
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
ولم يضف النماذج هي طرق سريعة وسهلة لبناء TFL tf.keras.model حالات لحالات الاستخدام النموذجي. يوضح هذا الدليل الخطوات اللازمة لإنشاء نموذج TFL Premade وتدريبه / اختباره.
يثبت
تثبيت حزمة TF Lattice:
pip install tensorflow-lattice pydot
استيراد الحزم المطلوبة:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
تحديد القيم الافتراضية المستخدمة للتدريب في هذا الدليل:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
تنزيل مجموعة بيانات UCI Statlog (القلب):
heart_csv_file = tf.keras.utils.get_file(
'heart.csv',
'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
heart_df = pd.read_csv(heart_csv_file)
thal_vocab_list = ['normal', 'fixed', 'reversible']
heart_df['thal'] = heart_df['thal'].map(
{v: i for i, v in enumerate(thal_vocab_list)})
heart_df = heart_df.astype(float)
heart_train_size = int(len(heart_df) * 0.8)
heart_train_dict = dict(heart_df[:heart_train_size])
heart_test_dict = dict(heart_df[heart_train_size:])
# This ordering of input features should match the feature configs. If no
# feature config relies explicitly on the data (i.e. all are 'quantiles'),
# then you can construct the feature_names list by simply iterating over each
# feature config and extracting it's name.
feature_names = [
'age', 'sex', 'cp', 'chol', 'fbs', 'trestbps', 'thalach', 'restecg',
'exang', 'oldpeak', 'slope', 'ca', 'thal'
]
# Since we have some features that manually construct their input keypoints,
# we need an index mapping of the feature names.
feature_name_indices = {name: index for index, name in enumerate(feature_names)}
label_name = 'target'
heart_train_xs = [
heart_train_dict[feature_name] for feature_name in feature_names
]
heart_test_xs = [heart_test_dict[feature_name] for feature_name in feature_names]
heart_train_ys = heart_train_dict[label_name]
heart_test_ys = heart_test_dict[label_name]
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
ميزة Configs
يتم تعيين ميزة معايرة وتكوينات لكل ميزة استخدام tfl.configs.FeatureConfig . وتشمل تكوينات ميزة القيود الرتابه في الصوت، تنظيم لكل ميزة (انظر tfl.configs.RegularizerConfig )، والأحجام شعرية لنماذج شعرية.
لاحظ أنه يجب علينا تحديد تكوين الميزة بالكامل لأي ميزة نريد أن يتعرف عليها نموذجنا. وإلا فلن يكون للنموذج أي طريقة لمعرفة وجود مثل هذه الميزة.
تحديد الميزات الخاصة بنا
الآن بعد أن أصبح بإمكاننا حساب الكميات الخاصة بنا ، نحدد تكوين ميزة لكل ميزة نريد أن يتخذها نموذجنا كمدخلات.
# Features:
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal normal; fixed defect; reversable defect
#
# Feature configs are used to specify how each feature is calibrated and used.
heart_feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
monotonicity='increasing',
# We must set the keypoints manually.
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='sex',
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='cp',
monotonicity='increasing',
# Keypoints that are uniformly spaced.
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints=np.linspace(
np.min(heart_train_xs[feature_name_indices['cp']]),
np.max(heart_train_xs[feature_name_indices['cp']]),
num=4),
),
tfl.configs.FeatureConfig(
name='chol',
monotonicity='increasing',
# Explicit input keypoints initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='trestbps',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thalach',
monotonicity='decreasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='oldpeak',
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
num_buckets=3,
),
tfl.configs.FeatureConfig(
name='ca',
monotonicity='increasing',
pwl_calibration_num_keypoints=4,
pwl_calibration_input_keypoints='quantiles',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
num_buckets=3,
# We must specify the vocabulary list in order to later set the
# monotonicities since we used names and not indices.
vocabulary_list=thal_vocab_list,
),
]
تعيين الرتابة ونقاط المفاتيح
بعد ذلك ، نحتاج إلى التأكد من ضبط رتابة الميزات بشكل صحيح حيث استخدمنا مفردات مخصصة (مثل "thal" أعلاه).
