
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan cara menggunakan Deep & Cross Network (DCN) untuk mempelajari persilangan fitur secara efektif.
Latar belakang
Apa itu persilangan fitur dan mengapa itu penting? Bayangkan kita sedang membangun sistem rekomendasi untuk menjual blender ke pelanggan. Kemudian, sejarah pembelian masa lalu pelanggan seperti purchased_bananas dan purchased_cooking_books , atau fitur geografis, fitur tunggal. Jika salah satu telah membeli kedua pisang dan buku memasak, maka pelanggan ini akan lebih mungkin klik pada blender direkomendasikan. Kombinasi purchased_bananas dan purchased_cooking_books disebut sebagai salib fitur, yang menyediakan informasi interaksi tambahan di luar fitur individu.
Apa saja tantangan dalam mempelajari persilangan fitur? Dalam aplikasi skala Web, sebagian besar data bersifat kategoris, yang mengarah ke ruang fitur yang besar dan jarang. Mengidentifikasi persilangan fitur yang efektif dalam pengaturan ini sering kali memerlukan rekayasa fitur manual atau pencarian menyeluruh. Model feed-forward multilayer perceptron (MLP) tradisional adalah aproksimator fungsi universal; Namun, mereka tidak bisa efisien mendekati bahkan 2 atau 3-order salib fitur [ 1 , 2 ].
Apa itu Deep & Cross Network (DCN)? DCN dirancang untuk mempelajari fitur lintas derajat yang eksplisit dan terbatas secara lebih efektif. Dimulai dengan lapisan masukan (biasanya lapisan embedding), diikuti oleh jaringan lintas mengandung beberapa lapisan lintas yang model eksplisit fitur interaksi, dan kemudian menggabungkan dengan jaringan yang mendalam bahwa model interaksi fitur implisit.
- Lintas Jaringan. Ini adalah inti dari DCN. Ini secara eksplisit menerapkan persilangan fitur pada setiap lapisan, dan derajat polinomial tertinggi meningkat dengan kedalaman lapisan. Gambar berikut menunjukkan yang \((i+1)\)-th lapisan silang.
- Jaringan Dalam. Ini adalah perceptron multilayer feedforward tradisional (MLP).
Jaringan dalam dan jaringan lintas kemudian digabungkan untuk membentuk DCN [ 1 ]. Biasanya, kita dapat menumpuk jaringan yang dalam di atas jaringan silang (struktur bertumpuk); kita juga bisa menempatkannya secara paralel (struktur paralel).
Berikut ini, pertama-tama kami akan menunjukkan keuntungan DCN dengan contoh mainan, dan kemudian kami akan memandu Anda melalui beberapa cara umum untuk menggunakan DCN menggunakan dataset MovieLen-1M.
Pertama-tama, instal dan impor paket yang diperlukan untuk colab ini.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Contoh Mainan
Untuk mengilustrasikan manfaat DCN, mari kita bekerja melalui contoh sederhana. Misalkan kita memiliki kumpulan data tempat kita mencoba memodelkan kemungkinan pelanggan mengklik Iklan blender, dengan fitur dan labelnya dijelaskan sebagai berikut.
| Fitur / Label | Keterangan | Jenis Nilai / Rentang |
|---|---|---|
| \(x_1\) = negara | negara tempat pelanggan ini tinggal | Int dalam [0, 199] |
| \(x_2\) = pisang | # pisang yang dibeli customer | Int dalam [0, 23] |
| \(x_3\) = buku masak | # buku memasak yang dibeli pelanggan | Int dalam [0, 5] |
| \(y\) | kemungkinan mengklik iklan blender | -- |
Kemudian, kami membiarkan data mengikuti distribusi dasar berikut:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
di mana kemungkinan \(y\) tergantung linear baik pada fitur \(x_i\)'s, tetapi juga pada interaksi perkalian antara \(x_i\)' s. Dalam kasus kami, kami akan mengatakan bahwa kemungkinan membeli blender (\(y\)) tidak tergantung hanya pada membeli pisang (\(x_2\)) atau buku masak (\(x_3\)), tetapi juga untuk membeli pisang dan buku masak bersama-sama (\(x_2x_3\)).
Kami dapat menghasilkan data untuk ini sebagai berikut:
Pembuatan data sintetis
Kami pertama mendefinisikan \(f(x_1, x_2, x_3)\) seperti dijelaskan di atas.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Mari buat data yang mengikuti distribusi, dan bagi data menjadi 90% untuk pelatihan dan 10% untuk pengujian.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Konstruksi model
Kami akan mencoba jaringan lintas dan jaringan dalam untuk menggambarkan keuntungan yang dapat diberikan oleh jaringan lintas kepada pemberi rekomendasi. Karena data yang baru saja kita buat hanya berisi interaksi fitur urutan ke-2, itu akan cukup untuk diilustrasikan dengan jaringan lintas satu lapis. Jika kami ingin memodelkan interaksi fitur tingkat tinggi, kami dapat menumpuk beberapa lapisan silang dan menggunakan jaringan lintas berlapis banyak. Dua model yang akan kami buat adalah:
- Lintas Jaringan dengan hanya satu lapisan silang;
- Deep Network dengan lapisan ReLU yang lebih luas dan lebih dalam.
