
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Liniowy model efektów mieszanych jest prostym podejściem do modelowania ustrukturyzowanych relacji liniowych (Harville, 1997; Laird i Ware, 1982). Każdy punkt danych składa się z danych wejściowych różnego typu — podzielonych na grupy — oraz danych wyjściowych o wartościach rzeczywistych. Model liniowy efekty mieszane jest hierarchiczny model: dzieli siłę statystyczną pomiędzy grupami w celu poprawy wniosków o każdego indywidualnego punktu danych.
W tym samouczku zademonstrujemy liniowe modele efektów mieszanych z rzeczywistym przykładem w TensorFlow Probability. Użyjemy JointDistributionCoroutine i Markov Chain Monte Carlo ( tfp.mcmc ) modułów.
Zależności i wymagania wstępne
Importuj i konfiguruj
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import requests
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
dtype = tf.float64
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
plt.style.use('ggplot')
Zrób rzeczy szybko!
Zanim zagłębimy się w temat, upewnijmy się, że w tej wersji demonstracyjnej używamy procesora graficznego.
W tym celu wybierz „Runtime” -> „Zmień typ środowiska uruchomieniowego” -> „Hardware Accelerator” -> „GPU”.
Poniższy fragment kodu zweryfikuje, czy mamy dostęp do GPU.
if tf.test.gpu_device_name() != '/device:GPU:0':
print('WARNING: GPU device not found.')
else:
print('SUCCESS: Found GPU: {}'.format(tf.test.gpu_device_name()))
SUCCESS: Found GPU: /device:GPU:0
Dane
Używamy InstEval zestaw danych z popularnego lme4 opakowaniu w R (Bates i in., 2015). Jest to zbiór danych o kursach i ich ocenach. Każdy kurs zawiera metadane, takie jak students , instructors i departments , a zmienna odpowiedź zainteresowania jest ocena ocena.
def load_insteval():
"""Loads the InstEval data set.
It contains 73,421 university lecture evaluations by students at ETH
Zurich with a total of 2,972 students, 2,160 professors and
lecturers, and several student, lecture, and lecturer attributes.
Implementation is built from the `observations` Python package.
Returns:
Tuple of np.ndarray `x_train` with 73,421 rows and 7 columns and
dictionary `metadata` of column headers (feature names).
"""
url = ('https://raw.github.com/vincentarelbundock/Rdatasets/master/csv/'
'lme4/InstEval.csv')
with requests.Session() as s:
download = s.get(url)
f = download.content.decode().splitlines()
iterator = csv.reader(f)
columns = next(iterator)[1:]
x_train = np.array([row[1:] for row in iterator], dtype=np.int)
metadata = {'columns': columns}
return x_train, metadata
Ładujemy i wstępnie przetwarzamy zbiór danych. Posiadamy 20% danych, dzięki czemu możemy ocenić nasz dopasowany model na niewidocznych punktach danych. Poniżej wizualizujemy kilka pierwszych rzędów.
data, metadata = load_insteval()
data = pd.DataFrame(data, columns=metadata['columns'])
data = data.rename(columns={'s': 'students',
'd': 'instructors',
'dept': 'departments',
'y': 'ratings'})
data['students'] -= 1 # start index by 0
# Remap categories to start from 0 and end at max(category).
data['instructors'] = data['instructors'].astype('category').cat.codes
data['departments'] = data['departments'].astype('category').cat.codes
train = data.sample(frac=0.8)
test = data.drop(train.index)
train.head()
Założyliśmy zestawu danych w kategoriach features Słownik wejść i labels wyjście odpowiadające ocenie. Każda cecha jest zakodowana jako liczba całkowita, a każda etykieta (ocena oceny) jest zakodowana jako liczba zmiennoprzecinkowa.
