
| | |  गिटहब पर देखें गिटहब पर देखें | | |
यह नोटबुक आपको दिखाता है कि TFDS के डेटासेट या अपने स्वयं के फसल रोग का पता लगाने वाले डेटासेट पर TensorFlow हब से क्रॉपनेट मॉडल को कैसे फ़ाइन-ट्यून किया जाए ।
आप:
- TFDS कसावा डेटासेट या अपना खुद का डेटा लोड करें
- अधिक मजबूत मॉडल प्राप्त करने के लिए अज्ञात (नकारात्मक) उदाहरणों के साथ डेटा को समृद्ध करें
- डेटा में छवि संवर्द्धन लागू करें
- TF हब से क्रॉपनेट मॉडल को लोड और फाइन ट्यून करें
- एक टीएफलाइट मॉडल निर्यात करें, जो सीधे आपके ऐप पर टास्क लाइब्रेरी , एमएलकिट या टीएफलाइट के साथ तैनात होने के लिए तैयार है
आयात और निर्भरता
शुरू करने से पहले, आपको कुछ निर्भरताएँ स्थापित करनी होंगी जिनकी आवश्यकता होगी जैसे मॉडल निर्माता और TensorFlow डेटासेट का नवीनतम संस्करण।
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
फ़ाइन-ट्यून करने के लिए TFDS डेटासेट लोड करें
आइए TFDS से सार्वजनिक रूप से उपलब्ध कसावा लीफ डिजीज डेटासेट का उपयोग करें।
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
या वैकल्पिक रूप से फ़ाइन-ट्यून करने के लिए अपना स्वयं का डेटा लोड करें
TFDS डेटासेट का उपयोग करने के बजाय, आप अपने स्वयं के डेटा पर प्रशिक्षण भी ले सकते हैं। यह कोड स्निपेट दिखाता है कि अपने स्वयं के कस्टम डेटासेट को कैसे लोड किया जाए। डेटा की समर्थित संरचना के लिए यह लिंक देखें। सार्वजनिक रूप से उपलब्ध कसावा लीफ डिजीज डेटासेट का उपयोग करके यहां एक उदाहरण दिया गया है।
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
ट्रेन स्प्लिट से नमूने देखें
आइए डेटासेट से कुछ उदाहरणों पर एक नज़र डालें जिसमें क्लास आईडी और इमेज सैंपल और उनके लेबल के लिए क्लास का नाम शामिल है।
_ = tfds.show_examples(ds_train, ds_info)

TFDS डेटासेट से अज्ञात उदाहरणों के रूप में उपयोग की जाने वाली छवियां जोड़ें
प्रशिक्षण डेटासेट में अतिरिक्त अज्ञात (नकारात्मक) उदाहरण जोड़ें और उन्हें एक नया अज्ञात वर्ग लेबल नंबर असाइन करें। लक्ष्य एक ऐसा मॉडल तैयार करना है, जो व्यवहार में (जैसे क्षेत्र में) उपयोग किए जाने पर, "अज्ञात" की भविष्यवाणी करने का विकल्प हो, जब वह कुछ अप्रत्याशित देखता है।