Kami pertama-tama membangun kelas model terpadu yang kerugiannya adalah kesalahan kuadrat rata-rata.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Kemudian, kita tentukan cross network (dengan 1 cross layer ukuran 3) dan DNN berbasis ReLU (dengan ukuran layer [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Pelatihan model
Sekarang setelah kita memiliki data dan model, kita akan melatih modelnya. Kami mengacak dan mengelompokkan data terlebih dahulu untuk mempersiapkan pelatihan model.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Kemudian, kami menentukan jumlah epoch serta learning rate.
epochs = 100
learning_rate = 0.4
Baiklah, semuanya sudah siap sekarang dan mari kita kompilasi dan latih modelnya. Anda bisa mengatur verbose=True jika Anda ingin melihat bagaimana kemajuan Model.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Evaluasi model
Kami memverifikasi kinerja model pada dataset evaluasi dan melaporkan Root Mean Squared Error (RMSE, semakin rendah semakin baik).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Kita melihat bahwa salib jaringan besaran dicapai menurunkan RMSE dari DNN berbasis ReLU, dengan parameter besaran yang lebih sedikit. Hal ini menunjukkan efisiensi jaringan silang dalam mempelajari persilangan fitur.
Pemahaman model
Kita sudah mengetahui persilangan fitur apa yang penting dalam data kita, akan menyenangkan untuk memeriksa apakah model kita memang telah mempelajari persilangan fitur yang penting. Ini dapat dilakukan dengan memvisualisasikan matriks bobot yang dipelajari di DCN. Berat \(W_{ij}\) mewakili pentingnya belajar dari interaksi antara fitur \(x_i\) dan \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
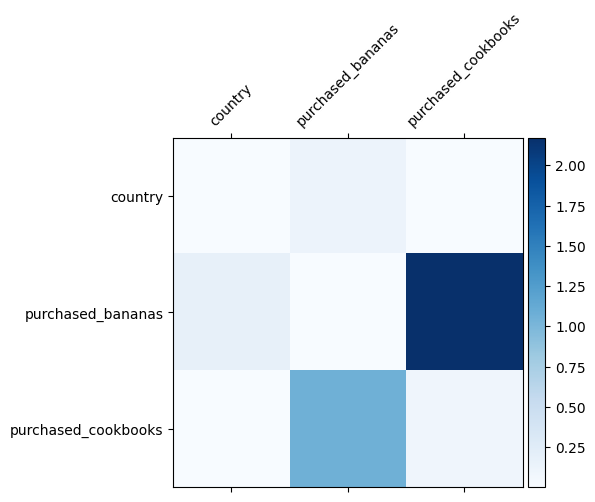
Warna yang lebih gelap mewakili interaksi terpelajar yang lebih kuat - dalam hal ini, jelas bahwa model belajar bahwa membeli babana dan buku masak bersama adalah penting.
Jika Anda tertarik untuk mencoba data sintetik lebih rumit, merasa bebas untuk memeriksa makalah ini .
Contoh Movielens 1M
Kami sekarang mengetahui efektivitas DCN pada dataset dunia nyata: Movielens 1M [ 3 ]. Movielens 1M adalah kumpulan data populer untuk penelitian rekomendasi. Ini memprediksi peringkat film pengguna yang diberikan fitur terkait pengguna dan fitur terkait film. Kami menggunakan kumpulan data ini untuk mendemonstrasikan beberapa cara umum untuk memanfaatkan DCN.
Pengolahan data
Prosedur pengolahan data mengikuti prosedur yang sama seperti tutorial peringkat dasar .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Selanjutnya, kami membagi data secara acak menjadi 80% untuk pelatihan dan 20% untuk pengujian.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Kemudian, kami membuat kosakata untuk setiap fitur.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Konstruksi model
Arsitektur model yang akan kita bangun dimulai dengan lapisan embedding, yang dimasukkan ke dalam jaringan silang diikuti oleh jaringan dalam. Dimensi penyematan diatur ke 32 untuk semua fitur. Anda juga dapat menggunakan ukuran penyematan yang berbeda untuk fitur yang berbeda.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Pelatihan model
Kami mengacak, mengelompokkan, dan menyimpan data pelatihan dan pengujian dalam cache.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Mari kita definisikan fungsi yang menjalankan model beberapa kali dan mengembalikan rata-rata RMSE model dan deviasi standar dari beberapa proses.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Kami menetapkan beberapa parameter hiper untuk model. Perhatikan bahwa parameter hiper ini disetel secara global untuk semua model untuk tujuan demonstrasi. Jika Anda ingin mendapatkan kinerja terbaik untuk setiap model, atau melakukan perbandingan yang adil di antara model, maka kami sarankan Anda untuk menyempurnakan parameter hiper. Ingatlah bahwa arsitektur model dan skema optimasi saling terkait.
