
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | | |
genel bakış
Yorum metni kullanarak pozitif veya negatif olarak bu dizüstü sınıflandırır film değerlendirmeleri. Bu ikili sınıflandırma, makine öğrenme sorununun önemli ve yaygın olarak uygulanabilir türden bir örnektir.
Verilen girdiden bir grafik oluşturarak bu defterde grafik düzenleme kullanımını göstereceğiz. Girdi açık bir grafik içermediğinde, Sinirsel Yapılandırılmış Öğrenme (NSL) çerçevesini kullanarak grafikle düzenlenmiş bir model oluşturmak için genel tarif aşağıdaki gibidir:
- Girişteki her metin örneği için yerleştirmeler oluşturun. Bu gibi ön-eğitimli modeller kullanılarak yapılabilir word2vec , Döner , Bert vs.
- 'L2' mesafesi, 'kosinüs' mesafesi vb. gibi bir benzerlik metriğini kullanarak bu yerleştirmelere dayalı bir grafik oluşturun. Grafikteki düğümler örneklere karşılık gelir ve grafikteki kenarlar örnek çiftleri arasındaki benzerliğe karşılık gelir.
- Yukarıdaki sentezlenmiş grafik ve örnek özelliklerden eğitim verileri oluşturun. Ortaya çıkan eğitim verileri, orijinal düğüm özelliklerine ek olarak komşu özellikleri içerecektir.
- Keras sıralı, işlevsel veya alt sınıf API'sini kullanarak temel model olarak bir sinir ağı oluşturun.
- Yeni bir grafik Keras modeli oluşturmak için temel modeli NSL çerçevesi tarafından sağlanan GraphRegularization sarmalayıcı sınıfıyla sarın. Bu yeni model, eğitim hedefinde düzenlileştirme terimi olarak bir grafik düzenleme kaybı içerecektir.
- Grafik Keras modelini eğitin ve değerlendirin.
Gereksinimler
- Nöral Yapılandırılmış Öğrenme paketini kurun.
- Tensorflow-hub'ı kurun.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Bağımlılıklar ve içe aktarmalar
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
IMDB veri seti
IMDB veri kümesi 50.000 film incelemeleri metnini içerir Internet Movie Database . Bunlar, eğitim için 25.000 inceleme ve test için 25.000 incelemeye bölünmüştür. Eğitim ve test setleri pozitif ve negatif değerlendirmeleri eşit sayıda içerirler, yani dengeli edilir.
Bu eğitimde, IMDB veri setinin önceden işlenmiş bir versiyonunu kullanacağız.
Önceden işlenmiş IMDB veri kümesini indirin
IMDB veri seti, TensorFlow ile birlikte gelir. İncelemelerin (kelime dizileri) tamsayı dizilerine dönüştürüleceği şekilde önceden işlenmiştir, burada her tam sayı bir sözlükteki belirli bir sözcüğü temsil eder.
Aşağıdaki kod IMDB veri kümesini indirir (veya önceden indirilmişse önbelleğe alınmış bir kopya kullanır):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
Argüman num_words=10000 eğitim verilerinde üst 10,000 en sık geçen kelimeleri tutar. Nadir kelimeler, kelime dağarcığının boyutunu yönetilebilir tutmak için atılır.
Verileri keşfedin
Verilerin biçimini anlamak için bir dakikanızı ayıralım. Veri kümesi önceden işlenmiş olarak gelir: her örnek, film incelemesinin sözcüklerini temsil eden bir tamsayı dizisidir. Her etiket, 0 veya 1 tamsayı değeridir; burada 0, olumsuz bir incelemedir ve 1, olumlu bir incelemedir.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
İncelemelerin metni tam sayılara dönüştürülmüştür, burada her tam sayı sözlükteki belirli bir kelimeyi temsil eder. İlk inceleme şöyle görünüyor:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Film incelemeleri farklı uzunluklarda olabilir. Aşağıdaki kod, birinci ve ikinci incelemelerdeki kelime sayısını gösterir. Bir sinir ağına girişlerin aynı uzunlukta olması gerektiğinden, bunu daha sonra çözmemiz gerekecek.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Tamsayıları tekrar kelimelere dönüştürün
Tam sayıların karşılık gelen metne nasıl dönüştürüleceğini bilmek faydalı olabilir. Burada, tamsayıyı dize eşlemeye içeren bir sözlük nesnesini sorgulamak için bir yardımcı işlev oluşturacağız:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Şimdi kullanabilirsiniz decode_review ilk inceleme için metni görüntülemek için işlevi:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
grafik yapımı
Grafik oluşturma, metin örnekleri için yerleştirmeler oluşturmayı ve ardından yerleştirmeleri karşılaştırmak için bir benzerlik işlevi kullanmayı içerir.