tfl.premade_lib.set_categorical_monotonicities(heart_feature_configs)
أخيرًا ، يمكننا إكمال تكوينات الميزات الخاصة بنا عن طريق حساب نقاط المفاتيح وتعيينها.
feature_keypoints = tfl.premade_lib.compute_feature_keypoints(
feature_configs=heart_feature_configs, features=heart_train_dict)
tfl.premade_lib.set_feature_keypoints(
feature_configs=heart_feature_configs,
feature_keypoints=feature_keypoints,
add_missing_feature_configs=False)
النموذج الخطي المعاير
لبناء نموذج ولم يضف TFL، أولا بناء تكوين نموذج من tfl.configs . يتم إنشاء نموذج الخطي معايرة باستخدام tfl.configs.CalibratedLinearConfig . وهي تطبق معايرة جزئية وخطية فئوية على ميزات الإدخال ، متبوعة بمجموعة خطية ومعايرة اختيارية لمعايرة خطية للإخراج. عند استخدام معايرة الإخراج أو عند تحديد حدود الإخراج ، ستطبق الطبقة الخطية المتوسط المرجح على المدخلات المعايرة.
ينشئ هذا المثال نموذجًا خطيًا معايرًا على الميزات الخمس الأولى.
# Model config defines the model structure for the premade model.
linear_model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=heart_feature_configs[:5],
use_bias=True,
output_calibration=True,
output_calibration_num_keypoints=10,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=np.linspace(-2.0, 2.0, num=10),
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CalibratedLinear premade model constructed from the given model config.
linear_model = tfl.premade.CalibratedLinear(linear_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(linear_model, show_layer_names=False, rankdir='LR')
2022-01-14 12:36:31.295751: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
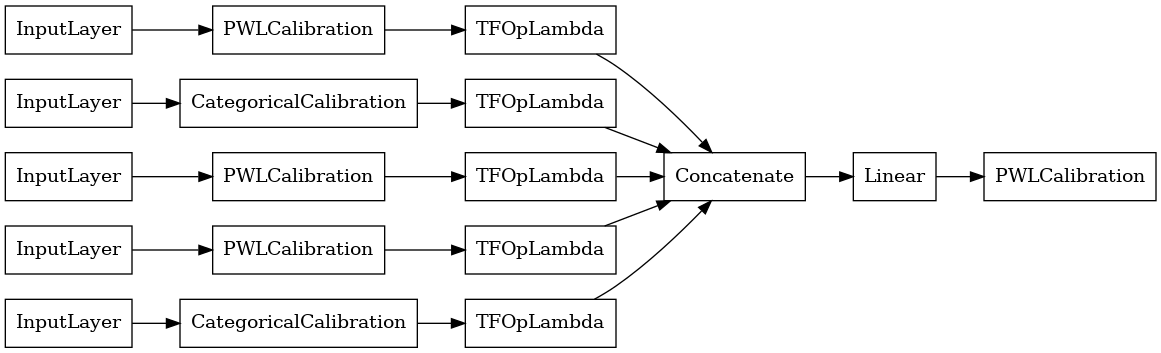
الآن، كما هو الحال مع أي دولة أخرى tf.keras.Model ، نحن تجميع وتناسب نموذج لمعلوماتنا.
linear_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
linear_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
<keras.callbacks.History at 0x7fe4385f0290>
بعد تدريب نموذجنا ، يمكننا تقييمه على مجموعة الاختبار الخاصة بنا.
print('Test Set Evaluation...')
print(linear_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.4728 - auc: 0.8252 [0.47278329730033875, 0.8251879215240479]
نموذج شعرية معاير
يتم إنشاء نموذج شعرية معايرة باستخدام tfl.configs.CalibratedLatticeConfig . يطبق النموذج الشبكي المعاير معايرة خطية فئوية ومعايرة فئوية على ميزات الإدخال ، متبوعة بنموذج شبكي ومعايرة اختيارية متعددة الخطوط للخرج.
ينشئ هذا المثال نموذجًا شبكيًا معايرًا على الميزات الخمس الأولى.