get_value = lambda dataframe, key, dtype: dataframe[key].values.astype(dtype)
features_train = {
k: get_value(train, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_train = get_value(train, key='ratings', dtype=np.float32)
features_test = {k: get_value(test, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_test = get_value(test, key='ratings', dtype=np.float32)
num_students = max(features_train['students']) + 1
num_instructors = max(features_train['instructors']) + 1
num_departments = max(features_train['departments']) + 1
num_observations = train.shape[0]
print("Number of students:", num_students)
print("Number of instructors:", num_instructors)
print("Number of departments:", num_departments)
print("Number of observations:", num_observations)
Number of students: 2972 Number of instructors: 1128 Number of departments: 14 Number of observations: 58737
Model
Typowy model liniowy zakłada niezależność, gdzie dowolna para punktów danych ma stałą zależność liniową. W InstEval zbioru danych, obserwacje powstają w grupach, z których każda może mieć różne stoki i przecięcia. Liniowe modele efektów mieszanych, znane również jako hierarchiczne modele liniowe lub wielopoziomowe modele liniowe, oddają to zjawisko (Gelman & Hill, 2006).
Przykładami tego zjawiska są:
- Studentów. Obserwacje studenta nie są niezależne: niektórzy studenci mogą systematycznie wystawiać niskie (lub wysokie) oceny z wykładów.
- Instruktorów. Obserwacje instruktora nie są niezależne: oczekujemy, że dobrzy nauczyciele będą ogólnie mieć dobre oceny, a źli nauczyciele będą mieć generalnie złe oceny.
- Działów. Obserwacje z departamentu nie są niezależne: niektóre departamenty mogą generalnie stosować suchy materiał lub bardziej rygorystyczną klasyfikację, a tym samym być oceniane niżej niż inne.
Do tego Przypomnijmy, że dla zbioru danych uchwycić \(N\times D\) rysy \(\mathbf{X}\) i \(N\) etykiety \(\mathbf{y}\), liniowy model regresji posits
\[ \begin{equation*} \mathbf{y} = \mathbf{X}\beta + \alpha + \epsilon, \end{equation*} \]
gdzie znajduje się stok wektor \(\beta\in\mathbb{R}^D\), przechwytują \(\alpha\in\mathbb{R}\)i losowy szum \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). Mówimy, że \(\beta\) i \(\alpha\) są „trwałe efekty”: są efekty utrzymywana na stałym poziomie w całej populacji punktów danych \((x, y)\). Równoważna kompozycja równania jako prawdopodobieństwo, \(\mathbf{y} \sim \text{Normal}(\mathbf{X}\beta + \alpha, \mathbf{I})\). To prawdopodobieństwo jest zmaksymalizowane podczas wnioskowania, aby wybrać oszacowań punktowych \(\beta\) i \(\alpha\) które pasują do danych.
Liniowy model efektów mieszanych rozszerza regresję liniową jako
\[ \begin{align*} \eta &\sim \text{Normal}(\mathbf{0}, \sigma^2 \mathbf{I}), \\ \mathbf{y} &= \mathbf{X}\beta + \mathbf{Z}\eta + \alpha + \epsilon. \end{align*} \]
gdzie nadal istnieje nachylenie wektor \(\beta\in\mathbb{R}^P\), przechwytują \(\alpha\in\mathbb{R}\)i losowy szum \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). Ponadto, nie jest to termin \(\mathbf{Z}\eta\)gdzie \(\mathbf{Z}\) to cechy matrycy i \(\eta\in\mathbb{R}^Q\) jest wektor losowej tras; \(\eta\) zwykle rozmieszczone z parametrem składnika odchylenie \(\sigma^2\). \(\mathbf{Z}\) jest utworzona przez rozdzielenie oryginalnego \(N\times D\) wyposażony macierzy pod względem nowego \(N\times P\) matrycy \(\mathbf{X}\) i \(N\times Q\) matrycy \(\mathbf{Z}\), gdzie \(P + Q=D\): partycja pozwala nam model cechy oddzielnie przy użyciu Utrwalone efekty \(\beta\) a zmienna utajony \(\eta\) odpowiednio.
