
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
API tf.data позволяет создавать сложные конвейеры ввода из простых, повторно используемых частей. Например, конвейер для модели изображения может собирать данные из файлов в распределенной файловой системе, применять случайные возмущения к каждому изображению и объединять случайно выбранные изображения в пакет для обучения. Конвейер для текстовой модели может включать в себя извлечение символов из необработанных текстовых данных, преобразование их во внедренные идентификаторы с помощью таблицы поиска и объединение в пакеты последовательностей различной длины. API tf.data позволяет обрабатывать большие объемы данных, считывать данные из разных форматов и выполнять сложные преобразования.
API tf.data представляет абстракцию tf.data.Dataset , представляющую последовательность элементов, в которой каждый элемент состоит из одного или нескольких компонентов. Например, в конвейере изображений элемент может быть одним обучающим примером с парой тензорных компонентов, представляющих изображение и его метку.
Существует два различных способа создания набора данных:
Источник данных создает
Datasetиз данных, хранящихся в памяти или в одном или нескольких файлах.Преобразование данных создает набор данных из одного или нескольких объектов
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Базовая механика
Чтобы создать конвейер ввода, необходимо начать с источника данных. Например, чтобы создать Dataset из данных в памяти, вы можете использовать tf.data.Dataset.from_tensors() или tf.data.Dataset.from_tensor_slices() . В качестве альтернативы, если ваши входные данные хранятся в файле в рекомендуемом формате TFRecord, вы можете использовать tf.data.TFRecordDataset() .
Получив объект Dataset , вы можете преобразовать его в новый Dataset , объединив вызовы методов в объекте tf.data.Dataset . Например, вы можете применять преобразования для каждого элемента, такие как Dataset.map() , и многоэлементные преобразования, такие как Dataset.batch() . См. документацию для tf.data.Dataset для получения полного списка преобразований.
Объект Dataset является итерируемым Python. Это позволяет потреблять его элементы с помощью цикла for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Или явно создав итератор Python с помощью iter и используя его элементы с помощью next :
it = iter(dataset)
print(next(it).numpy())
8
Кроме того, элементы набора данных можно использовать с помощью преобразования reduce , которое уменьшает все элементы для получения единого результата. В следующем примере показано, как использовать преобразование reduce для вычисления суммы набора данных целых чисел.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Структура набора данных
Набор данных создает последовательность элементов , где каждый элемент представляет собой одинаковую (вложенную) структуру компонентов . Отдельные компоненты структуры могут быть любого типа, представляемого tf.TypeSpec , включая tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray или tf.data.Dataset .
Конструкции Python, которые можно использовать для выражения (вложенной) структуры элементов, включают tuple , dict , NamedTuple и OrderedDict . В частности, list не является допустимой конструкцией для выражения структуры элементов набора данных. Это связано с тем, что первые пользователи tf.data были сильно обеспокоены тем, что входные list (например, переданные в tf.data.Dataset.from_tensors ) автоматически упаковывались в виде тензоров, а выходные данные list (например, возвращаемые значения определяемых пользователем функций) приводились в tuple . Как следствие, если вы хотите, чтобы ввод list рассматривался как структура, вам необходимо преобразовать его в tuple , а если вы хотите, чтобы вывод list был одним компонентом, вам необходимо явно упаковать его с помощью tf.stack .
Свойство Dataset.element_spec позволяет проверить тип каждого компонента элемента. Свойство возвращает вложенную структуру объектов tf.TypeSpec , соответствующую структуре элемента, который может быть отдельным компонентом, кортежем компонентов или вложенным кортежем компонентов. Например:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Преобразования Dataset поддерживают наборы данных любой структуры. При использовании Dataset.map() и Dataset.filter() , которые применяют функцию к каждому элементу, структура элемента определяет аргументы функции:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[8 2 4 4 4 9 9 1 5 4] [8 9 8 6 5 8 8 1 3 7] [3 7 8 8 5 9 9 4 5 5] [4 4 9 7 6 4 5 9 4 4]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Чтение входных данных
Использование массивов NumPy
Дополнительные примеры см. в разделе Загрузка массивов NumPy .