# This is a calibrated lattice model: inputs are calibrated, then combined
# non-linearly using a lattice layer.
lattice_model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=heart_feature_configs[:5],
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-2),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-2),
])
# A CalibratedLattice premade model constructed from the given model config.
lattice_model = tfl.premade.CalibratedLattice(lattice_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(lattice_model, show_layer_names=False, rankdir='LR')
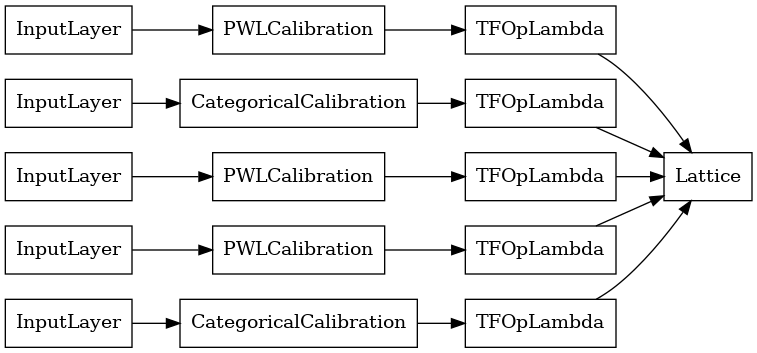
كما كان من قبل ، نقوم بتجميع نموذجنا وتكييفه وتقييمه.
lattice_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
lattice_model.fit(
heart_train_xs[:5],
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(lattice_model.evaluate(heart_test_xs[:5], heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.4709 - auc_1: 0.8302 [0.4709009826183319, 0.8302004933357239]
نموذج فرقة شعرية معايرة
عندما يكون عدد الميزات كبيرًا ، يمكنك استخدام نموذج تجميعي ، والذي يُنشئ شبكات متعددة أصغر لمجموعات فرعية من الميزات ويقيس متوسط ناتجها بدلاً من إنشاء شبكة واحدة ضخمة فقط. هي التي شيدت نماذج شعرية فرقة باستخدام tfl.configs.CalibratedLatticeEnsembleConfig . يطبق نموذج مجموعة الشبكة المُعايرة معايرة خطية وقطعية متعددة التعريف على ميزة الإدخال ، متبوعة بمجموعة من النماذج الشبكية ومعايرة اختيارية لمعايرة خطية للإخراج.
التهيئة الصريحة لمجموعة شعرية