नीचे आप उन डेटासेट की सूची देख सकते हैं जिनका उपयोग अतिरिक्त अज्ञात इमेजरी के नमूने के लिए किया जाएगा। इसमें विविधता बढ़ाने के लिए 3 पूरी तरह से अलग डेटासेट शामिल हैं। उनमें से एक बीन्स लीफ डिजीज डेटासेट है, ताकि मॉडल में कसावा के अलावा अन्य रोगग्रस्त पौधों के संपर्क में रहे।
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
UNKNOWN डेटासेट भी TFDS से लोड किए जाते हैं।
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
संवर्द्धन लागू करें
सभी छवियों के लिए, उन्हें और अधिक विविधतापूर्ण बनाने के लिए, आप कुछ संवर्द्धन लागू करेंगे, जैसे कि इसमें परिवर्तन:
- चमक
- अंतर
- परिपूर्णता
- रंग
- काटना
इस प्रकार के संवर्द्धन छवि इनपुट में बदलाव के लिए मॉडल को और अधिक मजबूत बनाने में मदद करते हैं।
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
संवर्द्धन को लागू करने के लिए, यह डेटासेट वर्ग से map पद्धति का उपयोग करता है।
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
डेटा को मॉडल मेकर के अनुकूल प्रारूप में लपेटें
मॉडल मेकर के साथ इन डेटासेट का उपयोग करने के लिए, उन्हें ImageClassifierDataLoader वर्ग में होना चाहिए।
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
प्रशिक्षण चलाएं
TensorFlow हब में ट्रांसफर लर्निंग के लिए कई मॉडल उपलब्ध हैं।
यहां आप किसी एक को चुन सकते हैं और बेहतर परिणाम प्राप्त करने के लिए आप अन्य के साथ प्रयोग भी जारी रख सकते हैं।
यदि आप और भी मॉडल आज़माना चाहते हैं, तो आप उन्हें इस संग्रह से जोड़ सकते हैं।
एक आधार मॉडल चुनें
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
मॉडल को फाइन ट्यून करने के लिए, आप मॉडल मेकर का उपयोग करेंगे। यह समग्र समाधान को आसान बनाता है क्योंकि मॉडल के प्रशिक्षण के बाद, यह इसे TFlite में भी बदल देगा।
मॉडल निर्माता इस रूपांतरण को सबसे अच्छा संभव बनाता है और बाद में मॉडल को डिवाइस पर आसानी से परिनियोजित करने के लिए सभी आवश्यक जानकारी देता है।
मॉडल युक्ति यह है कि आप मॉडल निर्माता को कैसे बताते हैं कि आप किस आधार मॉडल का उपयोग करना चाहते हैं।
image_model_spec = ModelSpec(uri=model_handle)