Mówimy zmienne ukryte \(\eta\) są „przypadkowe efekty”: są efekty, które zmieniają się w całej populacji (choć mogą być stała w podgrupach). W szczególności, ponieważ efektów losowych \(\eta\) mieć średnią 0, średnia tabliczce znamionowej jest przechwytywane przez \(\mathbf{X}\beta + \alpha\). Efektów losowych elementów \(\mathbf{Z}\eta\) przechwytuje zmiany w danych „Instruktor nr 54 jest przyznana 1,4 punktu wyższy niż średni” Na przykład,
W tym samouczku proponujemy następujące efekty:
- Trwałe efekty:
service.servicejest binarną zmienną towarzyszącą odpowiadające czy kurs należy do głównego działu instruktora. Bez względu na to, ile danych dodatkowy zbieramy, może to potrwać tylko na wartościach \(0\) i \(1\). - Losowe efekty:
students,instructorsidepartments. Biorąc pod uwagę więcej obserwacji z populacji ocen kursów, możemy przyglądać się nowym studentom, nauczycielom lub wydziałom.
W składni pakietu lme4 R (Bates i in., 2015) model można podsumować jako
ratings ~ service + (1|students) + (1|instructors) + (1|departments) + 1
gdzie x oznacza stałą efekt (1|x) oznacza losowego dla x i 1 oznacza określenie przechwytującego.
Poniżej wdrażamy ten model jako JointDistribution. Aby mieć lepsze wsparcie dla śledzenia parametrów (np chcemy śledzić wszystkie tf.Variable w model.trainable_variables ), wdrażamy model szablon jako tf.Module .
class LinearMixedEffectModel(tf.Module):
def __init__(self):
# Set up fixed effects and other parameters.
# These are free parameters to be optimized in E-steps
self._intercept = tf.Variable(0., name="intercept") # alpha in eq
self._effect_service = tf.Variable(0., name="effect_service") # beta in eq
self._stddev_students = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_students") # sigma in eq
self._stddev_instructors = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_instructors") # sigma in eq
self._stddev_departments = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_departments") # sigma in eq
def __call__(self, features):
model = tfd.JointDistributionSequential([
# Set up random effects.
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_students),
scale_identity_multiplier=self._stddev_students),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_instructors),
scale_identity_multiplier=self._stddev_instructors),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_departments),
scale_identity_multiplier=self._stddev_departments),
# This is the likelihood for the observed.
lambda effect_departments, effect_instructors, effect_students: tfd.Independent(
tfd.Normal(
loc=(self._effect_service * features["service"] +
tf.gather(effect_students, features["students"], axis=-1) +
tf.gather(effect_instructors, features["instructors"], axis=-1) +
tf.gather(effect_departments, features["departments"], axis=-1) +
self._intercept),
scale=1.),
reinterpreted_batch_ndims=1)
])
# To enable tracking of the trainable variables via the created distribution,
# we attach a reference to `self`. Since all TFP objects sub-class
# `tf.Module`, this means that the following is possible:
# LinearMixedEffectModel()(features_train).trainable_variables
# ==> tuple of all tf.Variables created by LinearMixedEffectModel.
model._to_track = self
return model
lmm_jointdist = LinearMixedEffectModel()
# Conditioned on feature/predictors from the training data
lmm_train = lmm_jointdist(features_train)
lmm_train.trainable_variables
(<tf.Variable 'stddev_students:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_instructors:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_departments:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'effect_service:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'intercept:0' shape=() dtype=float32, numpy=0.0>)
Jako probabilistyczny program graficzny możemy również zwizualizować strukturę modelu pod kątem jego grafu obliczeniowego. Wykres ten koduje przepływ danych przez zmienne losowe w programie, uwydatniając ich relacje w postaci modelu graficznego (Jordan, 2003).
Jako narzędzie statystyczne, możemy spojrzeć na wykres, aby lepiej zobaczyć, na przykład, że intercept i effect_service są warunkowo zależne podane ratings ; może to być trudniejsze do zobaczenia w kodzie źródłowym, jeśli program jest napisany z klasami, odsyłaczami między modułami i/lub podprogramami. Jako narzędzie obliczeniowe, możemy również zauważyć zmienne ukryte płynąć do ratings zmiennej poprzez tf.gather ops. To może być wąskim gardłem w niektórych akceleratorów sprzętowych czy indeksowanie Tensor s jest drogie; wizualizacja wykresu sprawia, że jest to łatwo widoczne.
