
Катастрофические события, связанные с NaN , иногда могут возникать во время работы программы TensorFlow, нанося вред процессам обучения модели. Первопричина таких событий часто неясна, особенно для моделей нетривиального размера и сложности. Чтобы упростить отладку ошибок модели такого типа, в TensorBoard 2.3+ (вместе с TensorFlow 2.3+) предусмотрена специализированная панель мониторинга под названием Debugger V2. Здесь мы демонстрируем, как использовать этот инструмент, устраняя реальную ошибку, связанную с NaN в нейронной сети, написанной на TensorFlow.
Методы, показанные в этом руководстве, применимы к другим типам действий по отладке, например к проверке форм тензоров времени выполнения в сложных программах. В этом руководстве основное внимание уделяется NaN из-за их относительно высокой частоты появления.
Наблюдение за ошибкой
Исходный код программы TF2, которую мы будем отлаживать, доступен на GitHub . Пример программы также упакован в пакет tensorflow pip (версия 2.3+) и может быть вызван с помощью:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Эта программа TF2 создает многоуровневое восприятие (MLP) и обучает его распознаванию изображений MNIST . В этом примере намеренно используется низкоуровневый API TF2 для определения пользовательских конструкций слоев, функции потерь и цикла обучения, поскольку вероятность ошибок NaN выше, когда мы используем этот более гибкий, но более подверженный ошибкам API, чем когда мы используем более простой удобные в использовании, но немного менее гибкие API высокого уровня, такие как tf.keras .
Программа печатает точность теста после каждого шага обучения. В консоли мы видим, что точность теста зависает на почти случайном уровне (~ 0,1) после первого шага. Определенно, это не то, как ожидается обучение модели: мы ожидаем, что точность будет постепенно приближаться к 1,0 (100%) по мере увеличения шага.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Обоснованное предположение состоит в том, что эта проблема вызвана числовой нестабильностью, такой как NaN или бесконечность. Однако как мы можем подтвердить, что это действительно так, и как найти операцию TensorFlow (op), ответственную за генерацию числовой нестабильности? Чтобы ответить на эти вопросы, давайте оснастим программу с ошибками с помощью Debugger V2.
Инструментирование кода TensorFlow с помощью Debugger V2
tf.debugging.experimental.enable_dump_debug_info() — это точка входа API в отладчик V2. Он реализует программу TF2 с помощью одной строки кода. Например, добавление следующей строки в начало программы приведет к записи отладочной информации в каталог журнала (logdir) по адресу /tmp/tfdbg2_logdir. Информация об отладке охватывает различные аспекты среды выполнения TensorFlow. В TF2 он включает в себя полную историю быстрого выполнения, построение графиков, выполняемое @tf.function , выполнение графиков, значения тензора, сгенерированные событиями выполнения, а также расположение кода (трассировки стека Python) этих событий. . Богатство отладочной информации позволяет пользователям выявить неясные ошибки.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
Аргумент tensor_debug_mode управляет тем, какую информацию отладчик V2 извлекает из каждого активного тензора или тензора в графе. «FULL_HEALTH» — это режим, который собирает следующую информацию о каждом тензоре плавающего типа (например, о часто встречающемся типе float32 и менее распространенном dtype bfloat16 ):
- DТип
- Классифицировать
- Общее количество элементов
- Разбивка элементов плавающего типа на следующие категории: отрицательная конечная (
-), ноль (0), положительная конечная (+), отрицательная бесконечность (-∞), положительная бесконечность (+∞) иNaN.
Режим «FULL_HEALTH» подходит для отладки ошибок, связанных с NaN и бесконечностью. Другие поддерживаемые tensor_debug_mode см. ниже.
Аргумент circular_buffer_size контролирует, сколько событий тензора сохраняется в каталоге журналов. По умолчанию оно равно 1000, что приводит к сохранению на диске только последних 1000 тензоров перед завершением инструментированной программы TF2. Такое поведение по умолчанию снижает накладные расходы отладчика, жертвуя полнотой отладочных данных. Если полнота предпочтительна, как в этом случае, мы можем отключить циклический буфер, установив для аргумента отрицательное значение (например, -1 здесь).