إذا كنت تعرف بالفعل المجموعات الفرعية من الميزات التي تريد إدخالها في المشابك الخاصة بك ، فيمكنك حينئذٍ تعيين المشابك صراحةً باستخدام أسماء الميزات. ينشئ هذا المثال نموذج مجموعة شبكية معايرة مع 5 مشابك و 3 ميزات لكل شبكة.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
explicit_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices=[['trestbps', 'chol', 'ca'], ['fbs', 'restecg', 'thal'],
['fbs', 'cp', 'oldpeak'], ['exang', 'slope', 'thalach'],
['restecg', 'age', 'sex']],
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0])
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
explicit_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
explicit_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
explicit_ensemble_model, show_layer_names=False, rankdir='LR')
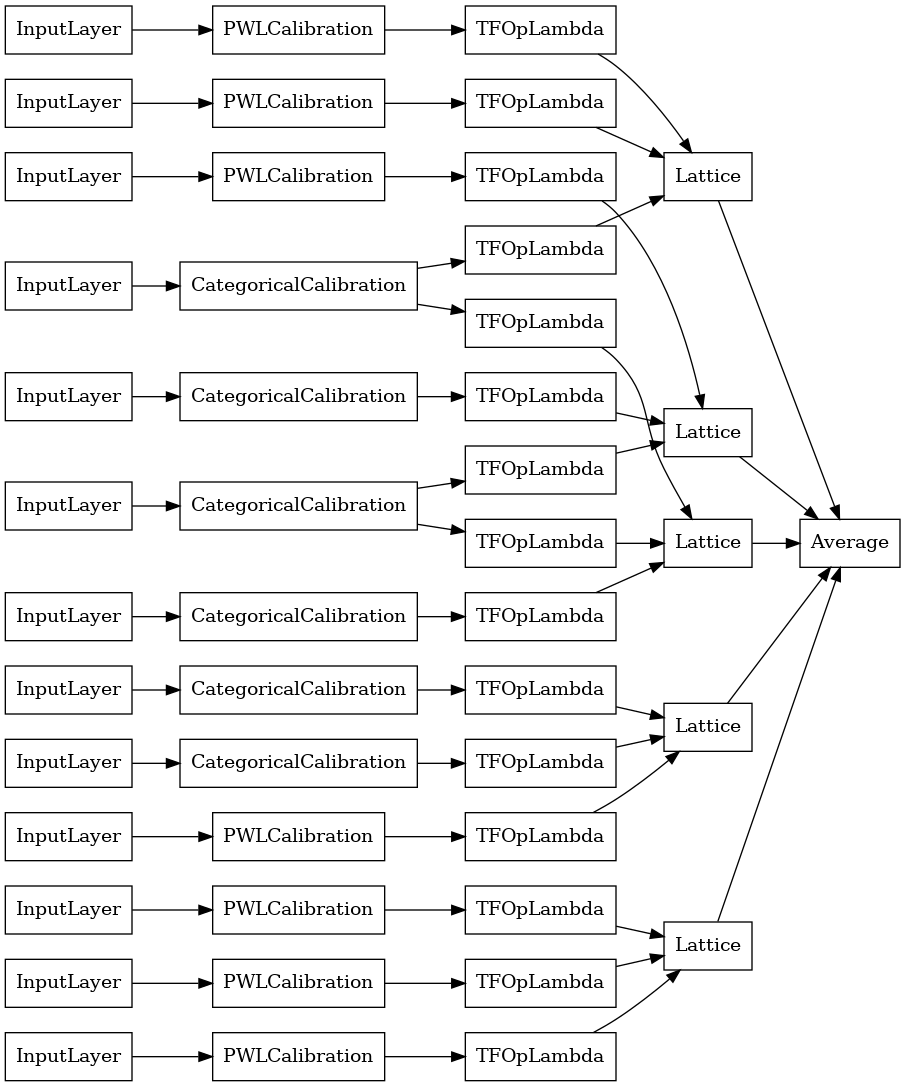
كما كان من قبل ، نقوم بتجميع نموذجنا وتكييفه وتقييمه.
explicit_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
explicit_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(explicit_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3768 - auc_2: 0.8954 [0.3768467903137207, 0.895363450050354]
فرقة شعرية عشوائية
إذا لم تكن متأكدًا من المجموعات الفرعية من الميزات التي يجب إدخالها في شبكاتك ، فهناك خيار آخر وهو استخدام مجموعات فرعية عشوائية من الميزات لكل شبكة. ينشئ هذا المثال نموذج مجموعة شبكية معايرة مع 5 مشابك و 3 ميزات لكل شبكة.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
random_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='random',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now we must set the random lattice structure and construct the model.