lmm_train.resolve_graph()
(('effect_students', ()),
('effect_instructors', ()),
('effect_departments', ()),
('x', ('effect_departments', 'effect_instructors', 'effect_students')))
Estymacja parametrów
Biorąc pod uwagę dane, celem wnioskowania jest, aby pasowały do modelu nachylenie trwałe efekty \(\beta\), przechwytują \(\alpha\), a parametr składnik wariancji \(\sigma^2\). Zasada największej wiarygodności formalizuje to zadanie jako
\[ \max_{\beta, \alpha, \sigma}~\log p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}; \beta, \alpha, \sigma) = \max_{\beta, \alpha, \sigma}~\log \int p(\eta; \sigma) ~p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}, \eta; \beta, \alpha)~d\eta. \]
W tym samouczku używamy algorytmu Monte Carlo EM, aby zmaksymalizować tę marginalną gęstość (Dempster i in., 1977; Wei i Tanner, 1990).¹ Wykonujemy Monte Carlo z łańcuchem Markowa, aby obliczyć oczekiwaną wiarogodność warunkową względem efekty losowe („E-step”) i wykonujemy zejście gradientowe, aby zmaksymalizować oczekiwanie w odniesieniu do parametrów („M-step”):
Dla kroku E ustawiliśmy hamiltonian Monte Carlo (HMC). Przyjmuje bieżący stan — efekty ucznia, instruktora i działu — i zwraca nowy stan. Nowy stan przypisujemy do zmiennych TensorFlow, które będą oznaczać stan łańcucha HMC.
W przypadku kroku M używamy próbki a posteriori z HMC do obliczenia bezstronnego oszacowania marginalnego prawdopodobieństwa aż do stałej. Następnie stosujemy jego gradient względem interesujących nas parametrów. Daje to bezstronny stochastyczny krok opadania na marginalnym prawdopodobieństwie. Wdrażamy go z optymalizatorem Adam TensorFlow i minimalizujemy negatyw marginesu.
target_log_prob_fn = lambda *x: lmm_train.log_prob(x + (labels_train,))
trainable_variables = lmm_train.trainable_variables
current_state = lmm_train.sample()[:-1]
# For debugging
target_log_prob_fn(*current_state)
<tf.Tensor: shape=(), dtype=float32, numpy=-528062.5>
# Set up E-step (MCMC).
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.015,
num_leapfrog_steps=3)
kernel_results = hmc.bootstrap_results(current_state)
@tf.function(autograph=False, jit_compile=True)
def one_e_step(current_state, kernel_results):
next_state, next_kernel_results = hmc.one_step(
current_state=current_state,
previous_kernel_results=kernel_results)
return next_state, next_kernel_results
optimizer = tf.optimizers.Adam(learning_rate=.01)
# Set up M-step (gradient descent).
@tf.function(autograph=False, jit_compile=True)
def one_m_step(current_state):
with tf.GradientTape() as tape:
loss = -target_log_prob_fn(*current_state)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss
Wykonujemy etap rozgrzewki, który uruchamia jeden łańcuch MCMC dla wielu iteracji, tak aby trening mógł zostać zainicjowany w ramach masy prawdopodobieństwa a posteriori. Następnie prowadzimy pętlę treningową. Wspólnie wykonuje kroki E i M oraz rejestruje wartości podczas treningu.
num_warmup_iters = 1000
num_iters = 1500
num_accepted = 0
effect_students_samples = np.zeros([num_iters, num_students])
effect_instructors_samples = np.zeros([num_iters, num_instructors])
effect_departments_samples = np.zeros([num_iters, num_departments])
loss_history = np.zeros([num_iters])
# Run warm-up stage.
for t in range(num_warmup_iters):
current_state, kernel_results = one_e_step(current_state, kernel_results)
num_accepted += kernel_results.is_accepted.numpy()
if t % 500 == 0 or t == num_warmup_iters - 1:
print("Warm-Up Iteration: {:>3} Acceptance Rate: {:.3f}".format(
t, num_accepted / (t + 1)))
