
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
이 자습서에서는 DCN(Deep & Cross Network)을 사용하여 특성 교차를 효과적으로 학습하는 방법을 보여줍니다.
배경
특성 교차는 무엇이며 왜 중요한가요? 고객에게 믹서기를 판매하기 위해 추천 시스템을 구축하고 있다고 상상해보십시오. 다음과 같은 고객의 과거 구매 내역 purchased_bananas 및 purchased_cooking_books , 또는 지리적 특징은 하나의 기능입니다. 하나는 바나나와 요리 책을 모두 구입 한 경우,이 고객은 가능성이 권장 믹서기를 클릭합니다. 의 조합 purchased_bananas 및 purchased_cooking_books 개별 기능 이외의 추가 상호 작용 정보를 제공하는 기능을 크로스로 지칭된다.
특성 교차 학습의 어려움은 무엇입니까? 웹 규모 응용 프로그램에서 데이터는 대부분 범주형이므로 크고 희소한 기능 공간이 생깁니다. 이 설정에서 효과적인 기능 교차를 식별하려면 종종 수동 기능 엔지니어링 또는 철저한 검색이 필요합니다. 기존의 피드포워드 다중층 퍼셉트론(MLP) 모델은 범용 함수 근사기입니다. 그러나, 효율적 심지어 2 또는 3 차 기능 교차 [대략 수 1 , 2 ].
딥앤크로스네트워크(DCN)란? DCN은 명시적 및 경계 교차 기능을 보다 효과적으로 학습하도록 설계되었습니다. 그것은 다수의 교차 층을 포함하는 상호 네트워크에 의해 다음에 입력 층 (전형적으로 매립 층)로 시작하는 다음과 깊은 네트워크 모델 명시 기능 상호 작용 및 기능을 결합 모델에 내재 상호있다.
- 크로스 네트워크. 이것이 DCN의 핵심입니다. 각 레이어에 피처 교차를 명시적으로 적용하고 레이어 깊이에 따라 가장 높은 다항식 차수가 증가합니다. 다음도 표시 \((i+1)\)크로스 레이어 번째.
- 딥 네트워크. 이것은 전통적인 피드포워드 다층 퍼셉트론(MLP)입니다.
깊은 네트워크와 네트워크 간 후 DCN [형성하도록 결합되는 1 ]. 일반적으로 교차 네트워크(적층 구조) 위에 깊은 네트워크를 쌓을 수 있습니다. 병렬로 배치할 수도 있습니다(병렬 구조).
다음에서는 먼저 장난감 예를 통해 DCN의 장점을 보여주고 MovieLen-1M 데이터 세트를 사용하여 DCN을 활용하는 몇 가지 일반적인 방법을 안내합니다.
먼저 이 colab에 필요한 패키지를 설치하고 가져오겠습니다.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
장난감 예
DCN의 이점을 설명하기 위해 간단한 예를 살펴보겠습니다. 고객이 블렌더 광고를 클릭할 가능성을 모델링하려고 하는 데이터 세트가 있고 기능과 레이블이 다음과 같이 설명되어 있다고 가정합니다.
| 기능/라벨 | 설명 | 값 유형/범위 |
|---|---|---|
| \(x_1\) = 국가 | 이 고객이 거주하는 국가 | [0, 199]의 정수 |
| \(x_2\) = 바나나 | 고객이 구매한 바나나 #개 | [0, 23]의 정수 |
| \(x_3\) 요리 책 = | 고객이 구매한 요리 책 #개 | [0, 5]의 정수 |
| \(y\) | 블렌더 광고를 클릭할 가능성 | -- |
그런 다음 데이터가 다음 기본 분포를 따르도록 합니다.
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
우도 여기서 \(y\) 기능에 의존 모두 직선 \(x_i\)의뿐만 아니라, 상호 간의 곱셈에 \(x_i\)S '. 우리의 경우, 우리는 믹서기 (구매의 가능성이 있음을 말할 것\(y\)) 단지 바나나 (구입에없는 달려\(x_2\)) 또는 요리 책 (\(x_3\))뿐만 아니라 함께 바나나와 요리 책을 구입 (에\(x_2x_3\)).
이에 대한 데이터는 다음과 같이 생성할 수 있습니다.
합성 데이터 생성
우리는 먼저 정의 \(f(x_1, x_2, x_3)\) 상기 한 바와 같이.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
분포를 따르는 데이터를 생성하고 데이터를 학습용 90%, 테스트용 10%로 분할해 보겠습니다.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
모델 구축
교차 네트워크가 추천자에게 제공할 수 있는 이점을 설명하기 위해 교차 네트워크와 심층 네트워크를 모두 시험해 볼 것입니다. 방금 생성한 데이터에는 2차 기능 상호 작용만 포함되어 있으므로 단일 계층 교차 네트워크로 설명하는 것으로 충분합니다. 고차 기능 상호 작용을 모델링하려면 여러 교차 레이어를 쌓고 다층 교차 네트워크를 사용할 수 있습니다. 우리가 만들 두 가지 모델은 다음과 같습니다.