tfl.premade_lib.set_random_lattice_ensemble(random_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
random_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
random_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
random_ensemble_model, show_layer_names=False, rankdir='LR')
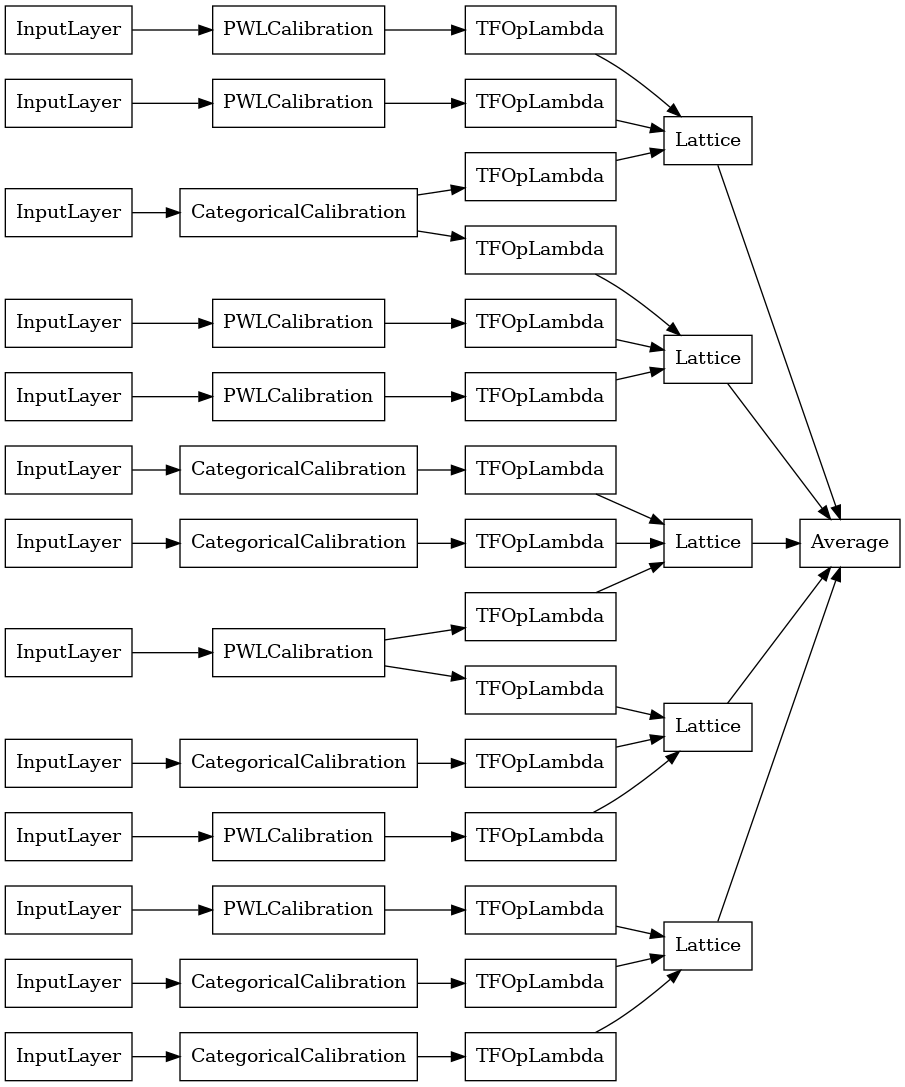
كما كان من قبل ، نقوم بتجميع نموذجنا وتكييفه وتقييمه.
random_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
random_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(random_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 4ms/step - loss: 0.3739 - auc_3: 0.8997 [0.3739270567893982, 0.8997493982315063]
RTL Layer Random Lattice فرقة
عند استخدام عشوائي شعرية الفرقة، يمكنك تحديد أن نموذج استخدام واحد tfl.layers.RTL طبقة. ونلاحظ أن tfl.layers.RTL يعتمد فقط القيود الرتابه في الصوت ويجب أن يكون نفس حجم شعرية لجميع الميزات وأي تسوية لكل ميزة. علما بأن استخدام tfl.layers.RTL طبقة يتيح لك مقياس لفرق أكبر بكثير من استخدام منفصلة tfl.layers.Lattice الحالات.
ينشئ هذا المثال نموذج مجموعة شبكية معايرة مع 5 مشابك و 3 ميزات لكل شبكة.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(heart_feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combined non-linearly and averaged using multiple lattice layers.
rtl_layer_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=rtl_layer_feature_configs,
lattices='rtl_layer',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config. Note that we do not have to specify the lattices by calling