num_accepted = 0 # reset acceptance rate counter
# Run training.
for t in range(num_iters):
# run 5 MCMC iterations before every joint EM update
for _ in range(5):
current_state, kernel_results = one_e_step(current_state, kernel_results)
loss = one_m_step(current_state)
effect_students_samples[t, :] = current_state[0].numpy()
effect_instructors_samples[t, :] = current_state[1].numpy()
effect_departments_samples[t, :] = current_state[2].numpy()
num_accepted += kernel_results.is_accepted.numpy()
loss_history[t] = loss.numpy()
if t % 500 == 0 or t == num_iters - 1:
print("Iteration: {:>4} Acceptance Rate: {:.3f} Loss: {:.3f}".format(
t, num_accepted / (t + 1), loss_history[t]))
Warm-Up Iteration: 0 Acceptance Rate: 1.000 Warm-Up Iteration: 500 Acceptance Rate: 0.754 Warm-Up Iteration: 999 Acceptance Rate: 0.707 Iteration: 0 Acceptance Rate: 1.000 Loss: 98220.266 Iteration: 500 Acceptance Rate: 0.703 Loss: 96003.969 Iteration: 1000 Acceptance Rate: 0.678 Loss: 95958.609 Iteration: 1499 Acceptance Rate: 0.685 Loss: 95921.891
Można również napisać rozgrzewkę dla pętli do tf.while_loop i etap szkolenia w tf.scan lub tf.while_loop nawet szybciej wnioskowania. Na przykład:
@tf.function(autograph=False, jit_compile=True)
def run_k_e_steps(k, current_state, kernel_results):
_, next_state, next_kernel_results = tf.while_loop(
cond=lambda i, state, pkr: i < k,
body=lambda i, state, pkr: (i+1, *one_e_step(state, pkr)),
loop_vars=(tf.constant(0), current_state, kernel_results)
)
return next_state, next_kernel_results
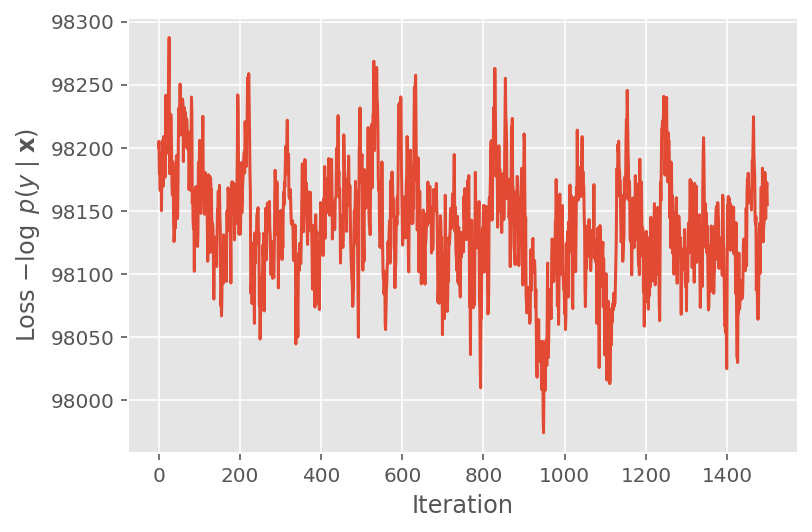
Powyżej nie uruchomiliśmy algorytmu, dopóki nie zostanie wykryty próg zbieżności. Aby sprawdzić, czy trening był sensowny, sprawdzamy, czy funkcja straty rzeczywiście ma tendencję do zbiegania się w iteracjach treningu.
