
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल दर्शाता है कि फीचर क्रॉस को प्रभावी ढंग से सीखने के लिए डीप एंड क्रॉस नेटवर्क (DCN) का उपयोग कैसे करें।
पृष्ठभूमि
फीचर क्रॉस क्या हैं और वे क्यों महत्वपूर्ण हैं? कल्पना कीजिए कि हम ग्राहकों को ब्लेंडर बेचने के लिए एक अनुशंसा प्रणाली का निर्माण कर रहे हैं। फिर, जैसे एक ग्राहक के पिछले खरीद इतिहास purchased_bananas और purchased_cooking_books , या भौगोलिक विशेषताओं, एकल विशेषताएं हैं। एक दोनों केले और खाना पकाने पुस्तकों की खरीदारी की है, तो यह ग्राहक अधिक होने की संभावना सिफारिश ब्लेंडर पर क्लिक करें। के संयोजन purchased_bananas और purchased_cooking_books एक सुविधा पार है, जो अलग-अलग सुविधाओं के अलावा अतिरिक्त बातचीत जानकारी प्रदान करता है के रूप में जाना जाता है।
फीचर क्रॉस सीखने में क्या चुनौतियाँ हैं? वेब-स्केल अनुप्रयोगों में, डेटा ज्यादातर श्रेणीबद्ध होते हैं, जिससे बड़े और विरल फीचर स्पेस होते हैं। इस सेटिंग में प्रभावी फीचर क्रॉस की पहचान करने के लिए अक्सर मैन्युअल फीचर इंजीनियरिंग या संपूर्ण खोज की आवश्यकता होती है। पारंपरिक फीड-फ़ॉरवर्ड मल्टीलेयर परसेप्ट्रोन (एमएलपी) मॉडल सार्वभौमिक फ़ंक्शन अनुमानक हैं; तथापि, वे कुशलता से भी 2 या 3 आदेश सुविधा पार [अनुमानित नहीं कर सकते हैं 1 , 2 ]।
डीप एंड क्रॉस नेटवर्क (DCN) क्या है? DCN को स्पष्ट और बाउंड-डिग्री क्रॉस सुविधाओं को अधिक प्रभावी ढंग से सीखने के लिए डिज़ाइन किया गया था। यह एक इनपुट परत (आमतौर पर एक embedding परत), कई पार परतों से युक्त एक क्रॉस नेटवर्क के द्वारा पीछा के साथ शुरू होता है कि मॉडल स्पष्ट सुविधा बातचीत, और उसके बाद का संयोजन करता है गहरी नेटवर्क के साथ कि मॉडल अंतर्निहित सुविधा बातचीत।
- क्रॉस नेटवर्क। यह DCN का मूल है। यह स्पष्ट रूप से प्रत्येक परत पर फीचर क्रॉसिंग लागू करता है, और उच्चतम बहुपद डिग्री परत की गहराई के साथ बढ़ जाती है। नीचे दिए चित्र \((i+1)\)पार परत मई।
- डीप नेटवर्क। यह एक पारंपरिक फीडफॉरवर्ड मल्टीलेयर परसेप्ट्रॉन (एमएलपी) है।
गहन नेटवर्क और पार नेटवर्क तो DCN [के रूप में जोड़ दिया जाता है 1 ]। आम तौर पर, हम क्रॉस नेटवर्क (स्टैक्ड स्ट्रक्चर) के शीर्ष पर एक गहरे नेटवर्क को ढेर कर सकते हैं; हम उन्हें समानांतर (समानांतर संरचना) में भी रख सकते हैं।
निम्नलिखित में, हम पहले एक खिलौना उदाहरण के साथ DCN का लाभ दिखाएंगे, और फिर हम आपको MovieLen-1M डेटासेट का उपयोग करके DCN का उपयोग करने के कुछ सामान्य तरीकों के बारे में बताएंगे।
आइए पहले इस कोलाब के लिए आवश्यक पैकेजों को स्थापित और आयात करें।