यहां एक महत्वपूर्ण विवरण train_whole_model सेट कर रहा है जो प्रशिक्षण के दौरान बेस मॉडल को ठीक कर देगा। यह प्रक्रिया को धीमा कर देता है लेकिन अंतिम मॉडल में उच्च सटीकता होती है। shuffle सेट करना यह सुनिश्चित करेगा कि मॉडल डेटा को एक यादृच्छिक फेरबदल क्रम में देखता है जो मॉडल सीखने के लिए सबसे अच्छा अभ्यास है।
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
प्लेसहोल्डर17परीक्षण विभाजन पर मॉडल का मूल्यांकन करें
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
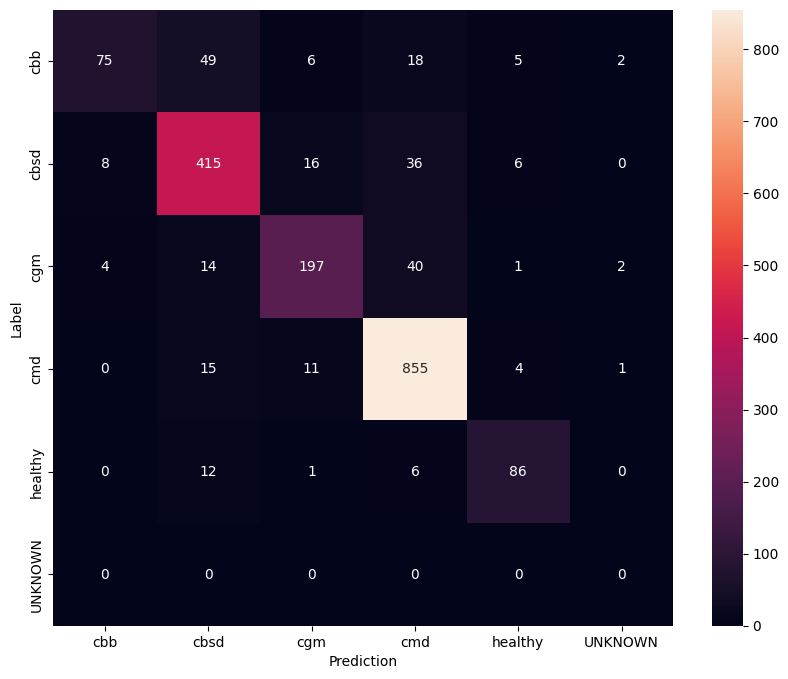
ठीक ट्यून किए गए मॉडल की और भी बेहतर समझ रखने के लिए, भ्रम मैट्रिक्स का विश्लेषण करना अच्छा है। यह दिखाएगा कि एक वर्ग को दूसरे वर्ग के रूप में कितनी बार भविष्यवाणी की जाती है।
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
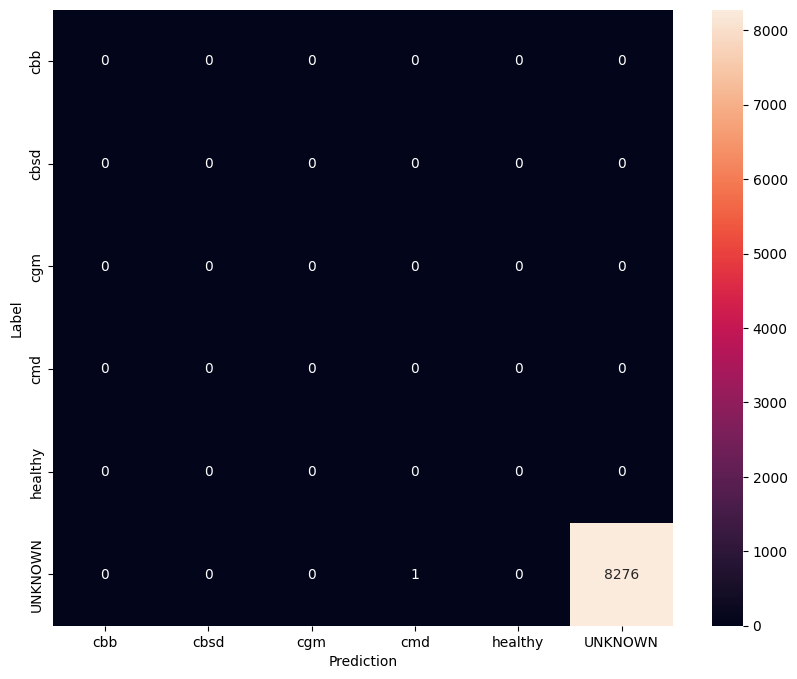
अज्ञात परीक्षण डेटा पर मॉडल का मूल्यांकन करें
इस मूल्यांकन में हम उम्मीद करते हैं कि मॉडल में लगभग 1 की सटीकता होगी। मॉडल का परीक्षण करने वाली सभी छवियां सामान्य डेटासेट से संबंधित नहीं हैं और इसलिए हम मॉडल से "अज्ञात" वर्ग लेबल की भविष्यवाणी करने की अपेक्षा करते हैं।
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
भ्रम मैट्रिक्स प्रिंट करें।
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
मॉडल को TFlite और SavedModel के रूप में निर्यात करें
अब हम प्रशिक्षित मॉडल को TFLite और SavedModel स्वरूपों में निर्यात कर सकते हैं ताकि ऑन-डिवाइस परिनियोजित किया जा सके और TensorFlow में अनुमान के लिए उपयोग किया जा सके।
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
अगले कदम
जिस मॉडल को आपने अभी-अभी प्रशिक्षित किया है उसका उपयोग मोबाइल उपकरणों पर किया जा सकता है और यहां तक कि क्षेत्र में भी तैनात किया जा सकता है!
मॉडल डाउनलोड करने के लिए, कोलाब के बाईं ओर स्थित फ़ाइलें मेनू के लिए फ़ोल्डर आइकन पर क्लिक करें और डाउनलोड विकल्प चुनें।
यहां उपयोग की जाने वाली एक ही तकनीक को अन्य पौधों की बीमारियों के कार्यों पर लागू किया जा सकता है जो आपके उपयोग के मामले या किसी अन्य प्रकार के छवि वर्गीकरण कार्य के लिए अधिक उपयुक्त हो सकते हैं। यदि आप किसी Android ऐप पर अनुवर्ती कार्रवाई और परिनियोजन करना चाहते हैं, तो आप इस Android त्वरित प्रारंभ मार्गदर्शिका पर जारी रख सकते हैं।