Пример debug_mnist_v2 вызывает enable_dump_debug_info() , передавая ему флаги командной строки. Чтобы снова запустить нашу проблемную программу TF2 с включенным инструментом отладки, выполните:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Запуск графического интерфейса отладчика V2 в TensorBoard
Запуск программы с помощью инструментов отладчика создает каталог журнала в /tmp/tfdbg2_logdir. Мы можем запустить TensorBoard и указать ему каталог журнала с помощью:
tensorboard --logdir /tmp/tfdbg2_logdir
В веб-браузере перейдите на страницу TensorBoard по адресу http://localhost:6006. Плагин «Отладчик V2» по умолчанию неактивен, поэтому выберите его в меню «Неактивные плагины» в правом верхнем углу. После выбора он должен выглядеть следующим образом:
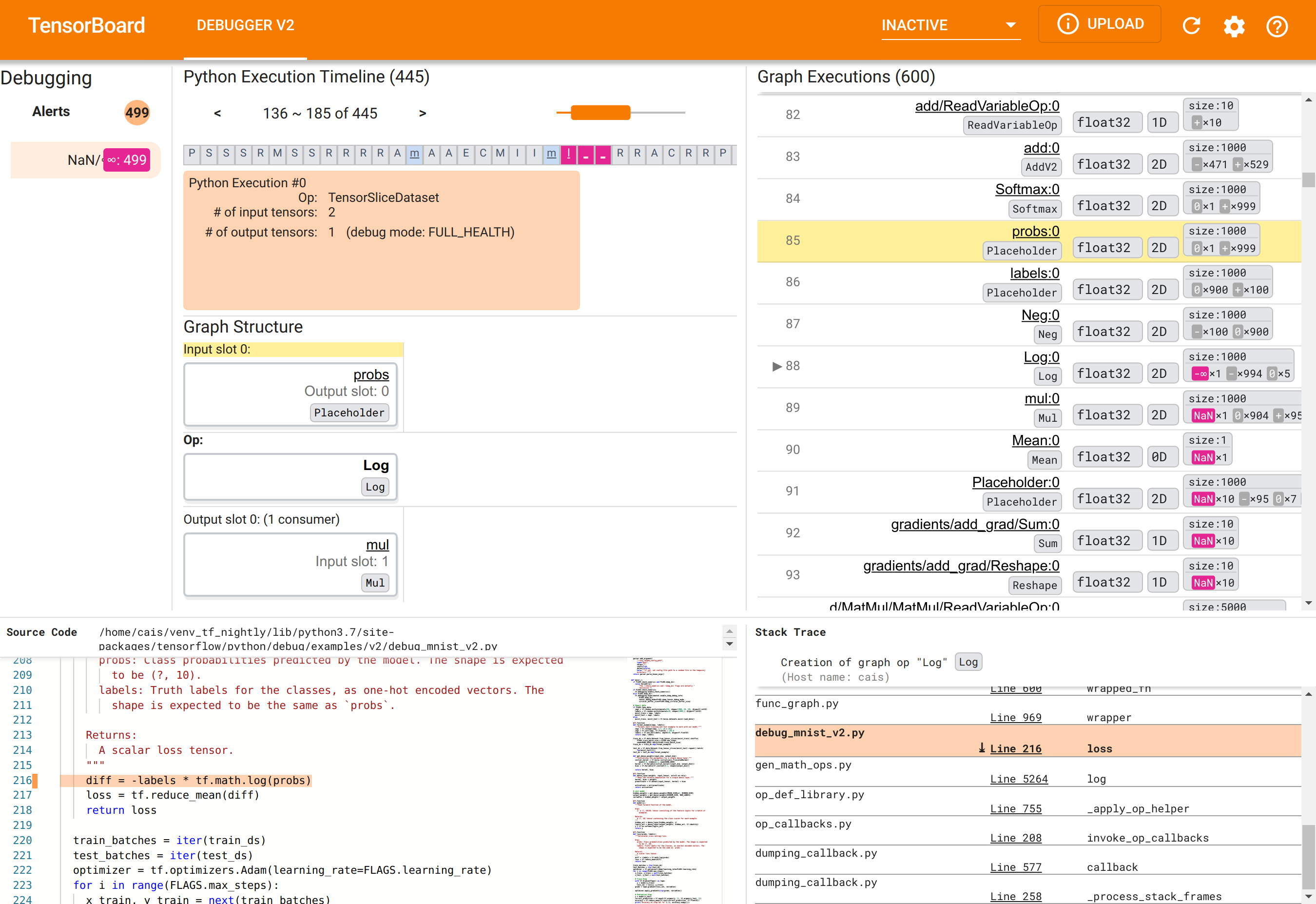
Использование графического интерфейса отладчика V2 для поиска основной причины NaN
Графический интерфейс Debugger V2 в TensorBoard разделен на шесть разделов:
- Оповещения : этот верхний левый раздел содержит список событий «предупреждений», обнаруженных отладчиком в данных отладки инструментированной программы TensorFlow. Каждое предупреждение указывает на определенную аномалию, требующую внимания. В нашем случае в этом разделе выделены 499 событий NaN/∞ ярким розово-красным цветом. Это подтверждает наше подозрение, что модель не может обучаться из-за присутствия NaN и/или бесконечностей в значениях ее внутреннего тензора. Вскоре мы углубимся в эти оповещения.