Daha fazla ilerlemeden önce, bu öğretici tarafından oluşturulan yapay nesneleri depolamak için bir dizin oluşturuyoruz.
mkdir -p /tmp/imdb
Örnek yerleştirmeler oluşturun
Biz de katıştırmalarını oluşturmak için pretrained Döner katıştırmalarını kullanacak tf.train.Example girişinde her numune için formatında. Biz sonuçlanan katıştırmalarını saklayacak TFRecord Her numunenin ID temsil eden bir ek özelliği ile birlikte biçimi. Bu önemlidir ve örnek yerleştirmeleri daha sonra grafikte karşılık gelen düğümlerle eşleştirmemize izin verir.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Bir grafik oluşturun
Şimdi örnek yerleştirmelere sahip olduğumuza göre, bunları bir benzerlik grafiği oluşturmak için kullanacağız, yani, bu grafikteki düğümler örneklere karşılık gelecek ve bu grafikteki kenarlar, düğüm çiftleri arasındaki benzerliğe karşılık gelecek.
Nöral Yapılandırılmış Öğrenme, örnek yerleştirmelere dayalı bir grafik oluşturmak için bir grafik oluşturma kitaplığı sağlar. Bu kullanan kosinüs benzerlik aralarında katıştırmalarını ve yapı kenarları karşılaştırma benzerlik ölçüsü olarak. Ayrıca, son grafikten farklı kenarları atmak için kullanılabilecek bir benzerlik eşiği belirlememize de olanak tanır. Bu örnekte, benzerlik eşiği olarak 0.99 ve rastgele tohum olarak 12345 kullanıldığında, 429.415 çift yönlü kenara sahip bir grafik elde ederiz. Burada için grafik üreticisinin desteğini kullandığınız yerellik duyarlı karma grafik binayı hızlandırmak için (LSH). Grafik üreticisinin LSH destek kullanılarak ilgili ayrıntılar için, bkz build_graph_from_config API belgelerine.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Her iki yönlü kenar, çıktı TSV dosyasında iki yönlendirilmiş kenarla temsil edilir, böylece dosya 429.415 * 2 = 858.830 toplam satır içerir:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Örnek özellikler
Biz kullanarak sorunu için örnek özellikler oluşturmak tf.train.Example biçimini ve onları inat TFRecord formatında. Her numune aşağıdaki üç özelliği içerecektir:
- id: numunenin düğüm İD.
- kelimeler: kelime kimliklerini içeren int64 listesi.
- Etiket: yorum hedef sınıfını tanımlayan int64 bir tekil.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Grafik komşularıyla eğitim verilerini artırın
Örnek özelliklere ve sentezlenmiş grafiğe sahip olduğumuz için, Nöral Yapılandırılmış Öğrenme için artırılmış eğitim verilerini üretebiliriz. NSL çerçevesi, grafiğin düzenlenmesi için son eğitim verilerini üretmek için grafiği ve örnek özellikleri birleştirmek için bir kitaplık sağlar. Ortaya çıkan eğitim verileri, orijinal örnek özelliklerin yanı sıra bunlara karşılık gelen komşularının özelliklerini içerecektir.