Если все ваши входные данные помещаются в память, самый простой способ создать из них Dataset — преобразовать их в объекты tf.Tensor и использовать Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Использование генераторов Python
Другим распространенным источником данных, который можно легко использовать как tf.data.Dataset , является генератор python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Конструктор Dataset.from_generator преобразует генератор Python в полнофункциональный tf.data.Dataset .
Конструктор принимает вызываемый объект в качестве входных данных, а не итератор. Это позволяет ему перезапускать генератор, когда он достигает конца. Он принимает необязательный аргумент args , который передается в качестве аргументов вызываемого объекта.
Аргумент output_types необходим, потому что tf.data строит tf.Graph внутри, а ребрам графа требуется tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
Аргумент output_shapes не требуется , но настоятельно рекомендуется, так как многие операции тензорного потока не поддерживают тензоры с неизвестным рангом. Если длина конкретной оси неизвестна или является переменной, установите ее как None в output_shapes .
Также важно отметить, что output_shapes и output_types следуют тем же правилам вложенности, что и другие методы набора данных.
Вот пример генератора, который демонстрирует оба аспекта, он возвращает кортежи массивов, где второй массив — это вектор неизвестной длины.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [-0.507 0.825 -0.9698 1.0904 1.1761 -0.9112 -0.0045 -0.8401 -0.2676] 1 : [ 0.621 1.5843 -0.4695] 2 : [] 3 : [-0.5107] 4 : [-1.6201 -1.8984 0.6082 1.8105 -2.368 0.4142 0.2167] 5 : [0.9673] 6 : []
Первый вывод — int32 , второй — float32 .
Первый элемент — это скаляр формы () , а второй — вектор неизвестной длины формы (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Теперь его можно использовать как обычный tf.data.Dataset . Обратите внимание, что при пакетной обработке набора данных с переменной формой вам необходимо использовать Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[12 19 5 10 6 15 3 20 21 17] [[ 0. 0. 0. 0. 0. 0. 0. 0. 0. ] [ 0.483 -0.3454 0. 0. 0. 0. 0. 0. 0. ] [ 0.0869 -1.5191 -1.9252 -0.6955 0.3542 1.7332 -0.084 0. 0. ] [-1.0211 0.2689 -0.4805 -0.6755 0.6886 0.8313 0. 0. 0. ] [ 0.5442 0.0539 1.4572 2.7313 -0.0386 1.2614 -0.0811 -0.5399 0. ] [ 1.6386 -0.8331 -1.4722 0.0403 1.3425 -0.3833 -2.1371 0.901 0.9595] [ 0.1002 0.0705 -0.4418 0.0806 -1.4263 -0.1352 0. 0. 0. ] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. ] [-0.8525 0.1426 -0.0869 2.163 -0.3666 0. 0. 0. 0. ] [ 0.6796 -0.824 -0.0424 0. 0. 0. 0. 0. 0. ]]
Для более реалистичного примера попробуйте обернуть preprocessing.image.ImageDataGenerator как tf.data.Dataset .
Сначала загрузите данные:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 1s 0us/step 228827136/228813984 [==============================] - 1s 0us/step
Создайте image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Использование данных TFRecord
См. Загрузка TFRecords для полного примера.
API tf.data поддерживает различные форматы файлов, поэтому вы можете обрабатывать большие наборы данных, которые не помещаются в памяти. Например, формат файла TFRecord — это простой ориентированный на записи двоичный формат, который многие приложения TensorFlow используют для обучающих данных. Класс tf.data.TFRecordDataset позволяет выполнять потоковую передачу содержимого одного или нескольких файлов TFRecord как часть входного конвейера.
Вот пример использования тестового файла из французских дорожных знаков (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 0s 0us/step 7913472/7904079 [==============================] - 0s 0us/step
Аргумент filenames для инициализатора TFRecordDataset может быть строкой, списком строк или tf.Tensor строк. Поэтому, если у вас есть два набора файлов для обучения и проверки, вы можете создать фабричный метод, который создает набор данных, принимая имена файлов в качестве входного аргумента:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Многие проекты TensorFlow используют сериализованные записи tf.train.Example в своих файлах TFRecord. Их необходимо расшифровать, прежде чем их можно будет проверить:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Использование текстовых данных
См. « Загрузка текста» для полного примера.