plt.plot(loss_history)
plt.ylabel(r'Loss $-\log$ $p(y\mid\mathbf{x})$')
plt.xlabel('Iteration')
plt.show()
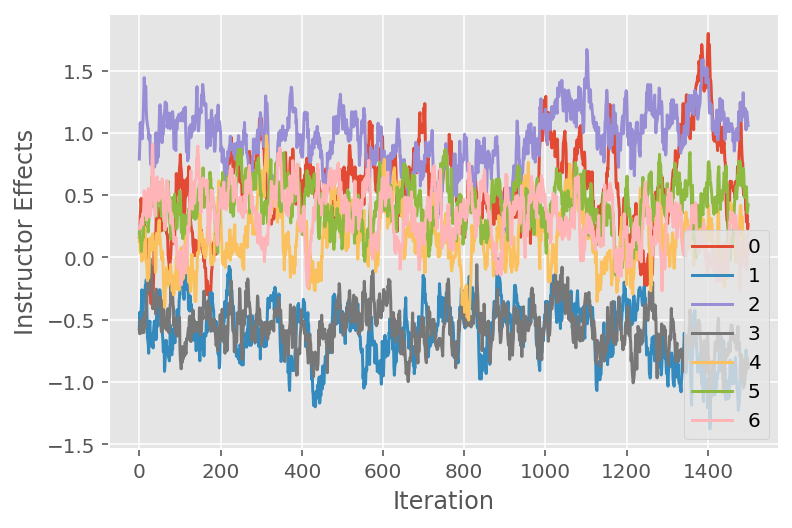
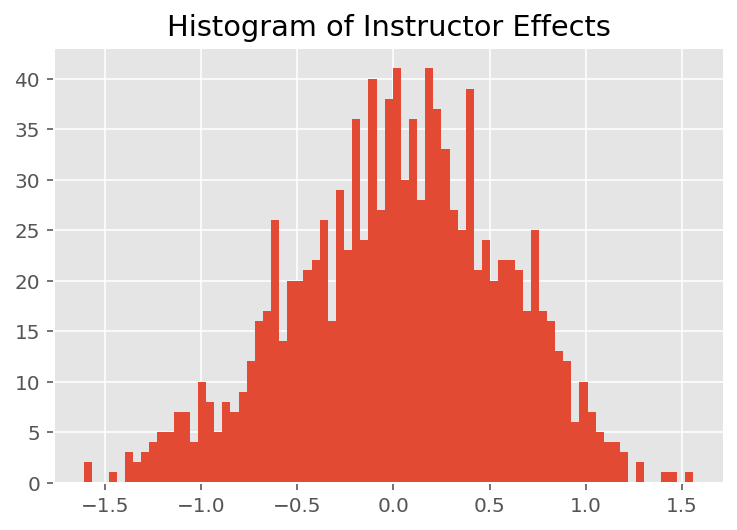
Używamy również wykresu śladu, który pokazuje trajektorię algorytmu Monte Carlo łańcucha Markowa w określonych ukrytych wymiarach. Poniżej widzimy, że określone efekty instruktorskie rzeczywiście znacząco przechodzą ze stanu początkowego i badają przestrzeń stanów. Wykres śladu wskazuje również, że efekty różnią się w zależności od instruktorów, ale mają podobne zachowanie podczas mieszania.
for i in range(7):
plt.plot(effect_instructors_samples[:, i])
plt.legend([i for i in range(7)], loc='lower right')
plt.ylabel('Instructor Effects')
plt.xlabel('Iteration')
plt.show()
Krytyka
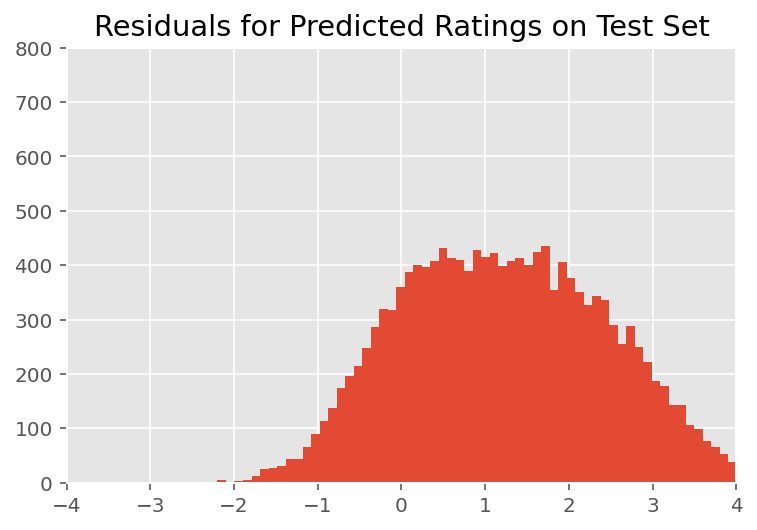
Powyżej dopasowaliśmy model. Przyjrzymy się teraz krytyce jego dopasowania za pomocą danych, które pozwalają nam zbadać i lepiej zrozumieć model. Jedną z takich technik jest wykres rezydualny, który przedstawia różnicę między przewidywaniami modelu a prawdą podstawową dla każdego punktu danych. Jeśli model był poprawny, to ich różnica powinna mieć rozkład normalny o standardowym rozkładzie; wszelkie odchylenia od tego wzorca na wykresie wskazują na niedopasowanie modelu.