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
खिलौना उदाहरण
DCN के लाभों को स्पष्ट करने के लिए, आइए एक सरल उदाहरण के माध्यम से कार्य करें। मान लीजिए कि हमारे पास एक डेटासेट है जहां हम एक ब्लेंडर विज्ञापन पर ग्राहक द्वारा क्लिक करने की संभावना को मॉडल करने की कोशिश कर रहे हैं, इसकी विशेषताओं और लेबल को निम्नानुसार वर्णित किया गया है।
| विशेषताएं / लेबल | विवरण | मूल्य प्रकार / श्रेणी |
|---|---|---|
| \(x_1\) = देश | यह ग्राहक जिस देश में रहता है | इंट [0, 199] |
| \(x_2\) = केले | #केले ग्राहक ने खरीदे हैं | इंट [0, 23] |
| \(x_3\) = पाक कला पुस्तकें | # कुकिंग बुक्स जिसे ग्राहक ने खरीदा है | [0, 5] में इंट |
| \(y\) | एक ब्लेंडर विज्ञापन पर क्लिक करने की संभावना | -- |
फिर, हम डेटा को निम्नलिखित अंतर्निहित वितरण का पालन करने देते हैं:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
जहां संभावना \(y\) रैखिक दोनों निर्भर करता है सुविधाओं पर \(x_i\)की, लेकिन यह भी के बीच गुणक बातचीत पर \(x_i\)s '। हमारे मामले में, हम कह सकते हैं कि एक ब्लेंडर (क्रय की संभावना\(y\)) सिर्फ केले (खरीदने पर नहीं निर्भर करता है\(x_2\)) या पाक कला पुस्तकें (\(x_3\)), लेकिन यह भी केले और पाक कला पुस्तकें एक साथ खरीदने (पर\(x_2x_3\))
हम इसके लिए डेटा निम्नानुसार उत्पन्न कर सकते हैं:
सिंथेटिक डेटा जनरेशन
हम पहले परिभाषित \(f(x_1, x_2, x_3)\) के रूप में ऊपर वर्णित है।
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
आइए वितरण के बाद डेटा उत्पन्न करें, और डेटा को प्रशिक्षण के लिए 90% और परीक्षण के लिए 10% में विभाजित करें।
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
मॉडल निर्माण
हम क्रॉस नेटवर्क और डीप नेटवर्क दोनों को आजमाने जा रहे हैं ताकि यह दिखाया जा सके कि क्रॉस नेटवर्क सिफारिश करने वालों को क्या लाभ दे सकता है। चूंकि हमारे द्वारा अभी-अभी बनाए गए डेटा में केवल 2-ऑर्डर फ़ीचर इंटरैक्शन होते हैं, यह एकल-स्तरित क्रॉस नेटवर्क के साथ वर्णन करने के लिए पर्याप्त होगा। यदि हम उच्च-क्रम वाले फीचर इंटरैक्शन को मॉडल करना चाहते हैं, तो हम कई क्रॉस लेयर्स को स्टैक कर सकते हैं और एक मल्टी-लेयर क्रॉस नेटवर्क का उपयोग कर सकते हैं। हम जिन दो मॉडलों का निर्माण करेंगे वे हैं:
- केवल एक क्रॉस लेयर के साथ क्रॉस नेटवर्क;
- व्यापक और गहरी ReLU परतों के साथ डीप नेटवर्क।
हम पहले एक एकीकृत मॉडल वर्ग का निर्माण करते हैं जिसका नुकसान माध्य चुकता त्रुटि है।
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
