
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই টিউটোরিয়ালটি TensorFlow Lattice (TFL) লাইব্রেরি দ্বারা প্রদত্ত সীমাবদ্ধতা এবং নিয়মিতকরণের একটি ওভারভিউ। এখানে আমরা সিন্থেটিক ডেটাসেটগুলিতে TFL টিনজাত অনুমানকারী ব্যবহার করি, তবে মনে রাখবেন যে এই টিউটোরিয়ালের সমস্ত কিছু TFL Keras স্তরগুলি থেকে নির্মিত মডেলগুলির সাথেও করা যেতে পারে।
এগিয়ে যাওয়ার আগে, নিশ্চিত করুন যে আপনার রানটাইমে সমস্ত প্রয়োজনীয় প্যাকেজ ইনস্টল করা আছে (নিচের কোড কক্ষে আমদানি করা হয়েছে)।
সেটআপ
টিএফ ল্যাটিস প্যাকেজ ইনস্টল করা হচ্ছে:
pip install -q tensorflow-lattice
প্রয়োজনীয় প্যাকেজ আমদানি করা হচ্ছে:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
এই নির্দেশিকায় ব্যবহৃত ডিফল্ট মান:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
রেস্তোরাঁর জন্য প্রশিক্ষণ ডেটাসেট
একটি সরলীকৃত দৃশ্যকল্প কল্পনা করুন যেখানে আমরা নির্ধারণ করতে চাই যে ব্যবহারকারীরা রেস্তোরাঁর অনুসন্ধান ফলাফলে ক্লিক করবে কিনা। কাজটি হল ক্লিকথ্রু রেট (CTR) প্রদত্ত ইনপুট বৈশিষ্ট্যগুলির পূর্বাভাস দেওয়া:
- গড় রেটিং (
avg_rating): পরিসীমা [1,5] এ মান সঙ্গে একটি সাংখ্যিক বৈশিষ্ট্য। - রিভিউ নম্বর (
num_reviews): 200 এ লাভের মান, যা আমরা trendiness একটি পরিমাপ হিসাবে ব্যবহার সঙ্গে একটি সাংখ্যিক বৈশিষ্ট্য। - ডলার রেটিং (
dollar_rating): সেট { "ডি", "ডিডি", "DDD", "DDDD"} মধ্যে স্ট্রিং মান সঙ্গে একটি শ্রেণীগত বৈশিষ্ট্য।
এখানে আমরা একটি সিন্থেটিক ডেটাসেট তৈরি করি যেখানে সূত্র দ্বারা সত্য CTR দেওয়া হয়:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
যেখানে \(b(\cdot)\) প্রতিটি অনুবাদ dollar_rating একটি বেসলাইন মান:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
এই সূত্রটি সাধারণ ব্যবহারকারীর নিদর্শন প্রতিফলিত করে। যেমন অন্য সব কিছু ঠিক করা হয়েছে, ব্যবহারকারীরা উচ্চতর স্টার রেটিং সহ রেস্তোরাঁ পছন্দ করে এবং "\$\$" রেস্তোরাঁগুলি "\$" এর থেকে বেশি ক্লিক পাবে, তারপরে "\$\$\$" এবং "\$\$\$" \$"।
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
আসুন এই CTR ফাংশনের কনট্যুর প্লটগুলি একবার দেখে নেওয়া যাক।
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
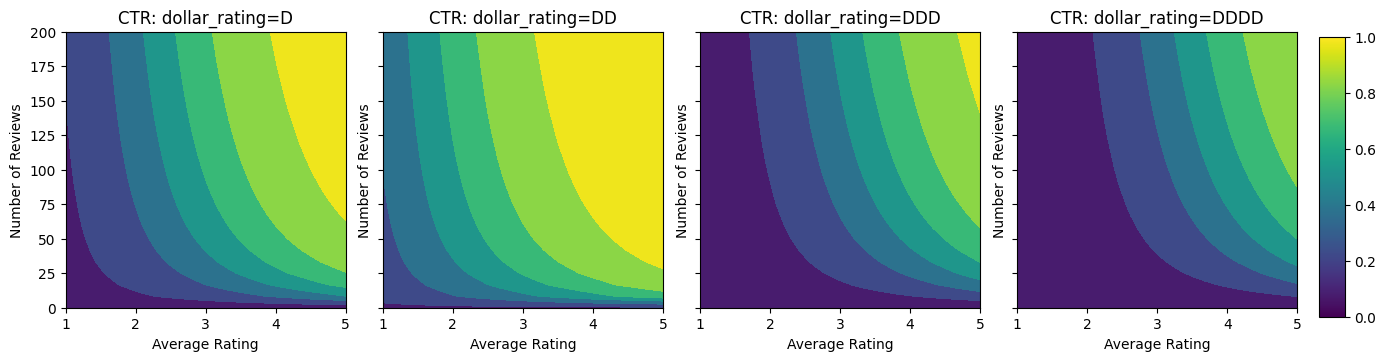
ডেটা প্রস্তুত করা হচ্ছে
আমাদের এখন আমাদের সিন্থেটিক ডেটাসেট তৈরি করতে হবে। আমরা রেস্টুরেন্ট এবং তাদের বৈশিষ্ট্যগুলির একটি সিমুলেটেড ডেটাসেট তৈরি করে শুরু করি।
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
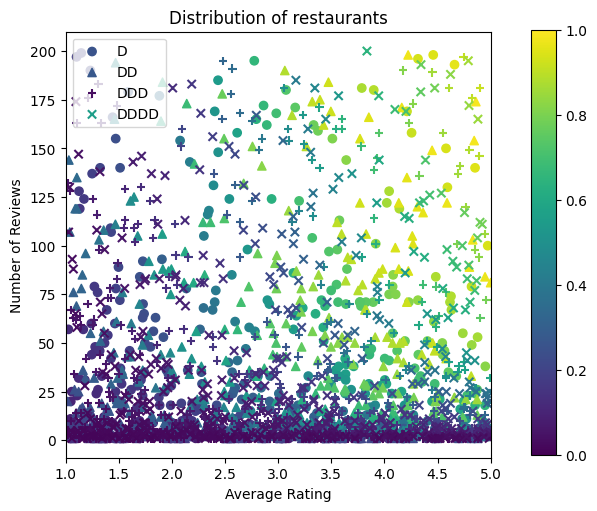
আসুন প্রশিক্ষণ, বৈধতা এবং পরীক্ষার ডেটাসেট তৈরি করি। যখন একটি রেস্তোরাঁ সার্চের ফলাফলে দেখা হয়, আমরা নমুনা পয়েন্ট হিসাবে ব্যবহারকারীর ব্যস্ততা (ক্লিক বা না ক্লিক) রেকর্ড করতে পারি।
অনুশীলনে, ব্যবহারকারীরা প্রায়শই সমস্ত অনুসন্ধান ফলাফলের মধ্য দিয়ে যান না। এর মানে হল যে ব্যবহারকারীরা সম্ভবত শুধুমাত্র সেই রেস্তোরাঁগুলিকেই দেখতে পাবেন যা ইতিমধ্যেই ব্যবহার করা বর্তমান র্যাঙ্কিং মডেল দ্বারা "ভাল" বলে বিবেচিত হয়েছে৷ ফলস্বরূপ, "ভাল" রেস্তোরাঁগুলি প্রায়শই প্রভাবিত হয় এবং প্রশিক্ষণের ডেটাসেটে অতিরিক্তভাবে উপস্থাপন করা হয়। আরও বৈশিষ্ট্য ব্যবহার করার সময়, প্রশিক্ষণ ডেটাসেটের বৈশিষ্ট্য স্থানের "খারাপ" অংশগুলিতে বড় ফাঁক থাকতে পারে।