Многие наборы данных распространяются в виде одного или нескольких текстовых файлов. tf.data.TextLineDataset предоставляет простой способ извлечения строк из одного или нескольких текстовых файлов. Учитывая одно или несколько имен файлов, TextLineDataset создаст один элемент со строковым значением на строку этих файлов.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Вот первые несколько строк первого файла:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Чтобы чередовать строки между файлами, используйте Dataset.interleave . Это упрощает перемешивание файлов. Вот первая, вторая и третья строки из каждого перевода:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
По умолчанию TextLineDataset выдает каждую строку каждого файла, что может быть нежелательно, например, если файл начинается со строки заголовка или содержит комментарии. Эти строки можно удалить с помощью Dataset.skip() или Dataset.filter() . Здесь вы пропускаете первую строку, а затем фильтруете, чтобы найти только выживших.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Использование данных CSV
Дополнительные примеры см. в разделах « Загрузка файлов CSV» и «Загрузка фреймов данных Pandas» .
Формат файла CSV является популярным форматом для хранения табличных данных в виде простого текста.
Например:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Если ваши данные помещаются в память, тот же метод Dataset.from_tensor_slices работает со словарями, что позволяет легко импортировать эти данные:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Более масштабируемый подход — загрузка с диска по мере необходимости.
Модуль tf.data предоставляет методы для извлечения записей из одного или нескольких файлов CSV, соответствующих RFC 4180 .
Функция experimental.make_csv_dataset — это высокоуровневый интерфейс для чтения наборов CSV-файлов. Он поддерживает вывод типа столбца и многие другие функции, такие как пакетная обработка и перетасовка, для упрощения использования.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 1 0] features: 'sex' : [b'female' b'male' b'female' b'male'] 'age' : [ 4. 50. 28. 28.] 'n_siblings_spouses': [0 0 0 1] 'parch' : [2 0 0 0] 'fare' : [22.025 13. 7.75 16.1 ] 'class' : [b'Third' b'Second' b'Third' b'Third'] 'deck' : [b'unknown' b'unknown' b'unknown' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Queenstown' b'Southampton'] 'alone' : [b'n' b'y' b'y' b'n']
Вы можете использовать аргумент select_columns , если вам нужно только подмножество столбцов.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 1 1 1] 'fare' : [ 12. 108.9 23. 26. ] 'class' : [b'Second' b'First' b'Second' b'Second']
Существует также experimental.CsvDataset класс более низкого уровня. CsvDataset, который обеспечивает более детальное управление. Он не поддерживает вывод типа столбца. Вместо этого вы должны указать тип каждого столбца.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Если некоторые столбцы пусты, этот низкоуровневый интерфейс позволяет указать значения по умолчанию вместо типов столбцов.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
По умолчанию CsvDataset выдает каждый столбец каждой строки файла, что может быть нежелательно, например, если файл начинается со строки заголовка, которую следует игнорировать, или если некоторые столбцы не требуются во входных данных. Эти строки и поля можно удалить с помощью аргументов header и select_cols соответственно.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Использование наборов файлов
Существует множество наборов данных, распространяемых в виде набора файлов, где каждый файл является примером.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
Корневой каталог содержит каталог для каждого класса:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