फिर, हम क्रॉस नेटवर्क (आकार 3 की 1 क्रॉस परत के साथ) और ReLU- आधारित DNN (परत आकार [512, 256, 128] के साथ) निर्दिष्ट करते हैं:
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
मॉडल प्रशिक्षण
अब जब हमारे पास डेटा और मॉडल तैयार हैं, तो हम मॉडलों को प्रशिक्षित करने जा रहे हैं। हम पहले मॉडल प्रशिक्षण की तैयारी के लिए डेटा को फेरबदल और बैच करते हैं।
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
फिर, हम युगों की संख्या के साथ-साथ सीखने की दर को भी परिभाषित करते हैं।
epochs = 100
learning_rate = 0.4
ठीक है, अब सब कुछ तैयार है और मॉडलों को संकलित और प्रशिक्षित करते हैं। आप सेट कर सकते हैं verbose=True यदि आप कैसे देखने के लिए मॉडल की प्रगति चाहते हैं।
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
मॉडल मूल्यांकन
हम मूल्यांकन डेटासेट पर मॉडल के प्रदर्शन को सत्यापित करते हैं और रूट मीन स्क्वेर्ड एरर (आरएमएसई, जितना कम उतना बेहतर) की रिपोर्ट करते हैं।
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
हम चाहते हैं कि पार नेटवर्क हासिल परिमाण एक Relu आधारित DNN से RMSE कम परिमाण कम मानकों के साथ, देखें। इसने फीयर क्रॉस सीखने में एक क्रॉस नेटवर्क की दक्षता का सुझाव दिया है।
मॉडल समझ
हम पहले से ही जानते हैं कि हमारे डेटा में कौन से फीचर क्रॉस महत्वपूर्ण हैं, यह जांचना मजेदार होगा कि क्या हमारे मॉडल ने वास्तव में महत्वपूर्ण फीचर क्रॉस सीखा है। यह DCN में सीखे गए भार मैट्रिक्स की कल्पना करके किया जा सकता है। वजन \(W_{ij}\) सुविधा के बीच बातचीत का पता चला महत्व का प्रतिनिधित्व करता \(x_i\) और \(x_j\)।
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
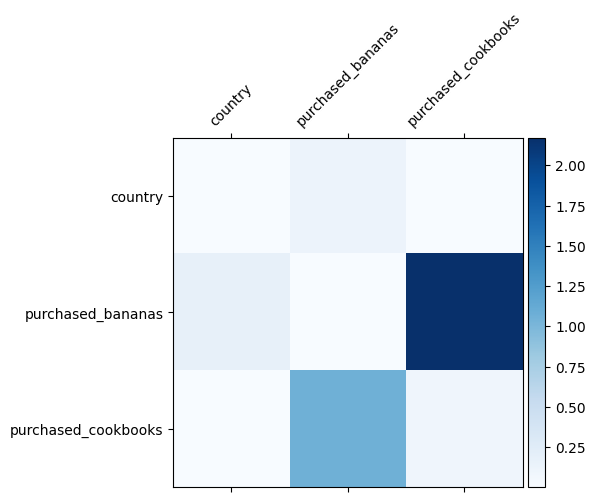
गहरे रंग मजबूत सीखी हुई बातचीत का प्रतिनिधित्व करते हैं - इस मामले में, यह स्पष्ट है कि मॉडल ने सीखा कि बबना और कुकबुक एक साथ खरीदना महत्वपूर्ण है।
आप और अधिक जटिल सिंथेटिक डेटा बाहर की कोशिश कर रहा में रुचि रखते हैं, बाहर की जाँच के लिए स्वतंत्र महसूस इस पत्र ।
Movielens 1M उदाहरण
अब हम एक वास्तविक दुनिया डेटासेट पर DCN की प्रभावशीलता की जांच: Movielens 1M [ 3 ]। Movielens 1M अनुशंसा अनुसंधान के लिए एक लोकप्रिय डेटासेट है। यह उपयोगकर्ता से संबंधित सुविधाओं और मूवी से संबंधित सुविधाओं को देखते हुए उपयोगकर्ताओं की मूवी रेटिंग की भविष्यवाणी करता है। हम इस डेटासेट का उपयोग DCN का उपयोग करने के कुछ सामान्य तरीकों को प्रदर्शित करने के लिए करते हैं।
डाटा प्रासेसिंग