যখন মডেলটি র্যাঙ্কিংয়ের জন্য ব্যবহার করা হয়, তখন এটি প্রায়শই সমস্ত প্রাসঙ্গিক ফলাফলে আরও অভিন্ন বন্টনের সাথে মূল্যায়ন করা হয় যা প্রশিক্ষণ ডেটাসেটের দ্বারা ভালভাবে উপস্থাপন করা হয় না। একটি নমনীয় এবং জটিল মডেল এই ক্ষেত্রে ব্যর্থ হতে পারে অতিরিক্ত উপস্থাপিত ডেটা পয়েন্টগুলি ওভারফিটিং করার কারণে এবং এইভাবে সাধারণীকরণের অভাব রয়েছে। আমরা আকৃতি সীমাবদ্ধতার যে যুক্তিসঙ্গত ভবিষ্যৎবাণী যখন তাদেরকে প্রশিক্ষণ ডেটা সেটটি থেকে নিতে পারে না করতে মডেল গাইড যোগ করার জন্য ডোমেইন জ্ঞান প্রয়োগের দ্বারা এই সমস্যা হ্যান্ডেল।
এই উদাহরণে, প্রশিক্ষণ ডেটাসেটে বেশিরভাগই ভাল এবং জনপ্রিয় রেস্তোরাঁর সাথে ব্যবহারকারীর মিথস্ক্রিয়া থাকে। উপরে আলোচনা করা মূল্যায়ন সেটিং অনুকরণ করার জন্য টেস্টিং ডেটাসেটের একটি অভিন্ন বন্টন রয়েছে। মনে রাখবেন যে এই ধরনের টেস্টিং ডেটাসেট একটি বাস্তব সমস্যা সেটিংসে উপলব্ধ হবে না।
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

প্রশিক্ষণ এবং মূল্যায়নের জন্য ব্যবহৃত input_fns সংজ্ঞায়িত করা:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
ফিটিং গ্রেডিয়েন্ট বুস্টেড গাছ
: এর মাত্র দুই বৈশিষ্ট্য সঙ্গে চলতে শুরু করা যাক avg_rating এবং num_reviews ।
আমরা যাচাইকরণ এবং পরীক্ষার মেট্রিক্স প্লট এবং গণনা করার জন্য কয়েকটি সহায়ক ফাংশন তৈরি করি।
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
আমরা ডেটাসেটে টেনসরফ্লো গ্রেডিয়েন্ট বুস্টেড ডিসিশন ট্রি ফিট করতে পারি:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

যদিও মডেলটি সত্যিকারের CTR-এর সাধারণ আকৃতি ধারণ করেছে এবং এর শালীন বৈধতা মেট্রিক্স রয়েছে, তবুও ইনপুট স্পেসের বিভিন্ন অংশে এর কাউন্টার-ইনটুইটিভ আচরণ রয়েছে: গড় রেটিং বা পর্যালোচনার সংখ্যা বাড়ার সাথে সাথে আনুমানিক CTR হ্রাস পায়। এটি প্রশিক্ষণ ডেটাসেটের দ্বারা ভালভাবে আচ্ছাদিত নয় এমন এলাকায় নমুনা পয়েন্টের অভাবের কারণে। মডেলটির কেবলমাত্র ডেটা থেকে সঠিক আচরণ বের করার কোন উপায় নেই।
এই সমস্যাটি সমাধান করার জন্য, আমরা আকৃতির সীমাবদ্ধতা প্রয়োগ করি যে মডেলটিকে অবশ্যই গড় রেটিং এবং পর্যালোচনার সংখ্যা উভয়ের সাপেক্ষে একঘেয়ে মান বৃদ্ধি করতে হবে। আমরা পরে দেখব কীভাবে এটি টিএফএল-এ বাস্তবায়ন করা যায়।
একটি DNN ফিটিং
আমরা একটি DNN ক্লাসিফায়ার দিয়ে একই পদক্ষেপগুলি পুনরাবৃত্তি করতে পারি। আমরা একটি অনুরূপ প্যাটার্ন পর্যবেক্ষণ করতে পারি: অল্প সংখ্যক পর্যালোচনা সহ পর্যাপ্ত নমুনা পয়েন্ট না থাকার ফলে অর্থহীন এক্সট্রাপোলেশন হয়। মনে রাখবেন যে যদিও বৈধতা মেট্রিকটি ট্রি সলিউশনের চেয়ে ভালো, কিন্তু টেস্টিং মেট্রিক অনেক খারাপ।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

আকৃতির সীমাবদ্ধতা
টেনসরফ্লো ল্যাটিস (টিএফএল) প্রশিক্ষণ ডেটার বাইরে মডেল আচরণকে সুরক্ষিত করার জন্য আকৃতির সীমাবদ্ধতা প্রয়োগ করার উপর দৃষ্টি নিবদ্ধ করে। এই আকৃতির সীমাবদ্ধতাগুলি টিএফএল কেরাস স্তরগুলিতে প্রয়োগ করা হয়। তাদের বিবরণ খুঁজে পাওয়া যেতে পারে আমাদের JMLR কাগজ ।
এই টিউটোরিয়ালে আমরা বিভিন্ন আকারের সীমাবদ্ধতাগুলি কভার করার জন্য TF টিনজাত অনুমানকারী ব্যবহার করি, তবে মনে রাখবেন যে এই সমস্ত পদক্ষেপগুলি TFL কেরাস স্তরগুলি থেকে তৈরি মডেলগুলির সাথে করা যেতে পারে।
অন্য কোন TensorFlow মূল্নির্ধারক হিসাবে, TfL টিনজাত estimators ব্যবহার বৈশিষ্ট্য কলাম ইনপুট ফর্ম্যাট এবং সংজ্ঞায়িত একটি প্রশিক্ষণ input_fn ব্যবহার ডেটাতে পাস করতে। TFL টিনজাত অনুমানকারী ব্যবহার করারও প্রয়োজন:
- একটি মডেল: config মডেল আর্কিটেকচার এবং প্রতি-বৈশিষ্ট্য আকৃতি সীমাবদ্ধতার এবং regularizers সংজ্ঞা।
- একটি বৈশিষ্ট্য বিশ্লেষণ input_fn: TfL আরম্ভের জন্য তথ্য ক্ষণস্থায়ী input_fn একটি TF।
আরও পুঙ্খানুপুঙ্খ বর্ণনার জন্য, অনুগ্রহ করে ক্যানড এস্টিমেটর টিউটোরিয়াল বা API ডক্স দেখুন।
একঘেয়েমি
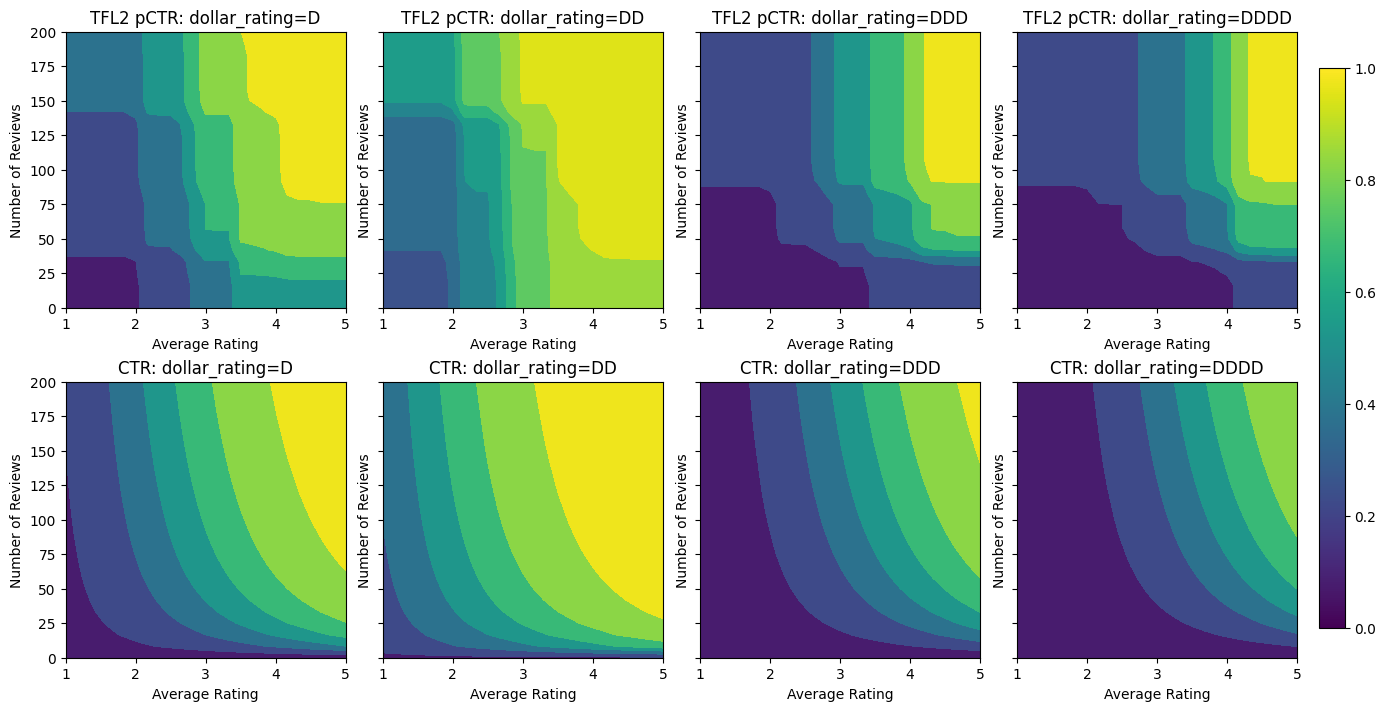
আমরা প্রথমে উভয় বৈশিষ্ট্যে একঘেয়েমি আকৃতির সীমাবদ্ধতা যুক্ত করে একঘেয়েতার উদ্বেগের সমাধান করি।
TfL নির্দেশ আকৃতি সীমাবদ্ধতার জোরদার করা, আমরা বৈশিষ্ট্য configs মধ্যে সীমাবদ্ধতা উল্লেখ করুন। নিম্নলিখিত কোড দেখায় কিভাবে আমরা আউটপুট প্রয়োজন হতে পারে monotonically উভয় থেকে সম্মান সঙ্গে বৃদ্ধি হতে num_reviews এবং avg_rating সেটিং দ্বারা monotonicity="increasing" ।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

একটি ব্যবহার CalibratedLatticeConfig একটি টিনজাত ক্লাসিফায়ার যে প্রথম প্রতিটি ইনপুট (এক টুকরা ভিত্তিক সাংখ্যিক বৈশিষ্ট্যগুলির জন্য রৈখিক ফাংশন) করার জন্য একটি ক্যালিব্রেটর প্রযোজ্য সৃষ্টি করে মডেলটির ক্রমাঙ্ক বৈশিষ্ট্য ফিউজ অ সুসংগত একটি জাফরি স্তর অনুসরণ। আমরা ব্যবহার করতে পারি tfl.visualization মডেল ঠাহর করতে। বিশেষ করে, নিম্নলিখিত প্লটটি ক্যানড ক্লাসিফায়ারে অন্তর্ভুক্ত দুটি প্রশিক্ষিত ক্যালিব্রেটর দেখায়।
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

সীমাবদ্ধতা যোগ করা হলে, গড় রেটিং বাড়লে বা পর্যালোচনার সংখ্যা বাড়লে আনুমানিক CTR সবসময় বাড়বে। ক্যালিব্রেটর এবং জালি একঘেয়ে হয় তা নিশ্চিত করে এটি করা হয়।
আয় কমা
আয় কমা মানে যে একটি নির্দিষ্ট বৈশিষ্ট্য মান বৃদ্ধি প্রান্তিক লাভ হিসাবে আমরা মান বৃদ্ধি লাঘব হবে। আমাদের ক্ষেত্রে আমরা যে আশা num_reviews বৈশিষ্ট্য তাই আমরা তার ক্যালিব্রেটর তদনুসারে কনফিগার করতে পারেন, এই প্যাটার্ন অনুসরণ করে। লক্ষ্য করুন যে আমরা দুটি পর্যাপ্ত অবস্থায় হ্রাসকারী রিটার্নগুলিকে পচিয়ে দিতে পারি:
- ক্যালিব্রেটর একঘেয়েভাবে বাড়ছে, এবং
- ক্যালিব্রেটরটি অবতল।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
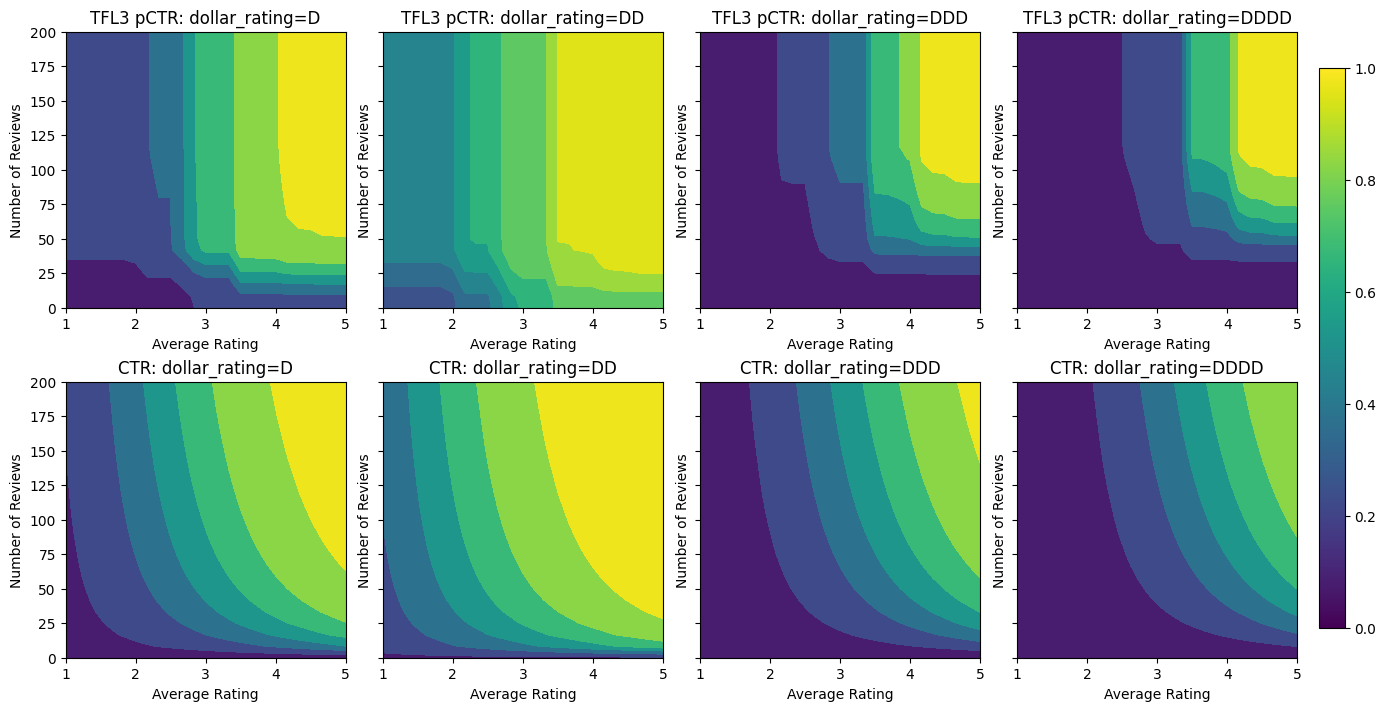

কনক্যাভিটি সীমাবদ্ধতা যোগ করে পরীক্ষার মেট্রিক কীভাবে উন্নত হয় তা লক্ষ্য করুন। ভবিষ্যদ্বাণীর প্লটটি স্থল সত্যের সাথে আরও ভাল সাদৃশ্যপূর্ণ।
2D আকারের সীমাবদ্ধতা: বিশ্বাস
শুধুমাত্র এক বা দুটি রিভিউ সহ একটি রেস্তোরাঁর জন্য 5-তারকা রেটিং সম্ভবত একটি অবিশ্বস্ত রেটিং (রেস্তোরাঁটি আসলে ভাল নাও হতে পারে), যেখানে শত শত পর্যালোচনা সহ একটি রেস্তোরাঁর জন্য 4-স্টার রেটিং অনেক বেশি নির্ভরযোগ্য (রেস্তোরাঁটি হল সম্ভবত এই ক্ষেত্রে ভাল)। আমরা দেখতে পাচ্ছি যে একটি রেস্তোরাঁর পর্যালোচনার সংখ্যা তার গড় রেটিংকে আমরা কতটা বিশ্বাস করি তা প্রভাবিত করে।
আমরা মডেলকে জানাতে TFL বিশ্বাসের সীমাবদ্ধতা অনুশীলন করতে পারি যে একটি বৈশিষ্ট্যের বড় (বা ছোট) মান অন্য বৈশিষ্ট্যের উপর নির্ভরতা বা বিশ্বাসকে নির্দেশ করে। এই সেটিংস এর দ্বারা সম্পন্ন করা হয় reflects_trust_in বৈশিষ্ট্য কনফিগ মধ্যে কনফিগারেশন।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

নিম্নলিখিত প্লটটি প্রশিক্ষিত জালি ফাংশন উপস্থাপন করে। ট্রাস্ট বাধ্যতা কারণে, আমরা আশা করি, মডেলটির ক্রমাঙ্ক বড় মান num_reviews মডেলটির ক্রমাঙ্ক থেকে সম্মান সঙ্গে উচ্চতর ঢাল জোর দেবে avg_rating , জাফরি আউটপুট মধ্যে আরো গুরুত্বপূর্ণ পদক্ষেপ ফলে।