Wykres rezydualny budujemy, najpierw tworząc rozkład predykcyjny a posteriori na podstawie ocen, który zastępuje wcześniejszy rozkład efektów losowych jego a posteriori danymi treningowymi. W szczególności prowadzimy model do przodu i przechwytujemy jego zależność od wcześniejszych efektów losowych za pomocą ich wywnioskowanych średnich a posteriori.
lmm_test = lmm_jointdist(features_test)
[
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
] = [
np.mean(x, axis=0).astype(np.float32) for x in [
effect_students_samples,
effect_instructors_samples,
effect_departments_samples
]
]
# Get the posterior predictive distribution
(*posterior_conditionals, ratings_posterior), _ = lmm_test.sample_distributions(
value=(
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
))
ratings_prediction = ratings_posterior.mean()
Po oględzinach pozostałości wyglądają nieco standardowo – normalnie rozmieszczone. Jednak dopasowanie nie jest idealne: w ogonach istnieje większa masa prawdopodobieństwa niż w rozkładzie normalnym, co wskazuje, że model może poprawić swoje dopasowanie poprzez rozluźnienie założeń dotyczących normalności.
W szczególności, choć jest najczęstszym użyć rozkładu normalnego do modelu oceny w InstEval zbioru danych, bliższe spojrzenie na danych wynika, że wskaźniki oceny Oczywiście są w rzeczywistości wartości porządkowych od 1 do 5. To sugeruje, że powinniśmy używać rozkład porządkowy, a nawet kategoryczny, jeśli mamy wystarczająco dużo danych, aby odrzucić względne uporządkowanie. Jest to jednowierszowa zmiana w powyższym modelu; ma zastosowanie ten sam kod wnioskowania.
plt.title("Residuals for Predicted Ratings on Test Set")
plt.xlim(-4, 4)
plt.ylim(0, 800)
plt.hist(ratings_prediction - labels_test, 75)
plt.show()
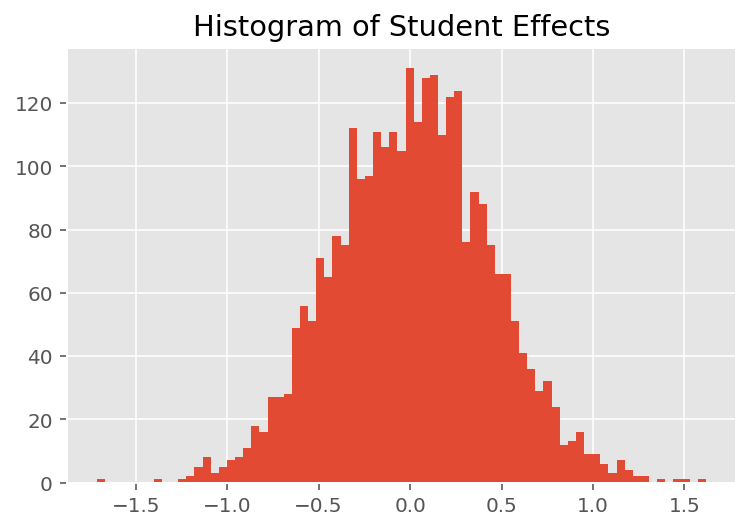
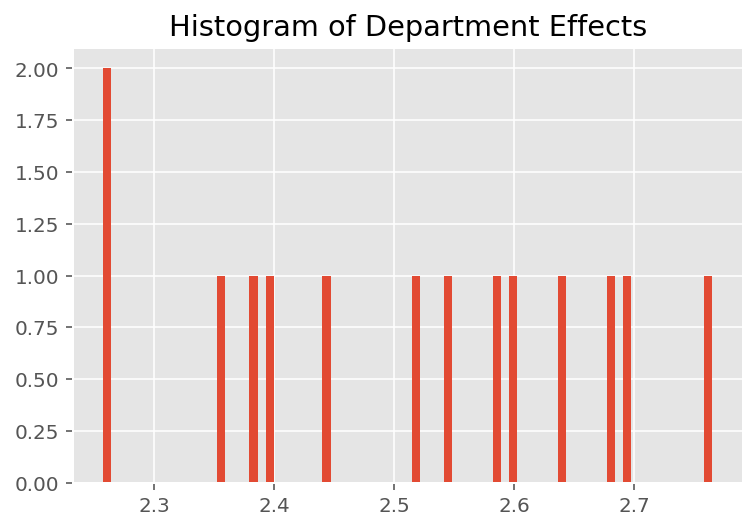
Aby zbadać, w jaki sposób model tworzy indywidualne prognozy, przyglądamy się histogramowi efektów dla uczniów, instruktorów i działów. Pozwala nam to zrozumieć, w jaki sposób poszczególne elementy w wektorze cech punktu danych mają tendencję do wpływania na wynik.