डाटा प्रोसेसिंग प्रक्रिया के रूप में एक ऐसी ही प्रक्रिया इस प्रकार बुनियादी रैंकिंग ट्यूटोरियल ।
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
इसके बाद, हम बेतरतीब ढंग से प्रशिक्षण के लिए डेटा को 80% और परीक्षण के लिए 20% में विभाजित करते हैं।
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
फिर, हम प्रत्येक सुविधा के लिए शब्दावली बनाते हैं।
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
मॉडल निर्माण
हम जिस मॉडल आर्किटेक्चर का निर्माण कर रहे हैं, वह एक एम्बेडिंग लेयर से शुरू होता है, जिसे एक क्रॉस नेटवर्क में फीड किया जाता है और उसके बाद एक डीप नेटवर्क। सभी सुविधाओं के लिए एम्बेडिंग आयाम 32 पर सेट है। आप विभिन्न सुविधाओं के लिए विभिन्न एम्बेडिंग आकारों का भी उपयोग कर सकते हैं।
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
मॉडल प्रशिक्षण
हम प्रशिक्षण और परीक्षण डेटा को फेरबदल, बैच और कैश करते हैं।
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
आइए एक फ़ंक्शन को परिभाषित करें जो एक मॉडल को कई बार चलाता है और मॉडल के आरएमएसई माध्य और मानक विचलन को कई रनों में से लौटाता है।
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
हम मॉडलों के लिए कुछ हाइपर-पैरामीटर सेट करते हैं। ध्यान दें कि ये हाइपर-पैरामीटर प्रदर्शन के उद्देश्य से सभी मॉडलों के लिए विश्व स्तर पर सेट किए गए हैं। यदि आप प्रत्येक मॉडल के लिए सर्वश्रेष्ठ प्रदर्शन प्राप्त करना चाहते हैं, या मॉडलों के बीच उचित तुलना करना चाहते हैं, तो हम आपको हाइपर-पैरामीटर को फ़ाइन-ट्यून करने का सुझाव देंगे। याद रखें कि मॉडल आर्किटेक्चर और ऑप्टिमाइज़ेशन स्कीम आपस में जुड़े हुए हैं।
epochs = 8
learning_rate = 0.01
डीसीएन (स्टैक्ड)। हम पहले एक DCN मॉडल को एक स्टैक्ड स्ट्रक्चर के साथ प्रशिक्षित करते हैं, अर्थात, इनपुट को एक क्रॉस नेटवर्क को फीड किया जाता है और उसके बाद एक डीप नेटवर्क।
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
निम्न-श्रेणी DCN। प्रशिक्षण और सेवा लागत को कम करने के लिए, हम DCN भार मैट्रिक्स का अनुमान लगाने के लिए निम्न-श्रेणी की तकनीकों का लाभ उठाते हैं। रैंक तर्क के माध्यम से में पारित हो जाता है projection_dim ; एक छोटे projection_dim एक कम लागत में परिणाम है। ध्यान दें कि projection_dim जरूरतों लागत को कम करने (इनपुट आकार) / 2 की तुलना में छोटा। व्यवहार में, हमने देखा है कि रैंक (इनपुट आकार)/4 के साथ निम्न-श्रेणी DCN का उपयोग करके पूर्ण-रैंक DCN की सटीकता को लगातार बनाए रखा जाता है।
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