# a helper function (like before with random) because the RTL Layer will take
# care of that for us.
rtl_layer_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
rtl_layer_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
rtl_layer_ensemble_model, show_layer_names=False, rankdir='LR')
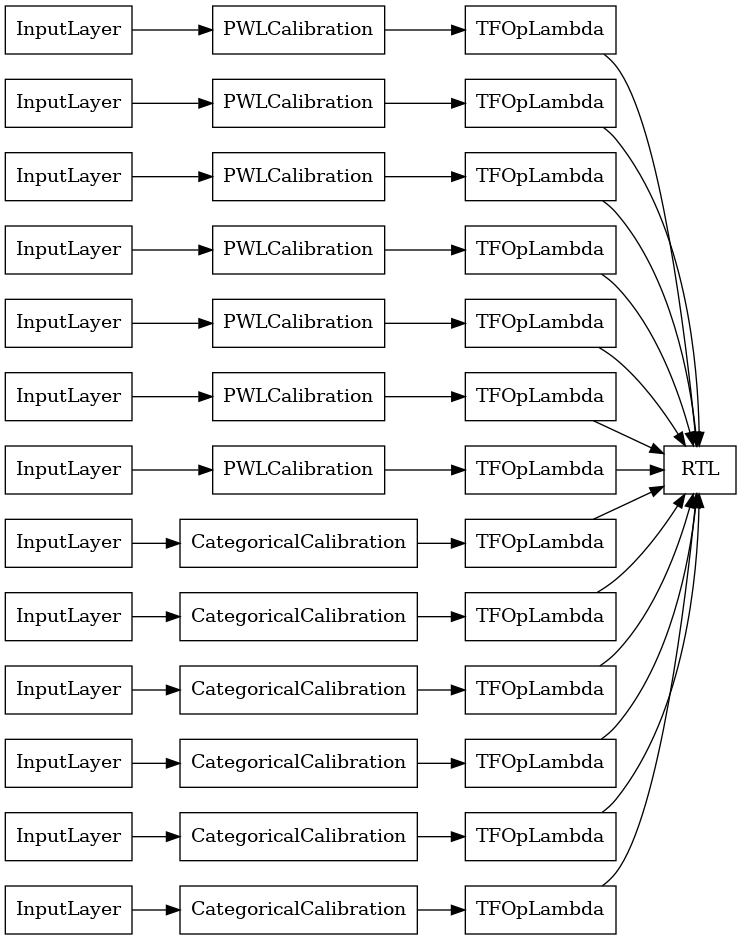
كما كان من قبل ، نقوم بتجميع نموذجنا وتكييفه وتقييمه.
rtl_layer_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
rtl_layer_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(rtl_layer_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 0s 3ms/step - loss: 0.3614 - auc_4: 0.9079 [0.36142951250076294, 0.9078947305679321]
مجموعة بلورات شعرية
كما يوفر ولم يضف على مجريات الأمور خوارزمية ترتيب ميزة تسمى بلورات . لاستخدام خوارزمية البلورات ، نقوم أولاً بتدريب نموذج تفضيلي يقدر تفاعلات الميزات الزوجية. ثم نقوم بترتيب المجموعة النهائية بحيث تكون الميزات ذات التفاعلات غير الخطية في نفس المشابك.
تقدم مكتبة Premade وظائف مساعدة لإنشاء تكوين نموذج التهيئة واستخراج هيكل البلورات. لاحظ أن نموذج الإعداد المسبق لا يحتاج إلى تدريب كامل ، لذا يجب أن تكون فترات قليلة كافية.
ينشئ هذا المثال نموذج مجموعة شعرية معايرة مع 5 شعرية و 3 ميزات لكل شبكة.
# This is a calibrated lattice ensemble model: inputs are calibrated, then
# combines non-linearly and averaged using multiple lattice layers.
crystals_ensemble_model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=heart_feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3,
# We initialize the output to [-2.0, 2.0] since we'll be using logits.
output_initialization=[-2.0, 2.0],
random_seed=42)
# Now that we have our model config, we can construct a prefitting model config.
prefitting_model_config = tfl.premade_lib.construct_prefitting_model_config(
crystals_ensemble_model_config)
# A CalibratedLatticeEnsemble premade model constructed from the given
# prefitting model config.
prefitting_model = tfl.premade.CalibratedLatticeEnsemble(
prefitting_model_config)
# We can compile and train our prefitting model as we like.
prefitting_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
prefitting_model.fit(
heart_train_xs,
heart_train_ys,
epochs=PREFITTING_NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
# Now that we have our trained prefitting model, we can extract the crystals.
tfl.premade_lib.set_crystals_lattice_ensemble(crystals_ensemble_model_config,
prefitting_model_config,
prefitting_model)