Bu öğreticide, yönlendirilmemiş kenarları ele alıyoruz ve grafik komşularıyla eğitim verilerini artırmak için örnek başına maksimum 3 komşu kullanıyoruz.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Temel model
Artık grafik düzenleme olmadan bir temel model oluşturmaya hazırız. Bu modeli oluşturmak için ya grafiği oluştururken kullanılan gömmeleri kullanabiliriz ya da sınıflandırma görevi ile birlikte yeni gömmeleri öğrenebiliriz. Bu defterin amacı için ikincisini yapacağız.
genel değişkenler
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
hiperparametreler
Biz bir örneğini kullanacak HParams eğitim ve değerlendirme için kullanılan çeşitli hyperparameters ve sabitleri içermek. Aşağıda her birini kısaca açıklıyoruz:
num_classes: - Pozitif ve negatif 2 sınıfları vardır.
max_seq_length: Bu, bu örnekte her bir film gözden düşünülen kelimelerin sayısıdır.
vocab_size: Bu, bu örneğin düşünülen kelime boyutudur.
DISTANCE_TYPE: Bu komşularıyla numuneyi düzene kullanılan metrik mesafedir.
graph_regularization_multiplier Bu kontroller, genel kayıp fonksiyonu olarak grafiği düzenlilestirme terimi nispi ağırlık.
num_neighbors: Grafik duzenleme için kullanılan komşu sayısı. Bu değer için eşit veya daha az olması gerekir
max_nbrsyürütmesini yukarıda kullanılan değişkennsl.tools.pack_nbrs.num_fc_units: sinir ağının tam olarak bağlı katmanı birim sayısı.
train_epochs: Eğitim evrelerin sayı.
batch_size: Eğitim ve değerlendirme için kullanılan Parti büyüklüğü.
eval_steps: değerlendirmesini deeming önce sürecine toplu sayısı tamamlandı. Olarak ayarlanırsa
None, deney setinde tüm örnekler değerlendirilir.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Verileri hazırlayın
İncelemeler -tamsayı dizileri- sinir ağına beslenmeden önce tensörlere dönüştürülmelidir. Bu dönüşüm birkaç yolla yapılabilir:
Vektörleri içine diziler dönüştürme
0s ve1bir sıcak kodlama benzer kelime meydana gelmesini gösteren s. Örnek olarak, dizilimin[3, 5]bir olacak10000endeksi dışında tüm sıfır boyutlu vektör3ve5olanlardır. Sonra, bu bizim ilk katman yapmak ağa-aDensetabaka-o nokta vektör verilerini kayan işleyebilir. Bu yaklaşım, bir gerektiren olsa da, yoğun belleknum_words * num_reviewsboyutu matrisi.Hepsi aynı uzunlukta Alternatif olarak, biz ped diziler, sonra şekil bir tamsayı tensörünü oluşturabilir
max_length * num_reviews. Ağımızdaki ilk katman olarak bu şekli işleyebilen bir gömme katmanı kullanabiliriz.
Bu derste, ikinci yaklaşımı kullanacağız.
Film incelemeleri aynı uzunlukta olması gerektiği için, biz kullanacağız pad_sequence uzunlukları standart hale getirmek aşağıda tanımlanan işlevi.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Modeli oluşturun
Katmanları istifleyerek bir sinir ağı oluşturulur; bunun için iki ana mimari karar gerekir:
- Modelde kaç katman kullanılacak?
- Her katman için kaç gizli birimler kullanılır?
Bu örnekte, girdi verileri bir dizi kelime indeksinden oluşur. Tahmin edilecek etiketler ya 0 ya da 1'dir.
Bu eğitimde temel modelimiz olarak çift yönlü bir LSTM kullanacağız.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Sınıflandırıcıyı oluşturmak için katmanlar etkili bir şekilde sırayla istiflenir:
- Birinci tabaka bir bir
Inputtamsayıdır kodlanmış kelime alır tabaka. - Bir sonraki katman bir olduğunu
Embeddingher kelime-endeksi için gömme vektör yukarı tamsayı kodlanmış kelime ve görünüyor alır tabakası. Bu vektörler model trenler olarak öğrenilir. Vektörler, çıktı dizisine bir boyut ekler. Elde edilen boyutları:(batch, sequence, embedding). - Ardından, çift yönlü bir LSTM katmanı, her örnek için sabit uzunlukta bir çıktı vektörü döndürür.
