
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
このノートブックでは、ユニバーサルセンテンスエンコーダーにアクセスし、文章の類似性と文章の分類タスクに使用する方法を説明します。
ユニバーサルセンテンスエンコーダーでは、これまで各単語の埋め込みをルックアップしてきたのと同じくらい簡単に文章レベルの埋め込みを取得することができます。取得された文章埋め込みは、文章レベルでの意味の類似性を計算するためだけではなく、少ない教師ありトレーニングデータを使うことで、ダウンストリームの分類タスクのパフォーマンスを改善するために使用することができます。
セットアップ
このセクションは、TF Hub でユニバーサルセンテンスエンコーダーにアクセスする環境をセットアップし、エンコーダーを単語、文章、および段落に適用する例を提供します。
%%capture
!pip3 install seaborn
Tensorflow のインストールに関する詳細は、https://www.tensorflow.org/install/ をご覧ください。
Load the Universal Sentence Encoder's TF Hub module
from absl import logging
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)
def embed(input):
return model(input)
2024-01-11 19:18:35.024540: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 19:18:35.024587: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 19:18:35.026141: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered module https://tfhub.dev/google/universal-sentence-encoder/4 loaded
Compute a representation for each message, showing various lengths supported.
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]
# Reduce logging output.
logging.set_verbosity(logging.ERROR)
message_embeddings = embed(messages)
for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join(
(str(x) for x in message_embedding[:3]))
print("Embedding: [{}, ...]\n".format(message_embedding_snippet))
Message: Elephant Embedding size: 512 Embedding: [0.008344491012394428, 0.00048081044224090874, 0.06595246493816376, ...] Message: I am a sentence for which I would like to get its embedding. Embedding size: 512 Embedding: [0.0508086159825325, -0.016524314880371094, 0.015737783163785934, ...] Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be. Embedding size: 512 Embedding: [-0.028332671150565147, -0.055862173438072205, -0.012941475957632065, ...]
セマンティックテキストの類似性タスクの例
ユニバーサルセンテンスエンコーダーによって生成される埋め込みは、おおよそ正規化されています。2 つの文章の意味的類似性は、エンコーディングの内積として簡単に計算することができます。
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
def run_and_plot(messages_):
message_embeddings_ = embed(messages_)
plot_similarity(messages_, message_embeddings_, 90)
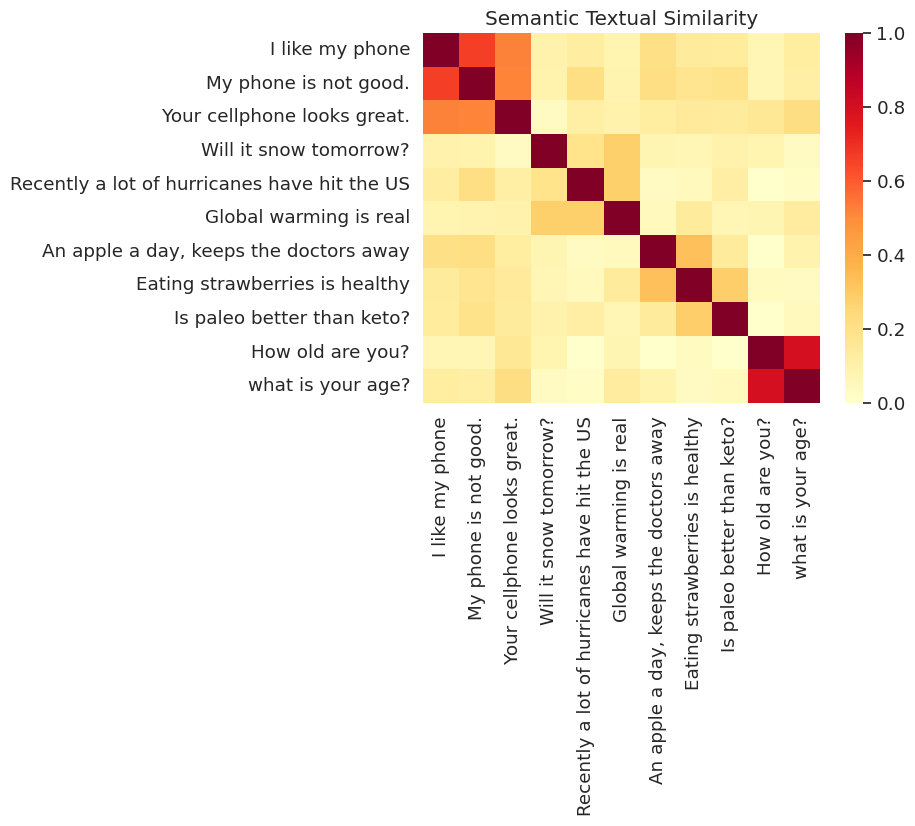
類似性の視覚化
ここでは、ヒートマップに類似性を表示します。最終的なグラフは 9x9 の行列で、各エントリ [i, j] は、文章 i と j のエンコーディングの内積に基づいて色付けされます。
messages = [
# Smartphones
"I like my phone",
"My phone is not good.",
"Your cellphone looks great.",
# Weather
"Will it snow tomorrow?",
"Recently a lot of hurricanes have hit the US",
"Global warming is real",
# Food and health
"An apple a day, keeps the doctors away",
"Eating strawberries is healthy",
"Is paleo better than keto?",
# Asking about age
"How old are you?",
"what is your age?",
]
run_and_plot(messages)
評価: STS(セマンティックテキストの類似性)ベンチマーク
STS ベンチマークは、文章埋め込みを使って計算された類似性スコアが人の判定に適合する程度の本質的評価です。ベンチマークでは、システムは多様な文章ペアに対して類似性スコアを返す必要があります。その後で、ピアソン相関を使用して、人の判定に対して機械の類似性スコアの質が評価されます。
データのダウンロード
import pandas
import scipy
import math
import csv
sts_dataset = tf.keras.utils.get_file(
fname="Stsbenchmark.tar.gz",
origin="http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz",
extract=True)
sts_dev = pandas.read_table(
os.path.join(os.path.dirname(sts_dataset), "stsbenchmark", "sts-dev.csv"),
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
sts_test = pandas.read_table(
os.path.join(
os.path.dirname(sts_dataset), "stsbenchmark", "sts-test.csv"),
quoting=csv.QUOTE_NONE,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
# cleanup some NaN values in sts_dev
sts_dev = sts_dev[[isinstance(s, str) for s in sts_dev['sent_2']]]
文章埋め込みの評価
sts_data = sts_dev
def run_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_1'].tolist())), axis=1)
sts_encode2 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_2'].tolist())), axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2), axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities, -1.0, 1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
"""Returns the similarity scores"""
return scores
dev_scores = sts_data['sim'].tolist()
scores = []
for batch in np.array_split(sts_data, 10):
scores.extend(run_sts_benchmark(batch))
pearson_correlation = scipy.stats.pearsonr(scores, dev_scores)
print('Pearson correlation coefficient = {0}\np-value = {1}'.format(
pearson_correlation[0], pearson_correlation[1]))
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/numpy/core/fromnumeric.py:59: FutureWarning: 'DataFrame.swapaxes' is deprecated and will be removed in a future version. Please use 'DataFrame.transpose' instead. return bound(*args, **kwds) Pearson correlation coefficient = 0.8036389314431555 p-value = 0.0