epochs = 8
learning_rate = 0.01
DCN (bertumpuk). Kami pertama-tama melatih model DCN dengan struktur bertumpuk, yaitu, input diumpankan ke jaringan silang diikuti oleh jaringan dalam.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN peringkat rendah. Untuk mengurangi biaya pelatihan dan penyajian, kami memanfaatkan teknik peringkat rendah untuk memperkirakan matriks bobot DCN. Rank dilewatkan melalui argumen projection_dim ; lebih kecil projection_dim menghasilkan biaya yang lebih rendah. Perhatikan bahwa projection_dim kebutuhan lebih kecil dari (ukuran input) / 2 untuk mengurangi biaya. Dalam praktiknya, kami mengamati penggunaan DCN peringkat rendah dengan peringkat (ukuran input)/4 secara konsisten mempertahankan keakuratan DCN peringkat penuh.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Kami melatih model DNN berukuran sama sebagai referensi.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Kami mengevaluasi model pada data uji dan melaporkan mean dan standar deviasi dari 5 run.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Kami melihat bahwa DCN mencapai kinerja yang lebih baik daripada DNN berukuran sama dengan lapisan ReLU. Selain itu, DCN peringkat rendah mampu mengurangi parameter dengan tetap menjaga akurasi.
Lebih lanjut tentang DCN. Selain what've dibuktikan di atas, ada lebih kreatif cara belum praktis berguna untuk memanfaatkan DCN [ 1 ].
DCN dengan struktur paralel. Input diumpankan secara paralel ke jaringan silang dan jaringan dalam.
Menggabungkan lapisan silang. Input diumpankan secara paralel ke beberapa lapisan silang untuk menangkap persilangan fitur yang saling melengkapi.
Pemahaman model
Matriks berat \(W\) di DCN mengungkapkan apa fitur melintasi model telah belajar untuk menjadi penting. Ingat bahwa dalam contoh mainan sebelumnya, pentingnya interaksi antara \(i\)-th dan \(j\)-th fitur ditangkap oleh (\(i, j\)) elemen -th \(W\).
Apa sedikit berbeda di sini adalah bahwa embeddings fitur yang ukuran 32 bukan ukuran 1. Oleh karena itu, pentingnya akan ditandai oleh \((i, j)\)-th blok\(W_{i,j}\) yang dimensi 32 dengan 32. Berikut ini, kami memvisualisasikan Frobenius norma [ 4 ] \(||W_{i,j}||_F\) dari setiap blok, dan norma yang lebih besar akan menyarankan pentingnya lebih tinggi (dengan asumsi fitur embeddings adalah timbangan yang sejenis).
Selain norma blok, kita juga dapat memvisualisasikan seluruh matriks, atau nilai mean/median/maks dari setiap blok.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
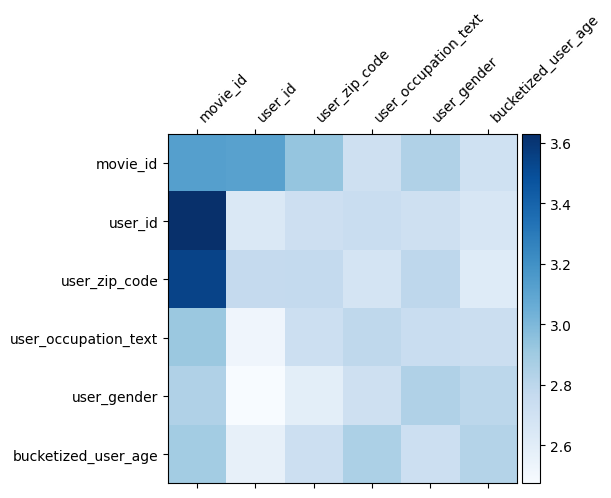
Itu saja untuk colab ini! Kami harap Anda menikmati mempelajari beberapa dasar DCN dan cara umum untuk menggunakannya. Jika Anda tertarik untuk belajar lebih lanjut, Anda bisa memeriksa dua makalah yang relevan: DCN-v1-kertas , DCN-v2-kertas .
Referensi
DCN V2: Peningkatan Jauh & Cross Jaringan dan Pelajaran Praktis untuk Web skala Belajar Ranking Sistem .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Mendalam & Cross Jaringan Iklan Klik Prediksi .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)