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
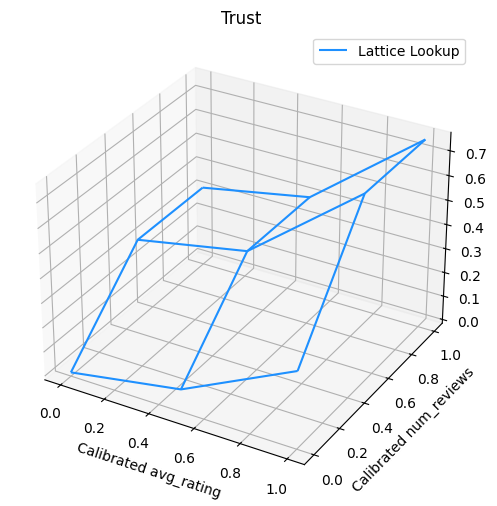
মসৃণ ক্যালিব্রেটর
এখন এর ক্যালিব্রেটর কটাক্ষপাত করা যাক avg_rating । যদিও এটি একঘেয়েভাবে বৃদ্ধি পাচ্ছে, এর ঢালের পরিবর্তনগুলি আকস্মিক এবং ব্যাখ্যা করা কঠিন। যে প্রস্তাব দেওয়া আমরা এই ক্যালিব্রেটর একটি regularizer সেটআপ ব্যবহার মসৃণকরণ বিবেচনা করতে পারে regularizer_configs ।
এখানে আমরা একটি আবেদন wrinkle regularizer বক্রতা পরিবর্তন কমাতে। এছাড়াও আপনি ব্যবহার করতে পারেন laplacian ক্যালিব্রেটর এবং চেপ্টা করার regularizer hessian regularizer এটি আরো রৈখিক করা।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


ক্যালিব্রেটরগুলি এখন মসৃণ, এবং সামগ্রিক আনুমানিক CTR গ্রাউন্ড ট্রুথের সাথে ভাল মেলে। এটি পরীক্ষার মেট্রিক এবং কনট্যুর প্লট উভয় ক্ষেত্রেই প্রতিফলিত হয়।
শ্রেণীবদ্ধ ক্রমাঙ্কনের জন্য আংশিক একঘেয়েমি
এখন পর্যন্ত আমরা মডেলটিতে মাত্র দুটি সংখ্যাসূচক বৈশিষ্ট্য ব্যবহার করছি। এখানে আমরা একটি শ্রেণীবদ্ধ ক্রমাঙ্কন স্তর ব্যবহার করে একটি তৃতীয় বৈশিষ্ট্য যোগ করব। আবার আমরা প্লটিং এবং মেট্রিক গণনার জন্য সহায়ক ফাংশন সেট আপ করে শুরু করি।
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
তৃতীয় বৈশিষ্ট্য জড়িত, dollar_rating , আমরা যে নিঃশর্ত বৈশিষ্ট্যগুলি উভয়ের একটি বৈশিষ্ট্য কলাম হিসাবে এবং একটি বৈশিষ্ট্য কনফিগ যেমন TfL একটি কিছুটা ভিন্ন চিকিত্সা, প্রয়োজন প্রত্যাহার করা উচিত নয়। এখানে আমরা আংশিক একঘেয়েতার সীমাবদ্ধতা প্রয়োগ করি যে "DD" রেস্তোরাঁর আউটপুটগুলি "D" রেস্তোরাঁর থেকে বড় হওয়া উচিত যখন অন্যান্য সমস্ত ইনপুট ঠিক করা হয়৷ এই ব্যবহার করা যাবে monotonicity বৈশিষ্ট্য কনফিগ সেটিংগুলি।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


এই শ্রেণীবদ্ধ ক্যালিব্রেটর মডেল আউটপুটের পছন্দ দেখায়: DD > D > DDD > DDDD, যা আমাদের সেটআপের সাথে সামঞ্জস্যপূর্ণ। লক্ষ্য করুন অনুপস্থিত মানগুলির জন্য একটি কলামও রয়েছে। যদিও আমাদের প্রশিক্ষণ এবং পরীক্ষার ডেটাতে কোনও অনুপস্থিত বৈশিষ্ট্য নেই, মডেলটি আমাদের অনুপস্থিত মানটির জন্য একটি অনুমান প্রদান করে যদি এটি ডাউনস্ট্রিম মডেল পরিবেশনের সময় ঘটে থাকে।
এখানে আমরা এই মডেল নিয়ন্ত্রিত পূর্বাভাস CTR এর প্লটে বিভক্ত dollar_rating । লক্ষ্য করুন যে আমাদের প্রয়োজনীয় সমস্ত সীমাবদ্ধতা প্রতিটি স্লাইসে পূরণ করা হয়েছে।
আউটপুট ক্রমাঙ্কন
আমরা এখন পর্যন্ত প্রশিক্ষিত সমস্ত TFL মডেলের জন্য, জালি স্তর (মডেল গ্রাফে "ল্যাটিস" হিসাবে নির্দেশিত) সরাসরি মডেলের ভবিষ্যদ্বাণী প্রকাশ করে। কখনও কখনও আমরা নিশ্চিত নই যে মডেল আউটপুট নির্গত করার জন্য জালির আউটপুট পুনরায় স্কেল করা উচিত কিনা:
- বৈশিষ্ট্য \(log\) গন্য যখন লেবেল গন্য হয়।
- জালিটি খুব কম শীর্ষবিন্দু থাকার জন্য কনফিগার করা হয়েছে তবে লেবেল বিতরণ তুলনামূলকভাবে জটিল।
এই ক্ষেত্রে আমরা মডেলের নমনীয়তা বাড়ানোর জন্য জালি আউটপুট এবং মডেল আউটপুটের মধ্যে আরেকটি ক্যালিব্রেটর যোগ করতে পারি। এখানে আমাদের তৈরি করা মডেলটিতে 5টি কীপয়েন্ট সহ একটি ক্যালিব্রেটর স্তর যুক্ত করা যাক। ফাংশনটি মসৃণ রাখতে আমরা আউটপুট ক্যালিব্রেটরের জন্য একটি রেগুলারাইজার যোগ করি।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


