
Gambaran
Fitur utama TensorBoard adalah GUI interaktifnya. Namun, pengguna kadang-kadang ingin pemrograman membaca log data yang disimpan dalam TensorBoard, untuk tujuan seperti melakukan post-hoc analisis dan menciptakan visualisasi kustom dari data log.
TensorBoard 2.3 mendukung penggunaan kasus ini dengan tensorboard.data.experimental.ExperimentFromDev() . Hal ini memungkinkan program akses ke TensorBoard ini log skalar . Halaman ini menunjukkan penggunaan dasar API baru ini.
Mempersiapkan
Dalam rangka untuk menggunakan API program, pastikan Anda menginstal pandas bersama tensorboard .
Kami akan menggunakan matplotlib dan seaborn untuk plot kustom dalam buku ini, tetapi Anda dapat memilih alat pilihan Anda untuk menganalisis dan memvisualisasikan DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Memuat skalar TensorBoard sebagai pandas.DataFrame
Setelah LogDir TensorBoard telah di-upload ke TensorBoard.dev, menjadi apa yang kita sebut sebagai percobaan. Setiap eksperimen memiliki ID unik, yang dapat ditemukan di URL TensorBoard.dev eksperimen. Untuk demonstrasi kami di bawah ini, kita akan menggunakan sebuah eksperimen TensorBoard.dev di: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df adalah pandas.DataFrame yang berisi semua log skalar percobaan.
Kolom dari DataFrame adalah:
-
run: setiap berkorespondensi lari ke sebuah subdirektori dari LogDir asli. Dalam eksperimen ini, setiap proses berasal dari pelatihan lengkap jaringan saraf convolutional (CNN) pada dataset MNIST dengan tipe pengoptimal yang diberikan (hiperparameter pelatihan). IniDataFrameberisi beberapa berjalan seperti itu, yang sesuai dengan berjalan pelatihan diulang di bawah jenis optimizer yang berbeda. -
tag: ini menjelaskan apavaluedalam sarana baris yang sama, yaitu, apa metrik nilai mewakili dalam baris. Dalam percobaan ini, kita hanya memiliki dua tag unik:epoch_accuracydanepoch_lossuntuk akurasi dan kehilangan metrik masing-masing. -
step: Ini adalah angka yang mencerminkan urutan serial yang sesuai baris dalam menjalankan nya. Berikutstepsebenarnya mengacu pada jumlah zaman. Jika Anda ingin mendapatkan cap waktu di sampingstepnilai-nilai, Anda dapat menggunakan argumen kata kunciinclude_wall_time=Truesaat memanggilget_scalars(). -
value: ini adalah nilai numerik yang sebenarnya menarik. Seperti dijelaskan di atas, masing-masingvaluekhususnya iniDataFrameadalah baik kehilangan atau akurasi, tergantung padatagbaris.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Mendapatkan DataFrame berporos (bentuk lebar)
Dalam percobaan kami, dua tag ( epoch_loss dan epoch_accuracy ) yang hadir di set yang sama langkah-langkah dalam menjalankan setiap. Hal ini memungkinkan untuk mendapatkan "wide-bentuk" DataFrame langsung dari get_scalars() dengan menggunakan pivot=True argumen kata kunci. Lebar-bentuk DataFrame memiliki semua tag yang termasuk sebagai kolom dari DataFrame, yang lebih nyaman untuk bekerja dengan dalam beberapa kasus termasuk yang satu ini.
Namun, berhati-hatilah bahwa jika kondisi memiliki seragam set nilai-nilai langkah di semua tag dalam semua berjalan tidak terpenuhi, menggunakan pivot=True akan menghasilkan kesalahan.
dfw = experiment.get_scalars(pivot=True)
dfw
Perhatikan bahwa bukannya kolom "value" tunggal, lebar-bentuk DataFrame meliputi dua tag (metrik) sebagai kolom yang secara eksplisit: epoch_accuracy dan epoch_loss .
Menyimpan DataFrame sebagai CSV
pandas.DataFrame memiliki interoperabilitas yang baik dengan CSV . Anda dapat menyimpannya sebagai file CSV lokal dan memuatnya kembali nanti. Sebagai contoh:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Melakukan visualisasi khusus dan analisis statistik
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
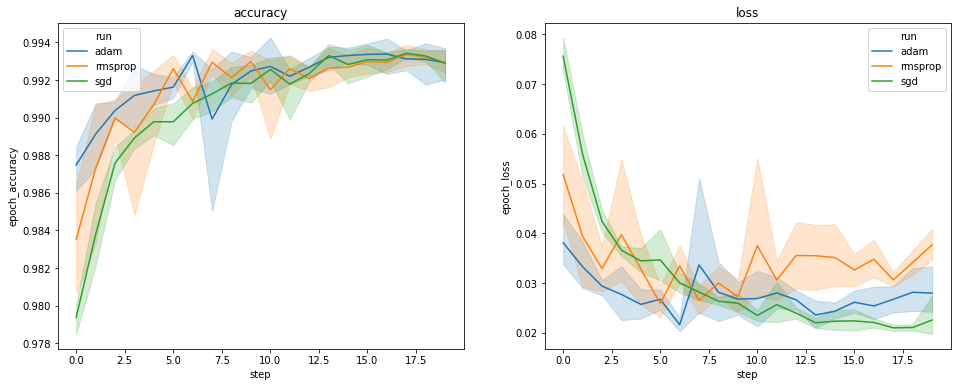
Plot di atas menunjukkan waktu akurasi validasi dan kehilangan validasi. Setiap kurva menunjukkan rata-rata di 5 proses di bawah jenis pengoptimal. Berkat fitur built-in dari seaborn.lineplot() , masing-masing kurva juga menampilkan ± 1 standar deviasi sekitar mean, yang memberi kita rasa yang jelas tentang variabilitas dalam kurva ini dan signifikansi perbedaan antara ketiga jenis optimizer. Visualisasi variabilitas ini belum didukung di GUI TensorBoard.
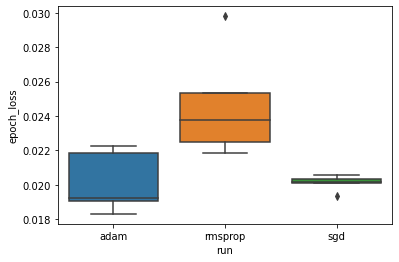
Kami ingin mempelajari hipotesis bahwa kehilangan validasi minimum berbeda secara signifikan antara pengoptimal "adam", "rmsprop" dan "sgd". Jadi kami mengekstrak DataFrame untuk kehilangan validasi minimum di bawah masing-masing pengoptimal.
Kemudian kita membuat boxplot untuk memvisualisasikan perbedaan kerugian validasi minimum.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Oleh karena itu, pada tingkat signifikansi 0,05, analisis kami mengkonfirmasi hipotesis kami bahwa kehilangan validasi minimum secara signifikan lebih tinggi (yaitu, lebih buruk) di pengoptimal rmsprop dibandingkan dengan dua pengoptimal lain yang disertakan dalam percobaan kami.
Singkatnya, tutorial ini memberikan contoh bagaimana untuk mengakses data skalar sebagai panda.DataFrame s dari TensorBoard.dev. Ini menunjukkan jenis analisis fleksibel dan kuat dan visualisasi yang dapat Anda lakukan dengan DataFrame s.