Файлы в каждом каталоге класса являются примерами:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6145005439_ef6e07f9c6_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/5762590366_5cf7a32b87_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/10443973_aeb97513fc_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/roses/921138131_9e1393eb2b_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/3730618647_5725c692c3_m.jpg'
Прочитайте данные с помощью функции tf.io.read_file и извлеките метку из пути, возвращая пары (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xdb\x00C\x00\x03\x02\x02\x03\x02\x02\x03\x03\x03\x03\x04\x03\x03\x04\x05\x08\x05\x05\x04\x04\x05\n\x07\x07\x06\x08\x0c\n\x0c\x0c\x0b\n\x0b\x0b\r\x0e\x12\x10\r\x0e\x11\x0e\x0b\x0b\x10\x16\x10\x11\x13\x14\x15\x15\x15\x0c\x0f\x17\x18\x16\x14\x18\x12\x14\x15\x14\xff\xdb\x00C\x01\x03\x04\x04\x05\x04\x05' b'dandelion'
Пакетная обработка элементов набора данных
Простое дозирование
Простейшая форма пакетной обработки объединяет n последовательных элементов набора данных в один элемент. Преобразование Dataset.batch() делает именно это с теми же ограничениями, что и оператор tf.stack() , применяемый к каждому компоненту элементов: т. е. для каждого компонента i все элементы должны иметь тензор точно такой же формы.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
В то время как tf.data пытается распространить информацию о форме, настройки Dataset.batch по умолчанию приводят к неизвестному размеру пакета, поскольку последний пакет может быть неполным. Обратите внимание на None в форме:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Используйте аргумент drop_remainder , чтобы игнорировать этот последний пакет и получить полное распространение формы:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Пакетирование тензоров с отступами
Приведенный выше рецепт работает для тензоров одинакового размера. Однако многие модели (например, модели последовательностей) работают с входными данными, которые могут иметь разный размер (например, последовательности разной длины). Чтобы справиться с этим случаем, преобразование Dataset.padded_batch позволяет вам группировать тензоры различной формы, указывая одно или несколько измерений, в которых они могут быть дополнены.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
Преобразование Dataset.padded_batch позволяет вам установить разные отступы для каждого измерения каждого компонента, и это может быть переменная длина (обозначенная None в приведенном выше примере) или постоянная длина. Также возможно переопределить значение заполнения, которое по умолчанию равно 0.
Рабочие процессы обучения
Обработка нескольких эпох
API tf.data предлагает два основных способа обработки нескольких эпох одних и тех же данных.
Самый простой способ перебрать набор данных в несколько эпох — использовать преобразование Dataset.repeat() . Во-первых, создайте набор титанических данных:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
Применение преобразования Dataset.repeat() без аргументов приведет к бесконечному повторению ввода.
Преобразование Dataset.repeat объединяет свои аргументы, не сигнализируя о конце одной эпохи и начале следующей эпохи. Из-за этого Dataset.batch , примененный после Dataset.repeat , даст пакеты, которые охватывают границы эпохи:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
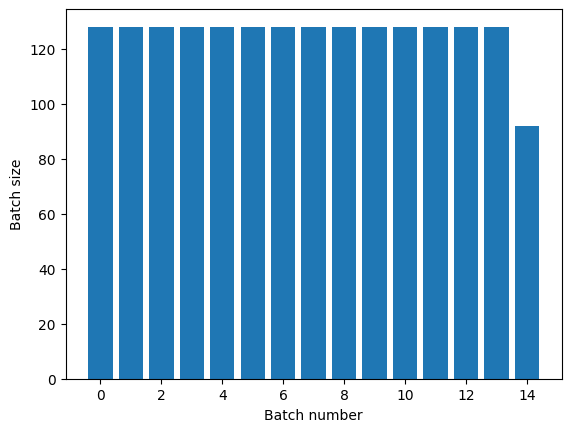
Если вам нужно четкое разделение эпох, поместите Dataset.batch перед повтором:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
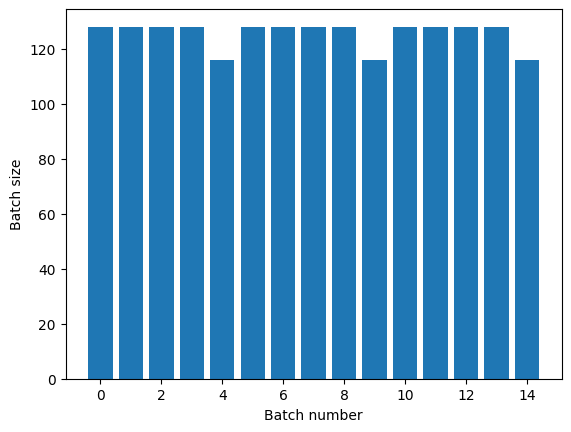
Если вы хотите выполнять пользовательские вычисления (например, для сбора статистики) в конце каждой эпохи, проще всего перезапустить итерацию набора данных в каждой эпохе:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Случайное перемешивание входных данных
Преобразование Dataset.shuffle() поддерживает буфер фиксированного размера и случайным образом выбирает следующий элемент из этого буфера.