- 하나의 크로스 레이어만 있는 크로스 네트워크
- 더 넓고 더 깊은 ReLU 레이어가 있는 딥 네트워크.
먼저 손실이 평균 제곱 오차인 통합 모델 클래스를 빌드합니다.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
그런 다음 교차 네트워크(크기 3의 1개의 교차 레이어 포함)와 ReLU 기반 DNN(계층 크기 [512, 256, 128] 포함)을 지정합니다.
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
모델 교육
이제 데이터와 모델이 준비되었으므로 모델을 훈련할 것입니다. 먼저 모델 훈련을 준비하기 위해 데이터를 섞고 배치합니다.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
그런 다음 epoch 수와 학습률을 정의합니다.
epochs = 100
learning_rate = 0.4
자, 이제 모든 것이 준비되었으며 모델을 컴파일하고 훈련해 보겠습니다. 당신은 설정할 수 verbose=True 어떻게 모델 진행되면서보고 싶다면.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
모델 평가
평가 데이터 세트에서 모델 성능을 확인하고 Root Mean Squared Error(RMSE, 낮을수록 좋음)를 보고합니다.
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
우리는 십자가 네트워크를 달성 크기가 크기 이하의 매개 변수와 함께하는 ReLU 기반 DNN보다 RMSE 낮은 것을 알 수있다. 이것은 학습 특성 교차에서 교차 네트워크의 효율성을 제안했습니다.
모델 이해
우리는 이미 데이터에서 어떤 특성 교차가 중요한지 알고 있습니다. 우리 모델이 실제로 중요한 특성 교차를 학습했는지 확인하는 것은 재미있을 것입니다. 이것은 DCN에서 학습된 가중치 행렬을 시각화하여 수행할 수 있습니다. 무게 \(W_{ij}\) 기능 사이의 상호 작용의 학습 중요성을 나타냅니다 \(x_i\) 및 \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
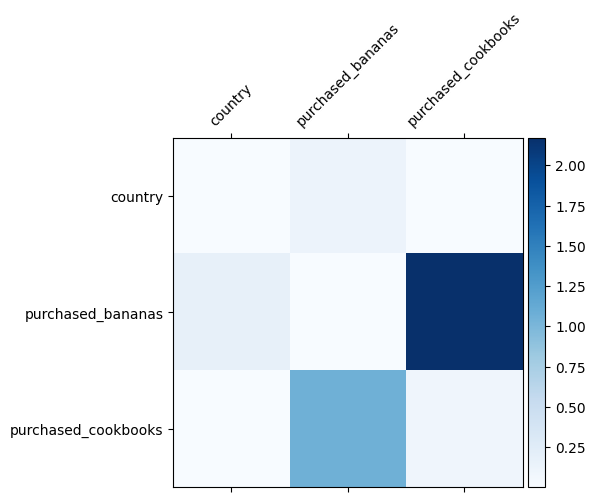
어두운 색상은 학습된 상호작용이 더 강력함을 나타냅니다. 이 경우 모델은 바바나와 요리책을 함께 구매하는 것이 중요하다는 것을 학습한 것이 분명합니다.
좀 더 복잡한 합성 데이터를 시도에 관심이 있다면, 체크 아웃 자유롭게 이 논문을 .
무비렌즈 1M 예시
우리는 지금 실제 데이터 세트에 DCN의 유효성을 검사 : Movielens 1M [ 3 ]. Movielens 1M은 추천 연구를 위한 인기 있는 데이터 세트입니다. 사용자 관련 기능 및 영화 관련 기능을 고려하여 사용자의 영화 등급을 예측합니다. 이 데이터 세트를 사용하여 DCN을 활용하는 몇 가지 일반적인 방법을 보여줍니다.
데이터 처리
데이터 처리 절차와 유사한 절차는 다음 기본 입문서 순위 .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
다음으로, 데이터를 학습용 80%, 테스트용 20%로 무작위로 나눕니다.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
그런 다음 각 기능에 대한 어휘를 만듭니다.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
모델 구축
우리가 구축할 모델 아키텍처는 임베딩 레이어로 시작하여 크로스 네트워크에 이어 심층 네트워크에 공급됩니다. 임베딩 차원은 모든 기능에 대해 32로 설정됩니다. 다른 기능에 대해 다른 임베딩 크기를 사용할 수도 있습니다.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
모델 교육
훈련 및 테스트 데이터를 섞고 일괄 처리하고 캐시합니다.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
모델을 여러 번 실행하고 여러 실행에서 모델의 RMSE 평균과 표준 편차를 반환하는 함수를 정의해 보겠습니다.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
모델에 대해 일부 하이퍼 매개변수를 설정했습니다. 이러한 하이퍼 매개변수는 데모 목적으로 모든 모델에 대해 전역적으로 설정됩니다. 각 모델에 대한 최상의 성능을 얻거나 모델 간에 공정한 비교를 수행하려면 하이퍼 매개변수를 미세 조정하는 것이 좋습니다. 모델 아키텍처와 최적화 체계는 서로 얽혀 있다는 것을 기억하십시오.