- Временная шкала выполнения Python : это верхняя половина верхнего среднего раздела. В нем представлена полная история оперативного выполнения операций и графиков. Каждый блок временной шкалы отмечен начальной буквой имени операции или графа (например, «T» для операции «TensorSliceDataset», «m» для «модели»
tf.function). Мы можем перемещаться по этой временной шкале, используя кнопки навигации и полосу прокрутки над временной шкалой. - Выполнение графика : этот раздел, расположенный в правом верхнем углу графического пользовательского интерфейса, будет центральным в нашей задаче отладки. Он содержит историю всех тензоров плавающего типа, вычисленных внутри графов (т. е. скомпилированных с помощью
@tf-functions). - Структура графа (нижняя половина верхнего среднего раздела), исходный код (нижний левый раздел) и трассировка стека (нижний правый раздел) изначально пусты. Их содержимое будет заполнено при взаимодействии с графическим интерфейсом. Эти три раздела также будут играть важную роль в нашей задаче отладки.
Ориентируясь на организацию пользовательского интерфейса, давайте предпримем следующие шаги, чтобы разобраться, почему появились NaN. Сначала щелкните предупреждение NaN/∞ в разделе «Предупреждения». Это автоматически прокручивает список из 600 тензоров графа в разделе «Выполнение графика» и фокусируется на #88, который представляет собой тензор с именем Log:0 , сгенерированный операцией Log (натуральный логарифм). Яркий розово-красный цвет выделяет элемент -∞ среди 1000 элементов 2D-тензора float32. Это первый тензор