Nic dziwnego, że poniżej widzimy, że każdy uczeń ma zwykle niewielki wpływ na ocenę instruktora. Co ciekawe, widzimy, że duży wpływ ma wydział, do którego należy instruktor.
plt.title("Histogram of Student Effects")
plt.hist(effect_students_mean, 75)
plt.show()
plt.title("Histogram of Instructor Effects")
plt.hist(effect_instructors_mean, 75)
plt.show()
plt.title("Histogram of Department Effects")
plt.hist(effect_departments_mean, 75)
plt.show()
Przypisy
¹ Liniowe modele efektów mieszanych to szczególny przypadek, w którym możemy analitycznie obliczyć jego gęstość brzegową. Na potrzeby tego samouczka zademonstrujemy EM Monte Carlo, które łatwiej stosuje się do nieanalitycznych gęstości krańcowych, takich jak gdyby prawdopodobieństwo zostało rozszerzone na kategoryczne zamiast na normalne.
² Dla uproszczenia tworzymy średnią rozkładu predykcyjnego, używając tylko jednego przejścia modelu do przodu. Odbywa się to poprzez warunkowanie na średniej a posteriori i jest prawidłowe dla liniowych modeli efektów mieszanych. Jednak generalnie nie jest to zasadne: średnia rozkładu predykcyjnego a posteriori jest zazwyczaj niewykonalna i wymaga uwzględnienia średniej empirycznej w wielu przejściach do przodu modelu dla danych próbek a posteriori.
Podziękowanie
W Edward 1.0 (Ten poradnik został napisany źródłowego ). Dziękujemy wszystkim współtwórcom za napisanie i poprawienie tej wersji.
Bibliografia
Douglas Bates i Martin Machler oraz Ben Bolker i Steve Walker. Dopasowywanie liniowych modeli efektów mieszanych za pomocą lme4. Journal of Statistical Software, 67 (1): 1-48, 2015.
Arthur P. Dempster, Nan M. Laird i Donald B. Rubin. Maksymalne prawdopodobieństwo z niekompletnych danych za pomocą algorytmu EM. Journal of Royal Society Statystycznego, seria B (metodologiczny), 1-38, 1977.
Andrew Gelmana i Jennifer Hill. Analiza danych z wykorzystaniem regresji i modeli wielopoziomowych/hierarchicznych. Wydawnictwo Uniwersytetu Cambridge, 2006.
Davida A. Harville'a. Metody największej wiarygodności w estymacji składowych wariancji i związanych z nimi problemach. Journal of American Statistical Association, 72 (358): 320-338, 1977.
Michael I. Jordan. Wprowadzenie do modeli graficznych. Raport techniczny, 2003.
Nan M. Laird i James Ware. Modele efektów losowych dla danych podłużnych. Biometria, 963-974, 1982.
Greg Wei i Martin A. Tanner. Implementacja algorytmu EM w Monte Carlo i algorytmy augmentacji danych biednego człowieka. Journal of American Statistical Association, 699-704, 1990.