Добавьте индекс в набор данных, чтобы увидеть эффект:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Поскольку buffer_size равен 100, а размер пакета равен 20, первый пакет не содержит элементов с индексом больше 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[26 31 11 82 21 52 98 7 79 60 56 81 46 28 8 74 44 16 1 3]
Как и в случае с Dataset.batch , порядок относительно Dataset.repeat имеет значение.
Dataset.shuffle не сигнализирует об окончании эпохи, пока буфер перемешивания не станет пустым. Таким образом, перетасовка, помещенная перед повтором, покажет каждый элемент одной эпохи, прежде чем перейти к следующей:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [539 272 610 626 515 615 304 499 547 580] [565 367 511 513 595 589 576 584 415 588] [567 463 608 554 619 596 523 573] [ 88 94 72 59 92 4 69 100 67 3] [ 57 16 93 38 45 104 52 90 26 114]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f26501d9b10>
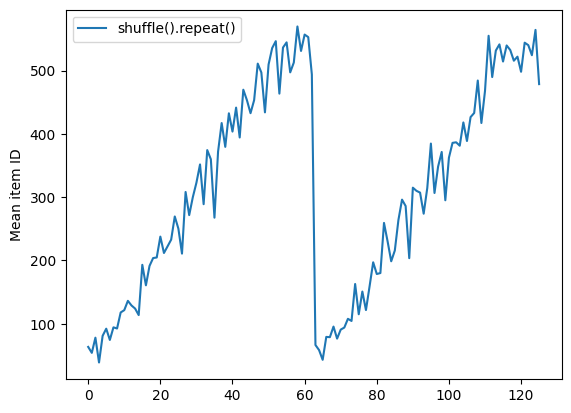
Но повтор перед тасовкой смешивает границы эпох вместе:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 19 603 478 559 480 611 516 3 402 30] [596 554 495 586 564 571 510 477 583 576] [ 24 508 419 616 474 515 26 1 31 38] [562 27 592 461 456 32 53 46 509 48] [ 8 578 21 16 57 20 621 608 580 58] [ 54 42 62 7 69 594 622 35 421 41] [605 28 11 13 574 2 66 67 560 72] [ 61 617 36 44 5 51 77 537 78 6] [ 63 607 43 56 604 530 91 593 88 104] [102 557 539 60 115 52 582 68 81 47] [ 74 534 83 97 119 80 626 114 577 563] [130 55 121 316 40 136 90 111 9 14] [107 470 106 64 122 615 113 129 18 50] [ 98 92 45 148 327 29 120 151 381 112] [159 511 455 127 153 86 619 128 100 117]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f25fc63bf10>
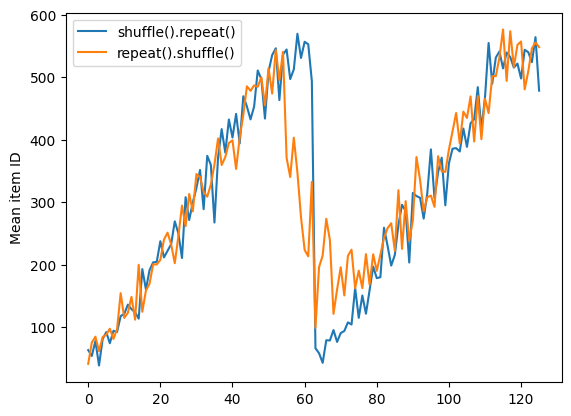
Предварительная обработка данных
Преобразование Dataset.map(f) создает новый набор данных, применяя заданную функцию f к каждому элементу входного набора данных. Он основан на функции map() , которая обычно применяется к спискам (и другим структурам) в функциональных языках программирования. Функция f принимает объекты tf.Tensor , которые представляют один элемент во входных данных, и возвращает объекты tf.Tensor , которые будут представлять один элемент в новом наборе данных. Его реализация использует стандартные операции TensorFlow для преобразования одного элемента в другой.