в истории выполнения программы TF2, который содержал NaN или бесконечность: тензоры, вычисленные до него, не содержат NaN или ∞; многие (фактически большинство) тензоров, вычисленных впоследствии, содержат NaN. Мы можем подтвердить это, прокручивая вверх и вниз список выполнения графика. Это наблюдение дает убедительный намек на то, что Log op является источником численной нестабильности в этой программе TF2.
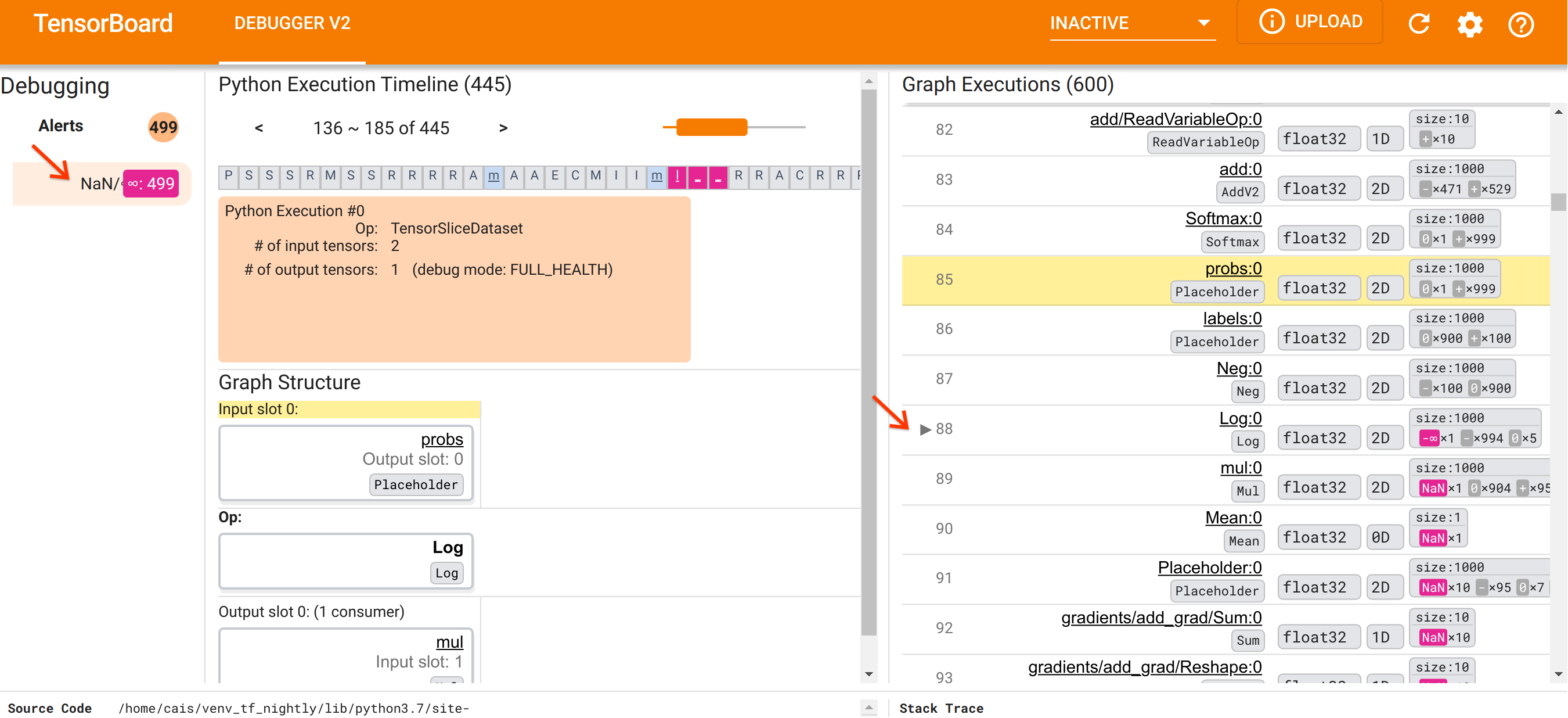
Почему в этом Log выдается -∞? Ответ на этот вопрос требует изучения входных данных в операцию. Нажатие на имя тензора ( Log:0 ) вызывает простую, но информативную визуализацию окрестности операции Log на графике TensorFlow в разделе «Структура графика». Обратите внимание на направление потока информации сверху вниз. Сама операция выделена жирным шрифтом посередине. Непосредственно над ним мы видим, что операция Placeholder предоставляет единственные входные данные для операции Log . Где находится тензор, сгенерированный этим заполнителем probs в списке выполнения графика? Используя желтый цвет фона в качестве наглядного пособия, мы видим, что тензор probs:0 находится на три строки выше тензора Log:0 , то есть в строке 85.
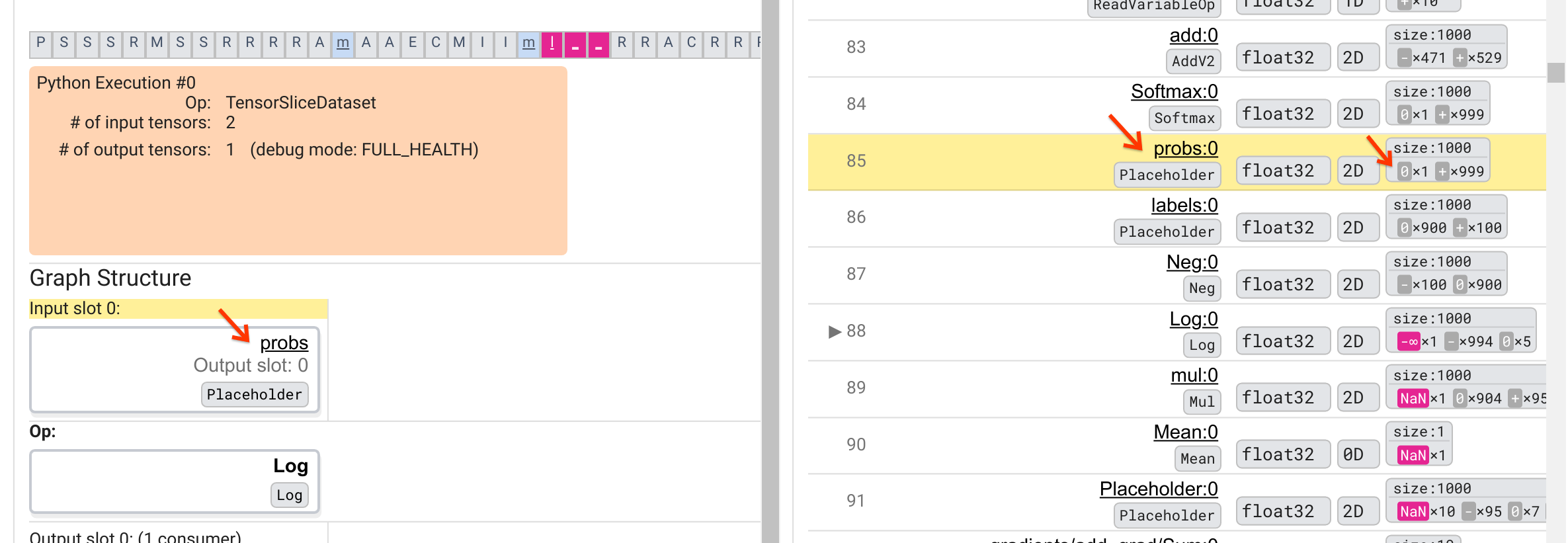
Более внимательный взгляд на числовую разбивку тензора probs:0 в строке 85 показывает, почему его потребитель Log:0 выдает -∞: среди 1000 элементов probs:0 один элемент имеет значение 0. -∞ результат вычисления натурального логарифма 0! Если мы сможем каким-то образом гарантировать, что операция Log будет подвергаться воздействию только положительных входных данных, мы сможем предотвратить появление NaN/∞. Этого можно добиться путем применения отсечения (например, с помощью tf.clip_by_value() ) к тензору probs -заполнителей.