- Bu sabit uzunluklu çıkış vektörü, bir tam-bağlı (boyunca yöneltilen
Dense64 gizli birimleri ile) tabaka. - Son katman, tek bir çıkış düğümü ile yoğun bir şekilde bağlantılıdır. Kullanma
sigmoidaktivasyon fonksiyonu, bu değer, bir olasılık, ya da güven seviyesini temsil eden, 0 ile 1 arasında bulunan bir halka açık.
Gizli birimler
Yukarıdaki model, giriş ve çıkış ve hariç arasında, iki ara ya da "saklı" tabakası vardır Embedding tabakası. Çıktıların sayısı (birimler, düğümler veya nöronlar), katmanın temsili alanının boyutudur. Başka bir deyişle, dahili bir temsili öğrenirken ağın izin verdiği özgürlük miktarı.
Bir modelin daha fazla gizli birimi (daha yüksek boyutlu bir temsil alanı) ve/veya daha fazla katmanı varsa, ağ daha karmaşık temsilleri öğrenebilir. Bununla birlikte, ağı hesaplama açısından daha pahalı hale getirir ve istenmeyen kalıpların – eğitim verilerinde performansı artıran ancak test verilerinde olmayan kalıpların – öğrenilmesine yol açabilir. Bu aşırı oturma denir.
Kayıp fonksiyonu ve optimize edici
Bir model, eğitim için bir kayıp işlevine ve bir optimize ediciye ihtiyaç duyar. Bu ikili bir sınıflandırma sorunu ve bir olasılık çıkışları modeli (bir sigmoid aktivasyonu ile bir tek ünite katmanı) olduğu için, kullanacağız binary_crossentropy kayıp fonksiyonunu.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Bir doğrulama seti oluşturun
Eğitim sırasında, modelin daha önce görmediği veriler üzerindeki doğruluğunu kontrol etmek istiyoruz. Orijinal eğitim verilerinin bir kısmını ayrı ayarlayarak bir doğrulama kümesi oluşturun. (Neden şimdi test setini kullanmıyorsunuz? Amacımız, modelimizi yalnızca eğitim verilerini kullanarak geliştirmek ve ayarlamak, ardından doğruluğumuzu değerlendirmek için test verilerini yalnızca bir kez kullanmaktır).
Bu öğreticide, ilk eğitim örneklerinin yaklaşık %10'unu (25000'in %10'u) eğitim için etiketlenmiş veriler ve geri kalanını doğrulama verileri olarak alıyoruz. İlk eğitim/test ayrımı 50/50 (her biri 25000 örnek) olduğundan, şu anda sahip olduğumuz etkin eğitim/doğrulama/test ayrımı 5/45/50'dir.
'train_dataset' zaten toplu ve karıştırılmış olduğunu unutmayın.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Modeli eğit
Modeli mini partiler halinde eğitin. Eğitim sırasında, doğrulama setinde modelin kaybını ve doğruluğunu izleyin:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
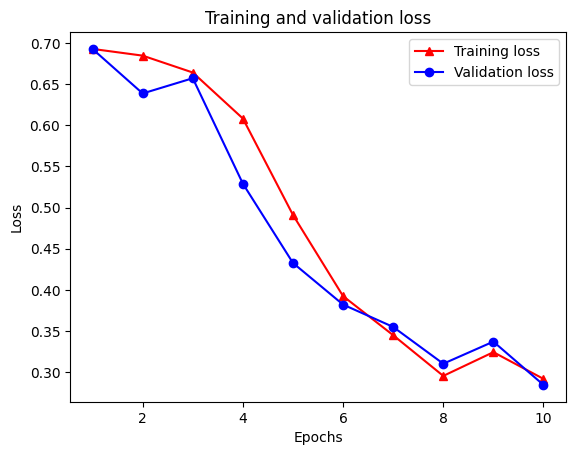
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Modeli değerlendirin