চূড়ান্ত পরীক্ষার মেট্রিক এবং প্লটগুলি দেখায় যে কীভাবে সাধারণ জ্ঞানের সীমাবদ্ধতা ব্যবহার করে মডেলটিকে অপ্রত্যাশিত আচরণ এড়াতে এবং সম্পূর্ণ ইনপুট স্থানকে আরও ভালভাবে এক্সট্রাপোলেট করতে সহায়তা করতে পারে।
,| | | GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই টিউটোরিয়ালটি TensorFlow Lattice (TFL) লাইব্রেরি দ্বারা প্রদত্ত সীমাবদ্ধতা এবং নিয়মিতকরণের একটি ওভারভিউ। এখানে আমরা সিন্থেটিক ডেটাসেটগুলিতে TFL টিনজাত অনুমানকারী ব্যবহার করি, তবে মনে রাখবেন যে এই টিউটোরিয়ালের সমস্ত কিছু TFL Keras স্তরগুলি থেকে নির্মিত মডেলগুলির সাথেও করা যেতে পারে।
এগিয়ে যাওয়ার আগে, নিশ্চিত করুন যে আপনার রানটাইমে সমস্ত প্রয়োজনীয় প্যাকেজ ইনস্টল করা আছে (নিচের কোড কক্ষে আমদানি করা হয়েছে)।
সেটআপ
টিএফ ল্যাটিস প্যাকেজ ইনস্টল করা হচ্ছে:
pip install -q tensorflow-lattice
প্রয়োজনীয় প্যাকেজ আমদানি করা হচ্ছে:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
এই নির্দেশিকায় ব্যবহৃত ডিফল্ট মান:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
রেস্তোরাঁর জন্য প্রশিক্ষণ ডেটাসেট
একটি সরলীকৃত দৃশ্যকল্প কল্পনা করুন যেখানে আমরা নির্ধারণ করতে চাই যে ব্যবহারকারীরা রেস্তোরাঁর অনুসন্ধান ফলাফলে ক্লিক করবে কিনা। কাজটি হল ক্লিকথ্রু রেট (CTR) প্রদত্ত ইনপুট বৈশিষ্ট্যগুলির পূর্বাভাস দেওয়া:
- গড় রেটিং (
avg_rating): পরিসীমা [1,5] এ মান সঙ্গে একটি সাংখ্যিক বৈশিষ্ট্য। - রিভিউ নম্বর (
num_reviews): 200 এ লাভের মান, যা আমরা trendiness একটি পরিমাপ হিসাবে ব্যবহার সঙ্গে একটি সাংখ্যিক বৈশিষ্ট্য। - ডলার রেটিং (
dollar_rating): সেট { "ডি", "ডিডি", "DDD", "DDDD"} মধ্যে স্ট্রিং মান সঙ্গে একটি শ্রেণীগত বৈশিষ্ট্য।
এখানে আমরা একটি সিন্থেটিক ডেটাসেট তৈরি করি যেখানে সূত্র দ্বারা সত্য CTR দেওয়া হয়:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
যেখানে \(b(\cdot)\) প্রতিটি অনুবাদ dollar_rating একটি বেসলাইন মান:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
এই সূত্রটি সাধারণ ব্যবহারকারীর নিদর্শন প্রতিফলিত করে। যেমন অন্য সব কিছু ঠিক করা হয়েছে, ব্যবহারকারীরা উচ্চতর স্টার রেটিং সহ রেস্তোরাঁ পছন্দ করে এবং "\$\$" রেস্তোরাঁগুলি "\$" এর থেকে বেশি ক্লিক পাবে, তারপরে "\$\$\$" এবং "\$\$\$" \$"।
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
আসুন এই CTR ফাংশনের কনট্যুর প্লটগুলি একবার দেখে নেওয়া যাক।
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
ডেটা প্রস্তুত করা হচ্ছে
আমাদের এখন আমাদের সিন্থেটিক ডেটাসেট তৈরি করতে হবে। আমরা রেস্টুরেন্ট এবং তাদের বৈশিষ্ট্যগুলির একটি সিমুলেটেড ডেটাসেট তৈরি করে শুরু করি।
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
আসুন প্রশিক্ষণ, বৈধতা এবং পরীক্ষার ডেটাসেট তৈরি করি। যখন একটি রেস্তোরাঁ সার্চের ফলাফলে দেখা হয়, আমরা নমুনা পয়েন্ট হিসাবে ব্যবহারকারীর ব্যস্ততা (ক্লিক বা না ক্লিক) রেকর্ড করতে পারি।
অনুশীলনে, ব্যবহারকারীরা প্রায়শই সমস্ত অনুসন্ধান ফলাফলের মধ্য দিয়ে যান না। এর মানে হল যে ব্যবহারকারীরা সম্ভবত শুধুমাত্র সেই রেস্তোরাঁগুলিকেই দেখতে পাবেন যা ইতিমধ্যেই ব্যবহার করা বর্তমান র্যাঙ্কিং মডেল দ্বারা "ভাল" বলে বিবেচিত হয়েছে৷ ফলস্বরূপ, "ভাল" রেস্তোরাঁগুলি প্রায়শই প্রভাবিত হয় এবং প্রশিক্ষণের ডেটাসেটে অতিরিক্তভাবে উপস্থাপন করা হয়। আরও বৈশিষ্ট্য ব্যবহার করার সময়, প্রশিক্ষণ ডেটাসেটের বৈশিষ্ট্য স্থানের "খারাপ" অংশগুলিতে বড় ফাঁক থাকতে পারে।