В этом разделе рассматриваются распространенные примеры использования Dataset.map() .
Декодирование данных изображения и изменение его размера
При обучении нейронной сети на данных реальных изображений часто необходимо преобразовывать изображения разных размеров в общий размер, чтобы их можно было объединить в пакеты фиксированного размера.
Перестройте набор данных с именами файлов цветов:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Напишите функцию, которая манипулирует элементами набора данных.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Проверьте, что это работает.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Сопоставьте его с набором данных.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Применение произвольной логики Python
По соображениям производительности по возможности используйте операции TensorFlow для предварительной обработки данных. Однако иногда полезно вызывать внешние библиотеки Python при анализе входных данных. Вы можете использовать операцию tf.py_function() Dataset.map() в преобразовании Dataset.map().
Например, если вы хотите применить случайное вращение, модуль tf.image имеет только tf.image.rot90 , что не очень полезно для увеличения изображения.
Чтобы продемонстрировать tf.py_function , попробуйте вместо этого использовать функцию scipy.ndimage.rotate :
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Чтобы использовать эту функцию с Dataset.map , применяются те же предостережения, что и с Dataset.from_generator , вам необходимо описать возвращаемые формы и типы при применении функции:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Разбор сообщений буфера протокола tf.Example
Многие входные конвейеры извлекают сообщения буфера протокола tf.train.Example из формата TFRecord. Каждая запись tf.train.Example содержит одну или несколько «функций», и конвейер ввода обычно преобразует эти функции в тензоры.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Вы можете работать с tf.train.Example вне tf.data.Dataset , чтобы понять данные:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Окно временных рядов
Пример непрерывного временного ряда см. в разделе Прогнозирование временных рядов .
Данные временных рядов часто организованы с неповрежденной временной осью.
Используйте простой Dataset.range , чтобы продемонстрировать:
range_ds = tf.data.Dataset.range(100000)
Как правило, модели, основанные на такого рода данных, нуждаются в непрерывном интервале времени.
Самым простым подходом было бы группировать данные:
Использование batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Или, чтобы сделать плотные прогнозы на один шаг вперед, вы можете сдвинуть функции и метки на один шаг относительно друг друга:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Чтобы предсказать все окно вместо фиксированного смещения, вы можете разделить пакеты на две части:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Чтобы допустить некоторое совпадение между функциями одного пакета и метками другого, используйте Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Использование window
Хотя использование Dataset.batch работает, бывают ситуации, когда вам может потребоваться более точный контроль. Метод Dataset.window дает вам полный контроль, но требует осторожности: он возвращает Dataset of Datasets . Подробнее см. Структура набора данных.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
Метод Dataset.flat_map может взять набор наборов данных и объединить его в один набор данных:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
Почти во всех случаях вы захотите .batch набор данных:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Теперь вы можете видеть, что аргумент shift определяет, на сколько перемещается каждое окно.
Собрав это вместе, вы можете написать эту функцию:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Затем легко извлечь метки, как и раньше:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Повторная выборка
При работе с набором данных, который сильно несбалансирован по классам, вам может потребоваться повторная выборка набора данных. tf.data предоставляет для этого два метода. Набор данных о мошенничестве с кредитными картами является хорошим примером такого рода проблем.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 3s 0us/step 69165056/69155632 [==============================] - 3s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Теперь проверьте распределение классов, оно сильно перекошено:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9951 0.0049]
Обычный подход к обучению с несбалансированным набором данных заключается в его балансировке. tf.data включает несколько методов, которые обеспечивают этот рабочий процесс:
Выборка наборов данных
Один из подходов к повторной выборке набора данных — использовать sample_from_datasets . Это более применимо, когда у вас есть отдельный data.Dataset для каждого класса.