epochs = 8
learning_rate = 0.01
DCN(스택). 먼저 스택 구조로 DCN 모델을 훈련합니다.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
하위 DCN. 교육 및 제공 비용을 줄이기 위해 낮은 순위 기술을 활용하여 DCN 가중치 행렬을 근사화합니다. 순위는 인수를 통해 전달 된 projection_dim ; A는 작은 projection_dim 저렴한 비용의 결과. 참고 projection_dim 요구는 비용을 줄이기 위해 (입력 크기) / 2보다 작게. 실제로 순위(입력 크기)/4가 있는 하위 DCN을 사용하여 전체 순위 DCN의 정확도를 일관되게 유지하는 것을 관찰했습니다.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. 동일한 크기의 DNN 모델을 참조로 훈련합니다.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
테스트 데이터에 대한 모델을 평가하고 5회 실행 중 평균 및 표준 편차를 보고합니다.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
DCN은 ReLU 레이어가 있는 동일한 크기의 DNN보다 더 나은 성능을 달성했음을 알 수 있습니다. 또한 하위 DCN은 정확도를 유지하면서 매개변수를 줄일 수 있었습니다.
DCN에 대해 자세히 알아보십시오. 위의 증명되었다 뭘 더 외에도, DCN [활용할 수있는 창의적인 아직 실질적으로 유용한 방법이 있습니다 1 ].
병렬 구조 DCN. 입력은 교차 네트워크 및 심층 네트워크에 병렬로 공급됩니다.
교차 레이어 연결. 입력은 상호 보완적인 기능 교차를 캡처하기 위해 여러 교차 레이어에 병렬로 공급됩니다.
모델 이해
무게 매트릭스 \(W\) DCN에서이 기능은 모델이 중요하게 배운 교차하는 것을 알 수있다. 이전 장난감 예에서 사이의 상호 작용의 중요성 것을 기억 \(i\)번째 및 \(j\)특징 번째가 (에 포착되는\(i, j\))의 번째 요소 \(W\).
어떤 비트 다른 여기 것은 기능 묻어 크기 (32) 대신에 따라서 크기 1로하고, 중요성이 특징으로 할 것입니다 \((i, j)\)번째 블록\(W_{i,j}\) 다음에 (32)에 의해 치수 32, 우리 의 Frobenius 규범 [시각화 4 ] \(||W_{i,j}||_F\) 각 블록, 및 높은 중요도를 제안 큰 규범 (기능 "묻어 유사한 스케일 가정하에).
블록 노름 외에도 전체 행렬 또는 각 블록의 평균/중앙값/최대값을 시각화할 수도 있습니다.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
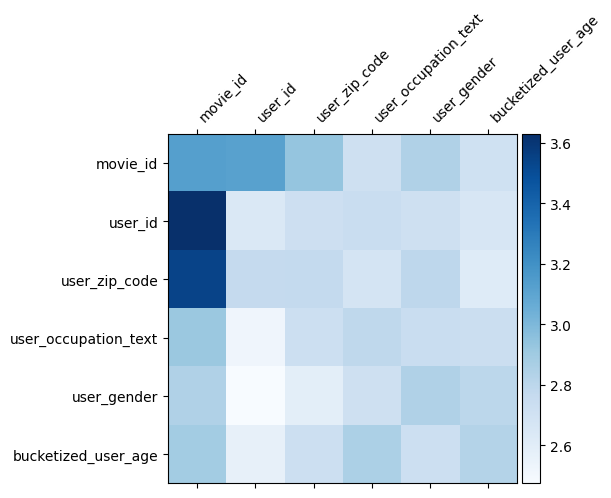
이것이 이 콜라보의 전부입니다! DCN의 몇 가지 기본 사항과 이를 활용하는 일반적인 방법을 즐겁게 배우셨기를 바랍니다. : 당신이 더 많은 학습에 관심이 있다면, 당신은 두 개의 관련 서류 확인 할 수 DCN-V1-종이 , DCN-V2-종이 .
참고문헌
DCN V2는 : 순위 시스템에 대한 웹 규모의 학습에 대한 깊은 & 크로스 네트워크 및 실제 수업을 개선 .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
광고를 클릭 예측에 대한 깊은 & 크로스 네트워크 .
루오시 왕, 빈푸, 강푸, 왕밍량. (AdKDD 2017)