যখন মডেলটি র্যাঙ্কিংয়ের জন্য ব্যবহার করা হয়, তখন এটি প্রায়শই সমস্ত প্রাসঙ্গিক ফলাফলে আরও অভিন্ন বন্টনের সাথে মূল্যায়ন করা হয় যা প্রশিক্ষণ ডেটাসেটের দ্বারা ভালভাবে উপস্থাপন করা হয় না। একটি নমনীয় এবং জটিল মডেল এই ক্ষেত্রে ব্যর্থ হতে পারে অতিরিক্ত উপস্থাপিত ডেটা পয়েন্টগুলি ওভারফিটিং করার কারণে এবং এইভাবে সাধারণীকরণের অভাব রয়েছে। আমরা আকৃতি সীমাবদ্ধতার যে যুক্তিসঙ্গত ভবিষ্যৎবাণী যখন তাদেরকে প্রশিক্ষণ ডেটা সেটটি থেকে নিতে পারে না করতে মডেল গাইড যোগ করার জন্য ডোমেইন জ্ঞান প্রয়োগের দ্বারা এই সমস্যা হ্যান্ডেল।
এই উদাহরণে, প্রশিক্ষণ ডেটাসেটে বেশিরভাগই ভাল এবং জনপ্রিয় রেস্তোরাঁর সাথে ব্যবহারকারীর মিথস্ক্রিয়া থাকে। উপরে আলোচনা করা মূল্যায়ন সেটিং অনুকরণ করার জন্য টেস্টিং ডেটাসেটের একটি অভিন্ন বন্টন রয়েছে। মনে রাখবেন যে এই ধরনের টেস্টিং ডেটাসেট একটি বাস্তব সমস্যা সেটিংসে উপলব্ধ হবে না।
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
প্রশিক্ষণ এবং মূল্যায়নের জন্য ব্যবহৃত input_fns সংজ্ঞায়িত করা:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
ফিটিং গ্রেডিয়েন্ট বুস্টেড গাছ
: এর মাত্র দুই বৈশিষ্ট্য সঙ্গে চলতে শুরু করা যাক avg_rating এবং num_reviews ।
আমরা যাচাইকরণ এবং পরীক্ষার মেট্রিক্স প্লট এবং গণনা করার জন্য কয়েকটি সহায়ক ফাংশন তৈরি করি।
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
আমরা ডেটাসেটে টেনসরফ্লো গ্রেডিয়েন্ট বুস্টেড ডিসিশন ট্রি ফিট করতে পারি:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
যদিও মডেলটি সত্যিকারের CTR-এর সাধারণ আকৃতি ধারণ করেছে এবং এর শালীন বৈধতা মেট্রিক্স রয়েছে, তবুও ইনপুট স্পেসের বিভিন্ন অংশে এর কাউন্টার-ইনটুইটিভ আচরণ রয়েছে: গড় রেটিং বা পর্যালোচনার সংখ্যা বাড়ার সাথে সাথে আনুমানিক CTR হ্রাস পায়। এটি প্রশিক্ষণ ডেটাসেটের দ্বারা ভালভাবে আচ্ছাদিত নয় এমন এলাকায় নমুনা পয়েন্টের অভাবের কারণে। মডেলটির কেবলমাত্র ডেটা থেকে সঠিক আচরণ বের করার কোন উপায় নেই।
এই সমস্যাটি সমাধান করার জন্য, আমরা আকৃতির সীমাবদ্ধতা প্রয়োগ করি যে মডেলটিকে অবশ্যই গড় রেটিং এবং পর্যালোচনার সংখ্যা উভয়ের সাপেক্ষে একঘেয়ে মান বৃদ্ধি করতে হবে। আমরা পরে দেখব কীভাবে এটি টিএফএল-এ বাস্তবায়ন করা যায়।
একটি DNN ফিটিং
আমরা একটি DNN ক্লাসিফায়ার দিয়ে একই পদক্ষেপগুলি পুনরাবৃত্তি করতে পারি। আমরা একটি অনুরূপ প্যাটার্ন পর্যবেক্ষণ করতে পারি: অল্প সংখ্যক পর্যালোচনা সহ পর্যাপ্ত নমুনা পয়েন্ট না থাকার ফলে অর্থহীন এক্সট্রাপোলেশন হয়। মনে রাখবেন যে যদিও বৈধতা মেট্রিকটি ট্রি সলিউশনের চেয়ে ভালো, কিন্তু টেস্টিং মেট্রিক অনেক খারাপ।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
আকৃতির সীমাবদ্ধতা
টেনসরফ্লো ল্যাটিস (টিএফএল) প্রশিক্ষণ ডেটার বাইরে মডেল আচরণকে সুরক্ষিত করার জন্য আকৃতির সীমাবদ্ধতা প্রয়োগ করার উপর দৃষ্টি নিবদ্ধ করে। এই আকৃতির সীমাবদ্ধতাগুলি টিএফএল কেরাস স্তরগুলিতে প্রয়োগ করা হয়। তাদের বিবরণ খুঁজে পাওয়া যেতে পারে আমাদের JMLR কাগজ ।
এই টিউটোরিয়ালে আমরা বিভিন্ন আকারের সীমাবদ্ধতাগুলি কভার করার জন্য TF টিনজাত অনুমানকারী ব্যবহার করি, তবে মনে রাখবেন যে এই সমস্ত পদক্ষেপগুলি TFL কেরাস স্তরগুলি থেকে তৈরি মডেলগুলির সাথে করা যেতে পারে।
অন্য কোন TensorFlow মূল্নির্ধারক হিসাবে, TfL টিনজাত estimators ব্যবহার বৈশিষ্ট্য কলাম ইনপুট ফর্ম্যাট এবং সংজ্ঞায়িত একটি প্রশিক্ষণ input_fn ব্যবহার ডেটাতে পাস করতে। টিএফএল ক্যানড এস্টিমেটর ব্যবহার করারও প্রয়োজন:
- একটি মডেল: config মডেল আর্কিটেকচার এবং প্রতি-বৈশিষ্ট্য আকৃতি সীমাবদ্ধতার এবং regularizers সংজ্ঞা।
- একটি বৈশিষ্ট্য বিশ্লেষণ input_fn: TfL আরম্ভের জন্য তথ্য ক্ষণস্থায়ী input_fn একটি TF।
আরও পুঙ্খানুপুঙ্খ বর্ণনার জন্য, অনুগ্রহ করে ক্যানড এস্টিমেটর টিউটোরিয়াল বা API ডক্স দেখুন।
একঘেয়েমি
আমরা প্রথমে উভয় বৈশিষ্ট্যে একঘেয়েমি আকৃতির সীমাবদ্ধতা যুক্ত করে একঘেয়েতার উদ্বেগের সমাধান করি।
TfL নির্দেশ আকৃতি সীমাবদ্ধতার জোরদার করা, আমরা বৈশিষ্ট্য configs মধ্যে সীমাবদ্ধতা উল্লেখ করুন। নিম্নলিখিত কোড দেখায় কিভাবে আমরা আউটপুট প্রয়োজন হতে পারে monotonically উভয় থেকে সম্মান সঙ্গে বৃদ্ধি হতে num_reviews এবং avg_rating সেটিং দ্বারা monotonicity="increasing" ।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
একটি ব্যবহার CalibratedLatticeConfig একটি টিনজাত ক্লাসিফায়ার যে প্রথম প্রতিটি ইনপুট (এক টুকরা ভিত্তিক সাংখ্যিক বৈশিষ্ট্যগুলির জন্য রৈখিক ফাংশন) করার জন্য একটি ক্যালিব্রেটর প্রযোজ্য সৃষ্টি করে মডেলটির ক্রমাঙ্ক বৈশিষ্ট্য ফিউজ অ সুসংগত একটি জাফরি স্তর অনুসরণ। আমরা ব্যবহার করতে পারি tfl.visualization মডেল ঠাহর করতে। বিশেষ করে, নিম্নলিখিত প্লটটি ক্যানড ক্লাসিফায়ারে অন্তর্ভুক্ত দুটি প্রশিক্ষিত ক্যালিব্রেটর দেখায়।
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
সীমাবদ্ধতা যোগ করা হলে, গড় রেটিং বাড়লে বা পর্যালোচনার সংখ্যা বাড়লে আনুমানিক CTR সবসময় বাড়বে। ক্যালিব্রেটর এবং জালি একঘেয়ে হয় তা নিশ্চিত করে এটি করা হয়।
আয় কমা
আয় কমা মানে যে একটি নির্দিষ্ট বৈশিষ্ট্য মান বৃদ্ধি প্রান্তিক লাভ হিসাবে আমরা মান বৃদ্ধি লাঘব হবে। আমাদের ক্ষেত্রে আমরা যে আশা num_reviews বৈশিষ্ট্য তাই আমরা তার ক্যালিব্রেটর তদনুসারে কনফিগার করতে পারেন, এই প্যাটার্ন অনুসরণ করে। লক্ষ্য করুন যে আমরা দুটি পর্যাপ্ত অবস্থায় হ্রাসকারী রিটার্নগুলিকে পচিয়ে দিতে পারি:
- ক্যালিব্রেটর একঘেয়েভাবে বাড়ছে, এবং
- ক্যালিব্রেটরটি অবতল।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
কনক্যাভিটি সীমাবদ্ধতা যোগ করে পরীক্ষার মেট্রিক কীভাবে উন্নত হয় তা লক্ষ্য করুন। ভবিষ্যদ্বাণীর প্লটটি স্থল সত্যের সাথে আরও ভাল সাদৃশ্যপূর্ণ।
2D আকারের সীমাবদ্ধতা: বিশ্বাস
শুধুমাত্র এক বা দুটি রিভিউ সহ একটি রেস্তোরাঁর জন্য 5-তারকা রেটিং সম্ভবত একটি অবিশ্বস্ত রেটিং (রেস্তোরাঁটি আসলে ভাল নাও হতে পারে), যেখানে শত শত পর্যালোচনা সহ একটি রেস্তোরাঁর জন্য 4-স্টার রেটিং অনেক বেশি নির্ভরযোগ্য (রেস্তোরাঁটি হল সম্ভবত এই ক্ষেত্রে ভাল)। আমরা দেখতে পাচ্ছি যে একটি রেস্তোরাঁর পর্যালোচনার সংখ্যা তার গড় রেটিংকে আমরা কতটা বিশ্বাস করি তা প্রভাবিত করে।
আমরা মডেলকে জানাতে TFL বিশ্বাসের সীমাবদ্ধতা অনুশীলন করতে পারি যে একটি বৈশিষ্ট্যের বড় (বা ছোট) মান অন্য বৈশিষ্ট্যের উপর নির্ভরতা বা বিশ্বাসকে নির্দেশ করে। এই সেটিংস এর দ্বারা সম্পন্ন করা হয় reflects_trust_in বৈশিষ্ট্য কনফিগ মধ্যে কনফিগারেশন।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
নিম্নলিখিত প্লটটি প্রশিক্ষিত জালি ফাংশন উপস্থাপন করে। ট্রাস্ট বাধ্যতা কারণে, আমরা আশা করি, মডেলটির ক্রমাঙ্ক বড় মান num_reviews মডেলটির ক্রমাঙ্ক থেকে সম্মান সঙ্গে উচ্চতর ঢাল জোর দেবে avg_rating , জাফরি আউটপুট মধ্যে আরো গুরুত্বপূর্ণ পদক্ষেপ ফলে।
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
