7838 Epoch 25/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5048 - accuracy: 0.7996 - val_loss: 0.5469 - val_accuracy: 0.7860 Epoch 26/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5035 - accuracy: 0.8002 - val_loss: 0.5479 - val_accuracy: 0.7838 Epoch 27/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5038 - accuracy: 0.8001 - val_loss: 0.5446 - val_accuracy: 0.7817 Epoch 28/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5027 - accuracy: 0.8018 - val_loss: 0.5441 - val_accuracy: 0.7860 Epoch 29/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5021 - accuracy: 0.8000 - val_loss: 0.5442 - val_accuracy: 0.7849 Epoch 30/35 257/257 [==============================] - 2s 4ms/step - loss: 0.5014 - accuracy: 0.8019 - val_loss: 0.5438 - val_accuracy: 0.7882 Epoch 31/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5009 - accuracy: 0.8024 - val_loss: 0.5438 - val_accuracy: 0.7871 Epoch 32/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5001 - accuracy: 0.8008 - val_loss: 0.5439 - val_accuracy: 0.7904 Epoch 33/35 257/257 [==============================] - 2s 5ms/step - loss: 0.5006 - accuracy: 0.8034 - val_loss: 0.5456 - val_accuracy: 0.7860 Epoch 34/35 257/257 [==============================] - 1s 4ms/step - loss: 0.5001 - accuracy: 0.8027 - val_loss: 0.5437 - val_accuracy: 0.7860 Epoch 35/35 257/257 [==============================] - 1s 4ms/step - loss: 0.4993 - accuracy: 0.8027 - val_loss: 0.5436 - val_accuracy: 0.7904
from matplotlib import pyplot as plt
def display_training_curves(training, validation, title, subplot):
if subplot%10==1: # set up the subplots on the first call
plt.subplots(figsize=(10,10), facecolor='#F0F0F0')
plt.tight_layout()
ax = plt.subplot(subplot)
ax.set_facecolor('#F8F8F8')
ax.plot(training)
ax.plot(validation)
ax.set_title('model '+ title)
ax.set_ylabel(title)
ax.set_xlabel('epoch')
ax.legend(['train', 'valid.'])
display_training_curves(history.history['accuracy'], history.history['val_accuracy'], 'accuracy', 211)
display_training_curves(history.history['loss'], history.history['val_loss'], 'loss', 212)
モデルを評価する
モデルがどのように実行するか見てみましょう。2 つの値が返されます。損失(誤差、値が低いほど良)と正確度です。
results = model.evaluate(test_data.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print('%s: %.3f' % (name, value))
4/4 - 0s - loss: 0.5344 - accuracy: 0.7907 - 359ms/epoch - 90ms/step loss: 0.534 accuracy: 0.791
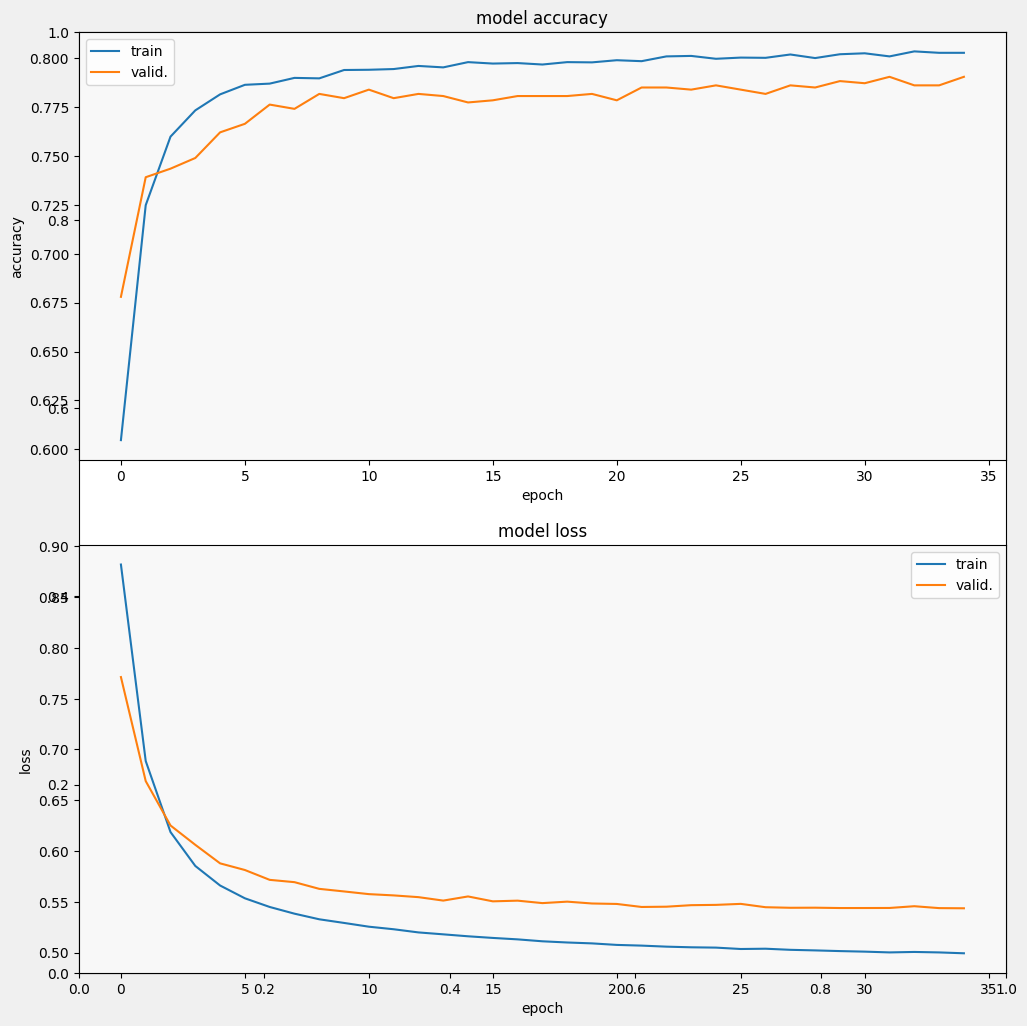
損失はすぐに減少しますが、特に精度は急速に上がることが分かります。予測と真のラベルがどのように関係しているかを確認するために、いくつかの例をプロットしてみましょう。
prediction_dataset = next(iter(test_data.batch(20)))
prediction_texts = [ex.numpy().decode('utf8') for ex in prediction_dataset[0]]
prediction_labels = [label2str(x) for x in prediction_dataset[1]]
predictions = [
label2str(x) for x in np.argmax(model.predict(prediction_texts), axis=-1)]
pd.DataFrame({
TEXT_FEATURE_NAME: prediction_texts,
LABEL_NAME: prediction_labels,
'prediction': predictions
})
1/1 [==============================] - 0s 182ms/step
このランダムサンプルでは、ほとんどの場合、モデルが正しいラベルを予測しており、科学的な文をうまく埋め込むことができていることが分かります。
次のステップ
TF-Hub の CORD-19 Swivel 埋め込みについて少し説明しました。COVID-19 関連の学術的なテキストから科学的洞察の取得に貢献できる、CORD-19 Kaggle コンペへの参加をお勧めします。
- CORD-19 Kaggle Challenge に参加しましょう。
- 詳細については COVID-19 Open Research Dataset (CORD-19) をご覧ください。
- TF-Hub 埋め込みに関する詳細のドキュメントは https://tfhub.dev/tensorflow/cord-19/swivel-128d/3 をご覧ください。
- TensorFlow Embedding Projector を利用して CORD-19 埋め込み空間を見てみましょう。