Мы приближаемся к устранению ошибки, но еще не закончили. Чтобы применить исправление, нам нужно знать, где в исходном коде Python возникла операция Log и входные данные заполнителя. Отладчик V2 обеспечивает первоклассную поддержку отслеживания операций графа и событий выполнения до их источника. Когда мы щелкнули тензор Log:0 в разделе «Выполнения графиков», раздел «Трассировка стека» был заполнен исходной трассировкой стека создания операции Log . Трассировка стека довольно велика, поскольку она включает в себя множество кадров из внутреннего кода TensorFlow (например, gen_math_ops.py и dumping_callback.py), которые мы можем спокойно игнорировать для большинства задач отладки. Объектом интереса является строка 216 файла debug_mnist_v2.py (т. е. файл Python, который мы на самом деле пытаемся отладить). Нажатие «Строка 216» открывает представление соответствующей строки кода в разделе «Исходный код».
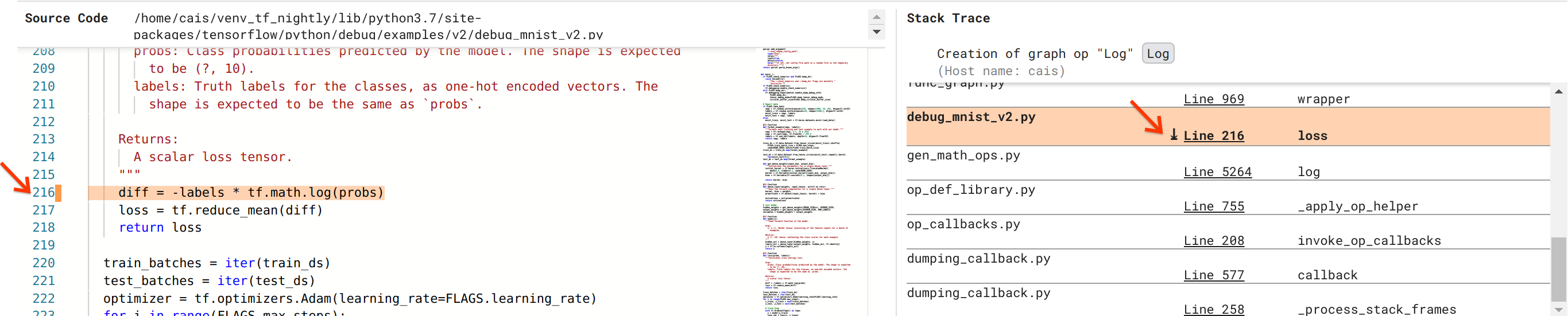
Это, наконец, подводит нас к исходному коду, который создал проблемную операцию Log на основе входных probs . Это наша пользовательская категориальная функция перекрестной энтропии, украшенная @tf.function и, следовательно, преобразованная в граф TensorFlow. probs Placeholder соответствуют первому входному аргументу функции потерь. Операция Log создается с помощью вызова API tf.math.log().
