
Học theo cấu trúc thần kinh: Đào tạo bằng tín hiệu có cấu trúc
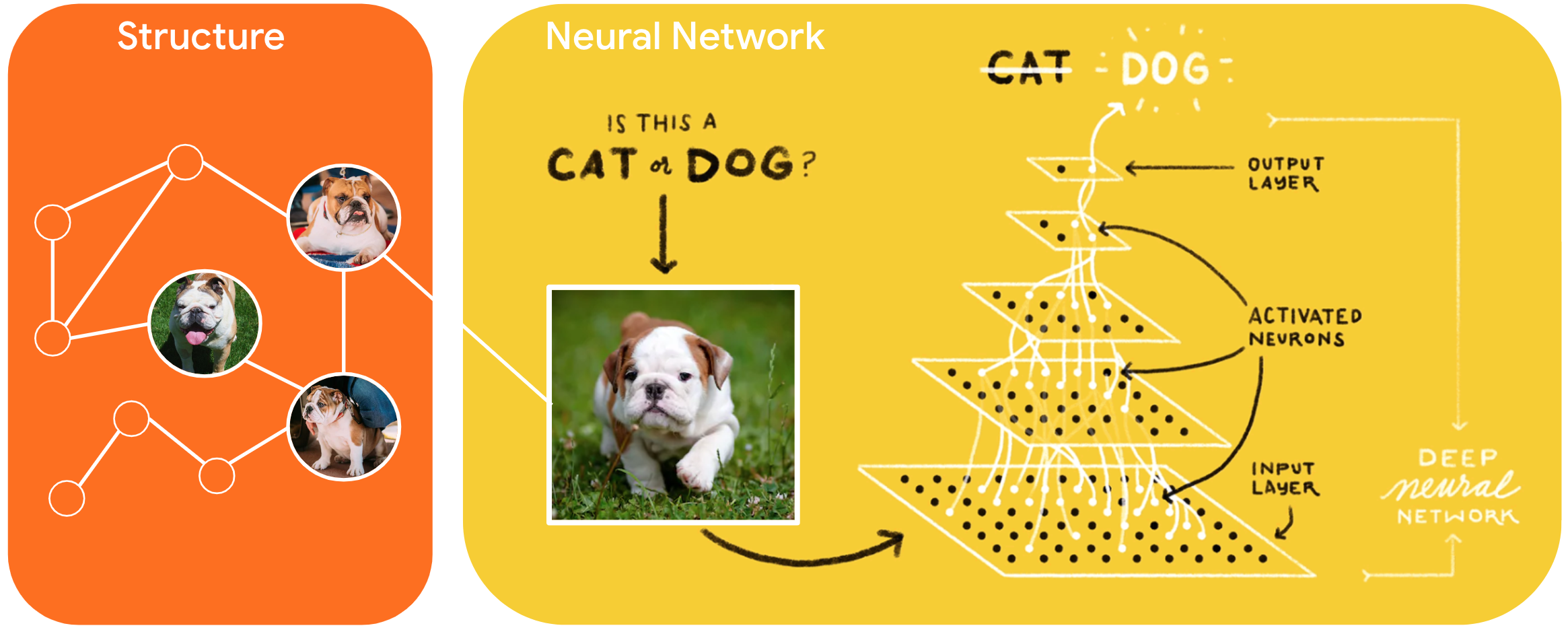
Học có cấu trúc thần kinh (NSL) là một mô hình học tập mới để đào tạo mạng thần kinh bằng cách tận dụng các tín hiệu có cấu trúc ngoài các đầu vào tính năng. Cấu trúc có thể rõ ràng như được biểu thị bằng biểu đồ hoặc ngầm hiểu như được gây ra bởi sự nhiễu loạn của đối thủ.
Các tín hiệu có cấu trúc thường được sử dụng để biểu diễn các mối quan hệ hoặc sự giống nhau giữa các mẫu có thể được gắn nhãn hoặc không được gắn nhãn. Do đó, tận dụng các tín hiệu này trong quá trình huấn luyện mạng nơ-ron khai thác cả dữ liệu được gắn nhãn và không được gắn nhãn, điều này có thể cải thiện độ chính xác của mô hình, đặc biệt khi lượng dữ liệu được gắn nhãn tương đối nhỏ . Ngoài ra, các mô hình được đào tạo với các mẫu được tạo ra bằng cách thêm nhiễu loạn đối nghịch đã được chứng minh là mạnh mẽ chống lại các cuộc tấn công độc hại , được thiết kế để làm sai dự đoán hoặc phân loại của mô hình.
NSL khái quát thành Học đồ thị thần kinh cũng như Học theo đối phương. Khung NSL trong TensorFlow cung cấp các API và công cụ dễ sử dụng sau đây cho các nhà phát triển để đào tạo các mô hình với các tín hiệu có cấu trúc:
- API Keras để cho phép đào tạo với đồ thị (cấu trúc rõ ràng) và nhiễu đối phương (cấu trúc ngầm định).
- Các hoạt động và chức năng của TF để cho phép đào tạo với cấu trúc khi sử dụng các API TensorFlow cấp thấp hơn
- Các công cụ để xây dựng đồ thị và xây dựng đầu vào đồ thị để đào tạo
Việc kết hợp các tín hiệu có cấu trúc chỉ được thực hiện trong quá trình đào tạo. Vì vậy, hiệu suất của quy trình cung cấp / suy luận vẫn không thay đổi. Bạn có thể tìm thấy thêm thông tin về học có cấu trúc thần kinh trong phần mô tả khung của chúng tôi. Để bắt đầu, vui lòng xem hướng dẫn cài đặt của chúng tôi và để được giới thiệu thực tế về NSL, hãy xem hướng dẫn của chúng tôi.
import tensorflow as tf import neural_structured_learning as nsl # Prepare data. (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # Create a base model -- sequential, functional, or subclass. model = tf.keras.Sequential([ tf.keras.Input((28, 28), name='feature'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) # Wrap the model with adversarial regularization. adv_config = nsl.configs.make_adv_reg_config(multiplier=0.2, adv_step_size=0.05) adv_model = nsl.keras.AdversarialRegularization(model, adv_config=adv_config) # Compile, train, and evaluate. adv_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) adv_model.fit({'feature': x_train, 'label': y_train}, batch_size=32, epochs=5) adv_model.evaluate({'feature': x_test, 'label': y_test})