# A CalibratedLatticeEnsemble premade model constructed from the given
# model config.
crystals_ensemble_model = tfl.premade.CalibratedLatticeEnsemble(
crystals_ensemble_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
crystals_ensemble_model, show_layer_names=False, rankdir='LR')
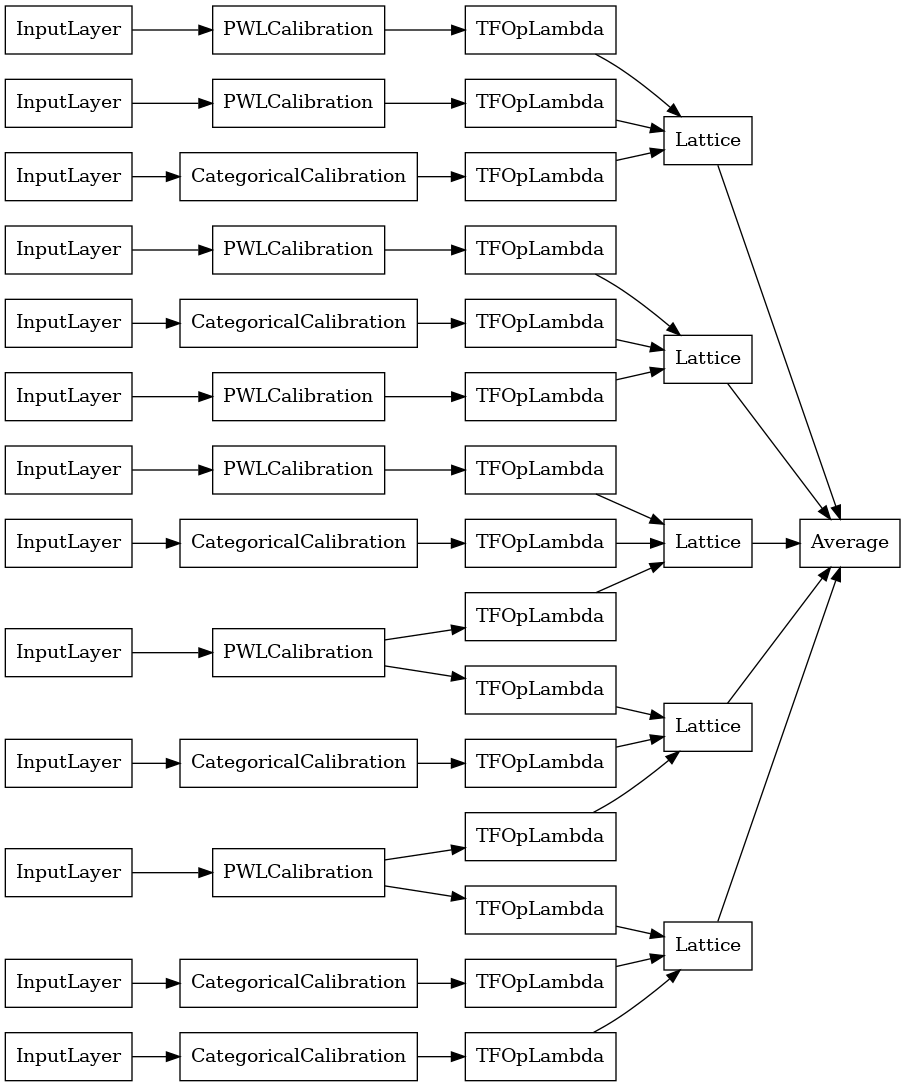
كما كان من قبل ، نقوم بتجميع نموذجنا وتكييفه وتقييمه.
crystals_ensemble_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)],
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
crystals_ensemble_model.fit(
heart_train_xs,
heart_train_ys,
epochs=NUM_EPOCHS,
batch_size=BATCH_SIZE,
verbose=False)
print('Test Set Evaluation...')
print(crystals_ensemble_model.evaluate(heart_test_xs, heart_test_ys))
Test Set Evaluation... 2/2 [==============================] - 1s 3ms/step - loss: 0.3404 - auc_5: 0.9179 [0.34039050340652466, 0.9179198145866394]