डीएनएन. हम संदर्भ के रूप में समान आकार के DNN मॉडल को प्रशिक्षित करते हैं।
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
हम परीक्षण डेटा पर मॉडल का मूल्यांकन करते हैं और 5 रनों में से माध्य और मानक विचलन की रिपोर्ट करते हैं।
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
हम देखते हैं कि DCN ने ReLU परतों वाले समान आकार के DNN की तुलना में बेहतर प्रदर्शन प्राप्त किया है। इसके अलावा, निम्न-श्रेणी DCN सटीकता बनाए रखते हुए मापदंडों को कम करने में सक्षम था।
डीसीएन पर अधिक। What've ऊपर प्रदर्शन किया गया इसके अलावा, वहाँ DCN [उपयोग करने के लिए और अधिक रचनात्मक अभी तक व्यावहारिक रूप से उपयोगी तरीके हैं 1 ]।
एक समानांतर संरचना के साथ DCN। इनपुट को एक क्रॉस नेटवर्क और एक डीप नेटवर्क के समानांतर में फीड किया जाता है।
क्रॉस लेयर्स को जोड़ना। पूरक फीचर क्रॉस को पकड़ने के लिए इनपुट को कई क्रॉस लेयर्स के समानांतर में फीड किया जाता है।
मॉडल समझ
वजन मैट्रिक्स \(W\) DCN में क्या सुविधा को पार मॉडल महत्वपूर्ण होने के लिए सीखा है पता चलता है। याद है कि पिछले खिलौना उदाहरण में, के बीच संबंधों के महत्व को \(i\)वें और \(j\)वें सुविधाओं (द्वारा कब्जा कर लिया है\(i, j\)) की मई के तत्व \(W\)।
क्या कुछ अलग यहाँ है कि सुविधा embeddings 32 आकार के बजाय इसलिए आकार 1. के हैं, महत्व की विशेषता हो जाएगा \((i, j)\)वें ब्लॉक\(W_{i,j}\) 32. द्वारा आयाम 32 की है जो निम्नलिखित में, हम Frobenius आदर्श [कल्पना 4 ] \(||W_{i,j}||_F\) प्रत्येक ब्लॉक की, और एक बड़ा आदर्श उच्च महत्व सुझाव है (यह मानते हुए सुविधाओं 'embeddings समान तराजू के हैं)।
ब्लॉक मानदंड के अलावा, हम संपूर्ण मैट्रिक्स, या प्रत्येक ब्लॉक के माध्य/माध्य/अधिकतम मान की कल्पना भी कर सकते हैं।
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
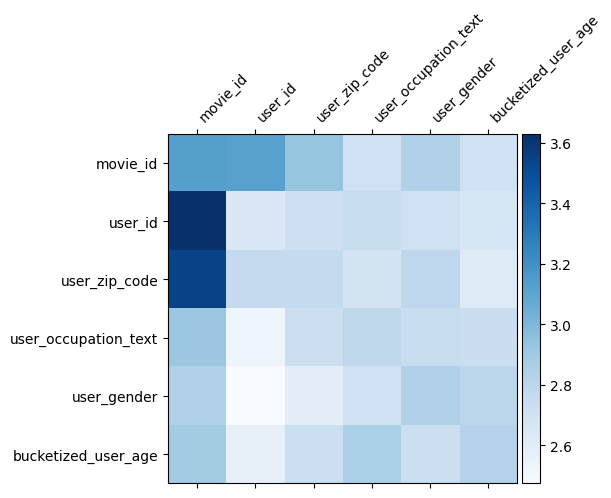
इस कोलाब के लिए बस इतना ही! हम आशा करते हैं कि आपको DCN की कुछ बुनियादी बातें और इसका उपयोग करने के सामान्य तरीके सीखने में मज़ा आया होगा। : यदि आप अधिक सीखने में रुचि रखते हैं, तो आप दो प्रासंगिक कागजात की जाँच कर सकता है DCN v1 के कागज , DCN-वी 2-पेपर ।
संदर्भ
DCN V2: रैंक प्रणाली के लिए वेब पैमाने पर प्रशिक्षण के लिए बेहतर दीप एंड अंतर नेटवर्क और व्यावहारिक सबक ।
रूक्सी वांग, राकेश शिवन्ना, डेरेक ज़ियुआन चेंग, सागर जैन, डोंग लिन, लिचन होंग, एड ची। (2020)
विज्ञापन क्लिक भविष्यवाणियों के लिए दीप एंड अंतर नेटवर्क ।
रूक्सी वांग, बिन फू, गैंग फू, मिंगलियांग वांग। (AdKDD 2017)