Исправление этой ошибки с обрезкой значений будет выглядеть примерно так:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Это устранит численную нестабильность в этой программе TF2 и обеспечит успешное обучение MLP. Другой возможный подход к исправлению числовой нестабильности — использовать tf.keras.losses.CategoricalCrossentropy .
На этом завершается наш путь от наблюдения за ошибкой модели TF2 до изменения кода, исправляющего ошибку, с помощью инструмента Debugger V2, который обеспечивает полную видимость нетерпеливой и графической истории выполнения инструментированной программы TF2, включая числовые сводки. значений тензоров и связи между операторами, тензорами и их исходным исходным кодом.
Аппаратная совместимость отладчика V2
Отладчик V2 поддерживает основное оборудование для обучения, включая ЦП и графический процессор. Также поддерживается обучение нескольких графических процессоров с помощью tf.distributed.MirroredStrategy . Поддержка ТПУ все еще находится на ранней стадии и требует звонка.
tf.config.set_soft_device_placement(True)
перед вызовом enable_dump_debug_info() . Могут быть и другие ограничения для TPU. Если у вас возникли проблемы при использовании отладчика V2, сообщите об ошибках на нашей странице проблем GitHub .
Совместимость API отладчика V2
Отладчик V2 реализован на относительно низком уровне программного стека TensorFlow и, следовательно, совместим с tf.keras , tf.data и другими API, построенными на основе нижних уровней TensorFlow. Отладчик V2 также обратно совместим с TF1, хотя временная шкала Eager Execution Timeline будет пустой для каталогов журналов отладки, созданных программами TF1.
Советы по использованию API
Часто задаваемый вопрос об этом API отладки — где в коде TensorFlow следует вставить вызов enable_dump_debug_info() . Как правило, API следует вызывать как можно раньше в вашей программе TF2, желательно после строк импорта Python и до начала построения и выполнения графа. Это обеспечит полный охват всех операций и графиков, лежащих в основе вашей модели и ее обучения.
В настоящее время поддерживаются следующие режимы tensor_debug_modes: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH и SHAPE . Они различаются по объему информации, извлекаемой из каждого тензора, и по производительности отлаживаемой программы. Пожалуйста, обратитесь к разделу args документации enable_dump_debug_info() .
Накладные расходы на производительность
API отладки увеличивает производительность инструментированной программы TensorFlow. Накладные расходы зависят от tensor_debug_mode , типа оборудования и характера инструментированной программы TensorFlow. Для справки: на графическом процессоре режим NO_TENSOR добавляет 15 % накладных расходов во время обучения модели Transformer с размером пакета 64. Процентные накладные расходы для других tensor_debug_modes выше: примерно 50 % для CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH и SHAPE режимы. На процессорах накладные расходы немного ниже. На TPU накладные расходы в настоящее время выше.
Связь с другими API-интерфейсами отладки TensorFlow.
Обратите внимание, что TensorFlow предлагает другие инструменты и API для отладки. Вы можете просмотреть такие API в пространстве имен tf.debugging.* на странице документации API. Среди этих API наиболее часто используется tf.print() . Когда следует использовать Debugger V2, а когда вместо него следует использовать tf.print() ? tf.print() удобен в том случае, если
- мы точно знаем, какие тензоры печатать,
- мы знаем, где именно в исходном коде нужно вставить эти операторы
tf.print(), - число таких тензоров не слишком велико.
В других случаях (например, проверка множества значений тензора, проверка значений тензора, сгенерированных внутренним кодом TensorFlow, и поиск причины числовой нестабильности, как мы показали выше), Debugger V2 обеспечивает более быстрый способ отладки. Кроме того, Debugger V2 обеспечивает унифицированный подход к проверке тензоров активных и графовых тензоров. Он дополнительно предоставляет информацию о структуре графа и расположении кода, что выходит за рамки возможностей tf.print() .
Другой API, который можно использовать для отладки проблем, связанных с ∞ и NaN, — это tf.debugging.enable_check_numerics() . В отличие от enable_dump_debug_info() , enable_check_numerics() не сохраняет отладочную информацию на диске. Вместо этого он просто отслеживает ∞ и NaN во время выполнения TensorFlow и выдает ошибки с местоположением исходного кода, как только какая-либо операция генерирует такие неверные числовые значения. Он имеет меньшие издержки производительности по сравнению с enable_dump_debug_info() , но не позволяет полностью отслеживать историю выполнения программы и не имеет графического пользовательского интерфейса, такого как Debugger V2.