মসৃণ ক্যালিব্রেটর
এখন এর ক্যালিব্রেটর কটাক্ষপাত করা যাক avg_rating । যদিও এটি একঘেয়েভাবে বৃদ্ধি পাচ্ছে, এর ঢালের পরিবর্তনগুলি আকস্মিক এবং ব্যাখ্যা করা কঠিন। যে প্রস্তাব দেওয়া আমরা এই ক্যালিব্রেটর একটি regularizer সেটআপ ব্যবহার মসৃণকরণ বিবেচনা করতে পারে regularizer_configs ।
এখানে আমরা একটি আবেদন wrinkle regularizer বক্রতা পরিবর্তন কমাতে। এছাড়াও আপনি ব্যবহার করতে পারেন laplacian ক্যালিব্রেটর এবং চেপ্টা করার regularizer hessian regularizer এটি আরো রৈখিক করা।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
ক্যালিব্রেটরগুলি এখন মসৃণ, এবং সামগ্রিক আনুমানিক CTR গ্রাউন্ড ট্রুথের সাথে ভাল মেলে। এটি পরীক্ষার মেট্রিক এবং কনট্যুর প্লট উভয় ক্ষেত্রেই প্রতিফলিত হয়।
শ্রেণীবদ্ধ ক্রমাঙ্কনের জন্য আংশিক একঘেয়েমি
এখন পর্যন্ত আমরা মডেলটিতে মাত্র দুটি সংখ্যাসূচক বৈশিষ্ট্য ব্যবহার করছি। এখানে আমরা একটি শ্রেণীবদ্ধ ক্রমাঙ্কন স্তর ব্যবহার করে একটি তৃতীয় বৈশিষ্ট্য যোগ করব। আবার আমরা প্লটিং এবং মেট্রিক গণনার জন্য সহায়ক ফাংশন সেট আপ করে শুরু করি।
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
তৃতীয় বৈশিষ্ট্য জড়িত, dollar_rating , আমরা যে নিঃশর্ত বৈশিষ্ট্যগুলি উভয়ের একটি বৈশিষ্ট্য কলাম হিসাবে এবং একটি বৈশিষ্ট্য কনফিগ যেমন TfL একটি কিছুটা ভিন্ন চিকিত্সা, প্রয়োজন প্রত্যাহার করা উচিত নয়। এখানে আমরা আংশিক একঘেয়েতার সীমাবদ্ধতা প্রয়োগ করি যে "DD" রেস্তোরাঁর আউটপুটগুলি "D" রেস্তোরাঁর থেকে বড় হওয়া উচিত যখন অন্যান্য সমস্ত ইনপুট ঠিক করা হয়৷ এই ব্যবহার করা যাবে monotonicity বৈশিষ্ট্য কনফিগ সেটিংগুলি।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
এই শ্রেণীবদ্ধ ক্যালিব্রেটর মডেল আউটপুটের পছন্দ দেখায়: DD > D > DDD > DDDD, যা আমাদের সেটআপের সাথে সামঞ্জস্যপূর্ণ। লক্ষ্য করুন অনুপস্থিত মানগুলির জন্য একটি কলামও রয়েছে। যদিও আমাদের প্রশিক্ষণ এবং পরীক্ষার ডেটাতে কোনও অনুপস্থিত বৈশিষ্ট্য নেই, মডেলটি আমাদের অনুপস্থিত মানটির জন্য একটি অনুমান প্রদান করে যদি এটি ডাউনস্ট্রিম মডেল পরিবেশনের সময় ঘটে থাকে।
এখানে আমরা এই মডেল নিয়ন্ত্রিত পূর্বাভাস CTR এর প্লটে বিভক্ত dollar_rating । লক্ষ্য করুন যে আমাদের প্রয়োজনীয় সমস্ত সীমাবদ্ধতা প্রতিটি স্লাইসে পূরণ করা হয়েছে।
আউটপুট ক্রমাঙ্কন
আমরা এখন পর্যন্ত প্রশিক্ষিত সমস্ত TFL মডেলের জন্য, জালি স্তর (মডেল গ্রাফে "ল্যাটিস" হিসাবে নির্দেশিত) সরাসরি মডেলের ভবিষ্যদ্বাণী প্রকাশ করে। কখনও কখনও আমরা নিশ্চিত নই যে মডেল আউটপুট নির্গত করার জন্য জালির আউটপুট পুনরায় স্কেল করা উচিত কিনা:
- বৈশিষ্ট্য \(log\) গন্য যখন লেবেল গন্য হয়।
- জালিটি খুব কম শীর্ষবিন্দু থাকার জন্য কনফিগার করা হয়েছে তবে লেবেল বিতরণ তুলনামূলকভাবে জটিল।
এই ক্ষেত্রে আমরা মডেলের নমনীয়তা বাড়ানোর জন্য জালি আউটপুট এবং মডেল আউটপুটের মধ্যে আরেকটি ক্যালিব্রেটর যোগ করতে পারি। এখানে আমাদের তৈরি করা মডেলটিতে 5টি কীপয়েন্ট সহ একটি ক্যালিব্রেটর স্তর যুক্ত করা যাক। ফাংশনটি মসৃণ রাখতে আমরা আউটপুট ক্যালিব্রেটরের জন্য একটি রেগুলারাইজার যোগ করি।
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
চূড়ান্ত পরীক্ষার মেট্রিক এবং প্লটগুলি দেখায় যে কীভাবে সাধারণ জ্ঞানের সীমাবদ্ধতা ব্যবহার করে মডেলটিকে অপ্রত্যাশিত আচরণ এড়াতে এবং সম্পূর্ণ ইনপুট স্থানকে আরও ভালভাবে এক্সট্রাপোলেট করতে সহায়তা করতে পারে।