Şimdi, modelin nasıl performans gösterdiğini görelim. İki değer döndürülür. Kayıp (hatamızı temsil eden bir sayı, daha düşük değerler daha iyidir) ve doğruluk.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Zaman içinde doğruluk/kayıp grafiği oluşturun
model.fit() bir döner History eğitimi sırasında olanlardan sonra bir sözlük içerir nesnesi:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Dört giriş vardır: eğitim ve doğrulama sırasında izlenen her metrik için bir tane. Bunları, karşılaştırma için eğitim ve doğrulama kaybının yanı sıra eğitim ve doğrulama doğruluğunu çizmek için kullanabiliriz:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
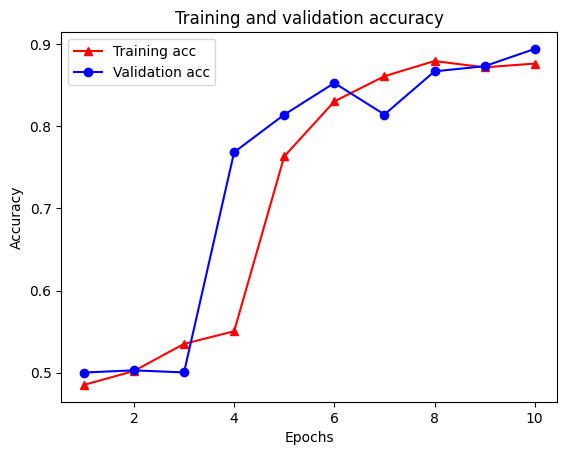
Eğitim kaybı her döneme ve her çağın ile eğitim doğruluk artar azalır dikkat edin. Gradyan iniş optimizasyonu kullanılırken bu beklenir; her yinelemede istenen miktarı en aza indirmelidir.
Grafik düzenleme
Artık yukarıda oluşturduğumuz temel modeli kullanarak grafik düzenlemeyi denemeye hazırız. Biz kullanır GraphRegularization grafik düzenlenmesine dahil etmek için bir baz (iki LSTM) modeli kaydırmak için sinir Yapısal İçi çerçevesi tarafından sağlanan sarıcı sınıfı. Grafikle düzenlenmiş modeli eğitmek ve değerlendirmek için kalan adımlar, temel modelinkine benzer.
Grafiğe göre düzenlenmiş model oluşturun
Grafik düzenlemenin artan faydasını değerlendirmek için yeni bir temel model örneği oluşturacağız. Bunun nedeni model zaten birkaç tekrarlamalar için eğitilmiş ve grafik-regularized model oluşturmak için bu eğitimli modeli yeniden kullanmak için adil bir karşılaştırma olmayacak model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Modeli eğit
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
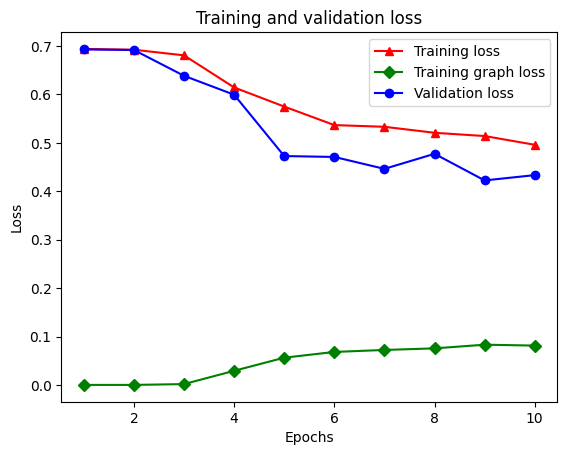
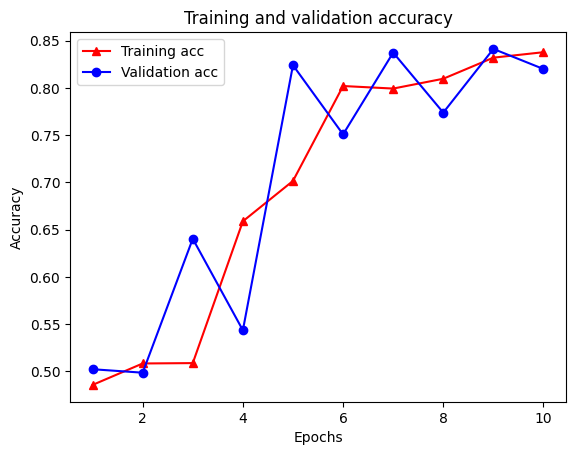
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Modeli değerlendirin
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Zaman içinde doğruluk/kayıp grafiği oluşturun
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Sözlükte toplam beş giriş vardır: eğitim kaybı, eğitim doğruluğu, eğitim grafiği kaybı, doğrulama kaybı ve doğrulama doğruluğu. Karşılaştırma için hepsini bir araya getirebiliriz. Grafik kaybının yalnızca eğitim sırasında hesaplandığını unutmayın.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Yarı denetimli öğrenmenin gücü
Yarı denetimli öğrenme ve daha spesifik olarak, bu öğretici bağlamında grafik düzenleme, eğitim verilerinin miktarı az olduğunda gerçekten güçlü olabilir. Eğitim verilerinin eksikliği, geleneksel denetimli öğrenmede mümkün olmayan eğitim örnekleri arasındaki benzerlikten yararlanılarak telafi edilir.
