
Panoramica
La caratteristica principale di TensorBoard è la sua GUI interattiva. Tuttavia, a volte gli utenti vogliono leggere a livello di codice i registri di dati memorizzati nella TensorBoard, per esempio a fini di eseguire analisi post-hoc e la creazione di visualizzazioni personalizzate dei dati di log.
TensorBoard 2.3 supporta questo caso l'uso con tensorboard.data.experimental.ExperimentFromDev() . Permette l'accesso programmatico al di TensorBoard log scalari . Questa pagina mostra l'utilizzo di base di questa nuova API.
Impostare
Per poter utilizzare l'API di programmazione, assicurarsi di installare pandas a fianco tensorboard .
Useremo matplotlib e seaborn per i grafici personalizzati in questa guida, ma si può scegliere il vostro strumento preferito per analizzare e visualizzare DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Caricamento scalari TensorBoard come pandas.DataFrame
Una volta che un logdir TensorBoard è stato caricato TensorBoard.dev, diventa ciò che noi definiamo come un esperimento. Ogni esperimento ha un ID univoco, che può essere trovato nell'URL TensorBoard.dev dell'esperimento. Per la nostra dimostrazione di seguito, useremo un esperimento TensorBoard.dev a: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df è un pandas.DataFrame che contiene tutti i registri scalari dell'esperimento.
Le colonne del DataFrame sono:
-
run: ognuno corrisponde esecuzione di una sottodirectory della logdir originale. In questo esperimento, ogni esecuzione proviene da un addestramento completo di una rete neurale convoluzionale (CNN) sul set di dati MNIST con un determinato tipo di ottimizzatore (un iperparametro di addestramento). QuestoDataFramecontiene più tali piste, che corrispondono alle corse di allenamento ripetute in diversi tipi Optimizer. -
tag: questo descrive cosa ilvaluenello stesso mezzo di riga, cioè, la metrica del valore rappresenta nella riga. In questo esperimento, abbiamo solo due tag univoci:epoch_accuracyeepoch_lossper l'accuratezza e la perdita di metriche rispettivamente. -
step: Questo è un numero che riflette l'ordine seriale della riga corrispondente nella sua corsa. Quistepsi riferisce in realtà al numero epoca. Se si desidera ottenere il timestamp oltre aistepvalori, è possibile utilizzare l'argomento parola chiaveinclude_wall_time=Truequando si chiamaget_scalars(). -
value: Questo è il valore numerico effettivo di interesse. Come descritto sopra, ognivaluein questa particolareDataFrameè o una perdita o una precisione, a seconda deltagdella riga.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Ottenere un DataFrame ruotato (di formato largo)
Nel nostro esperimento, i due tag ( epoch_loss e epoch_accuracy ) sono presenti nello stesso insieme di passi in ogni seduta. Ciò consente di ottenere una "wide-forma" DataFrame direttamente da get_scalars() utilizzando il pivot=True argomento chiave. L'ampia forma DataFrame ha tutti i suoi tag inclusi come colonne del dataframe, che è più conveniente per lavorare con, in alcuni casi, tra cui questo.
Tuttavia, attenzione che se la condizione di avere insiemi uniformi di valori step attraverso tutti i tag in tutte le esecuzioni non è soddisfatta, utilizzando pivot=True provocherà un errore.
dfw = experiment.get_scalars(pivot=True)
dfw
Si noti che invece di una singola colonna "valore", il livello di modulo dataframe include i due tag (metriche) come le sue colonne in modo esplicito: epoch_accuracy e epoch_loss .
Salvare il DataFrame come CSV
pandas.DataFrame ha una buona interoperabilità con CSV . Puoi archiviarlo come file CSV locale e ricaricarlo in un secondo momento. Per esempio:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Esecuzione di visualizzazioni personalizzate e analisi statistiche
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
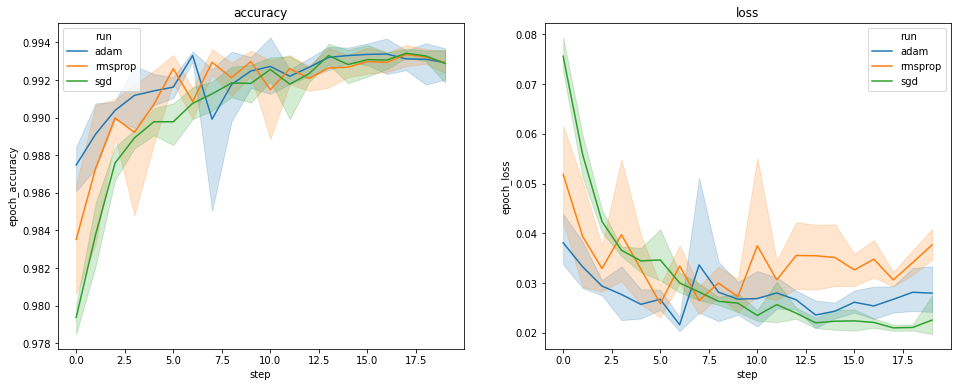
I grafici sopra mostrano i tempi dell'accuratezza della convalida e della perdita di convalida. Ogni curva mostra la media su 5 esecuzioni con un tipo di ottimizzatore. Grazie ad una funzione incorporata della seaborn.lineplot() , ciascuna curva anche display ± 1 deviazione standard intorno alla media, che ci dà un chiaro senso della variabilità in queste curve e la significatività delle differenze tra i tre tipi di ottimizzatore. Questa visualizzazione della variabilità non è ancora supportata nella GUI di TensorBoard.
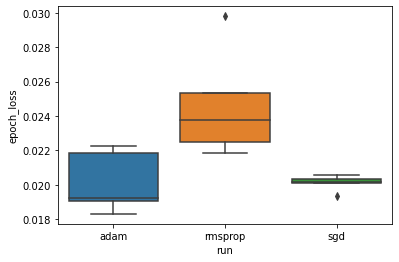
Si vuole studiare l'ipotesi che la minima perdita di validazione differisca significativamente tra gli ottimizzatori "adam", "rmsprop" e "sgd". Quindi estraiamo un DataFrame per la perdita di convalida minima sotto ciascuno degli ottimizzatori.
Quindi creiamo un boxplot per visualizzare la differenza nelle perdite minime di convalida.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Pertanto, a un livello di significatività di 0,05, la nostra analisi conferma la nostra ipotesi che la perdita di convalida minima sia significativamente più alta (cioè peggiore) nell'ottimizzatore rmsprop rispetto agli altri due ottimizzatori inclusi nel nostro esperimento.
In sintesi, questo tutorial fornisce un esempio di come accedere ai dati scalari come panda.DataFrame s da TensorBoard.dev. Essa dimostra il tipo di analisi e visualizzazione flessibili e potenti che si possono fare con la DataFrame s.