Bu eğitim, doğrulama ve test örneklerini içerir numunelerin toplam sayısına örnekleri eğitim oranı olarak denetim oranını tanımlar. Bu not defterinde, hem temel modeli hem de grafikle düzenlenmiş modeli eğitmek için 0,05'lik bir denetim oranı kullandık (yani, etiketlenen verilerin %5'i). Denetim oranının model doğruluğu üzerindeki etkisini aşağıdaki hücrede gösteriyoruz.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
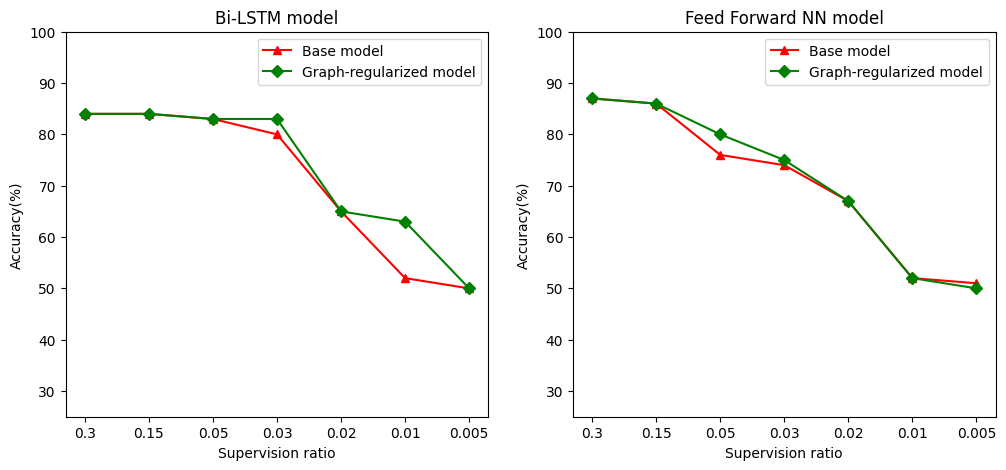
Denetim oranı azaldıkça model doğruluğunun da düştüğü görülmektedir. Bu, kullanılan model mimarisinden bağımsız olarak hem temel model hem de grafikle düzenlenmiş model için geçerlidir. Ancak, grafikle düzenlenmiş modelin her iki mimari için de temel modelden daha iyi performans gösterdiğine dikkat edin. Denetim oranı 0.01 Özellikle, Bi-LSTM model için, grafik-regularized modelinin hassasiyeti% 20 daha yüksek baz model daha ~ olmalıdır. Bunun temel nedeni, eğitim örneklerine ek olarak eğitim örnekleri arasındaki yapısal benzerliğin kullanıldığı grafik-düzenli model için yarı denetimli öğrenmedir.
Çözüm
Girdi açık bir grafik içermese bile, Sinirsel Yapılandırılmış Öğrenme (NSL) çerçevesini kullanarak grafik düzenleme kullanımını gösterdik. İnceleme yerleştirmelerine dayalı bir benzerlik grafiği sentezlediğimiz IMDB film incelemelerinin duygu sınıflandırması görevini düşündük. Kullanıcıları, hiperparametreleri, denetim miktarını değiştirerek ve farklı model mimarileri kullanarak daha fazla deneme yapmaya teşvik ediyoruz.