Здесь просто используйте фильтр, чтобы сгенерировать их из данных о мошенничестве с кредитными картами:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Чтобы использовать tf.data.Dataset.sample_from_datasets , передайте наборы данных и вес для каждого:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Теперь набор данных создает примеры каждого класса с вероятностью 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[0 1 0 0 1 0 1 1 0 0] [0 1 0 1 0 0 1 0 1 0] [1 0 0 0 0 1 0 1 0 1] [1 0 0 0 1 1 0 0 1 1] [0 1 0 1 0 1 0 1 1 1] [1 0 0 0 0 1 0 0 0 1] [0 1 0 0 1 1 0 0 0 0] [0 0 0 0 0 0 1 0 1 1] [0 1 1 1 0 1 0 1 0 1] [0 0 1 1 0 0 1 0 1 1]
Отклонение повторной выборки
Одна проблема с описанным выше подходом Dataset.sample_from_datasets заключается в том, что для каждого класса требуется отдельный tf.data.Dataset . Вы можете использовать Dataset.filter для создания этих двух наборов данных, но это приведет к тому, что все данные будут загружены дважды.
Метод data.Dataset.rejection_resample можно применять к набору данных для его повторной балансировки, загружая его только один раз. Элементы будут удалены из набора данных для достижения баланса.
data.Dataset.rejection_resample принимает аргумент class_func . Этот class_func применяется к каждому элементу набора данных и используется для определения того, к какому классу принадлежит пример для целей балансировки.
Цель здесь состоит в том, чтобы сбалансировать распределение меток, а элементы creditcard_ds уже являются парами (features, label) . Таким образом, class_func просто должен вернуть эти метки:
def class_func(features, label):
return label
Метод повторной выборки работает с отдельными примерами, поэтому в этом случае перед применением этого метода необходимо unbatch набор данных.
Метод требует целевого распределения и, возможно, исходной оценки распределения в качестве входных данных.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
Метод rejection_resample возвращает пары (class, example) где class является результатом class_func . В этом случае example уже был парой (feature, label) , поэтому используйте map , чтобы удалить дополнительную копию меток:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Теперь набор данных создает примеры каждого класса с вероятностью 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] Proportion of examples rejected by sampler is high: [0.995117188][0.995117188 0.0048828125][0 1] [0 1 1 0 1 0 0 0 0 1] [1 0 1 0 0 1 1 1 1 1] [1 1 0 0 1 0 0 0 1 1] [1 0 0 1 1 1 1 1 0 0] [0 1 0 1 0 0 0 1 0 0] [0 0 1 0 0 1 1 0 1 1] [0 1 1 1 0 1 0 0 1 0] [1 0 0 1 0 0 0 1 1 1] [0 1 1 1 1 0 0 0 1 1] [1 0 0 1 0 1 0 0 1 1]
Итератор
Tensorflow поддерживает получение контрольных точек , поэтому при перезапуске процесса обучения он может восстановить последнюю контрольную точку, чтобы восстановить большую часть своего прогресса. В дополнение к проверке переменных модели вы также можете проверить ход выполнения итератора набора данных. Это может быть полезно, если у вас большой набор данных и вы не хотите запускать набор данных с самого начала при каждом перезапуске. Обратите внимание, однако, что контрольные точки итератора могут быть большими, поскольку такие преобразования, как shuffle и prefetch , требуют элементов буферизации внутри итератора.
Чтобы включить итератор в контрольную точку, передайте итератор конструктору tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Использование tf.data с tf.keras
API tf.keras упрощает многие аспекты создания и выполнения моделей машинного обучения. Его API- .fit() .evaluate() и .predict() поддерживают наборы данных в качестве входных данных. Вот быстрый набор данных и настройка модели:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Передача набора данных пар (feature, label) — это все, что нужно для Model.fit и Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.6053 - accuracy: 0.7952 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4620 - accuracy: 0.8425 <keras.callbacks.History at 0x7f25fc2e4e10>
Если вы передаете бесконечный набор данных, например, вызывая Dataset.repeat() , вам просто нужно также передать аргумент steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4028 - accuracy: 0.8516 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4591 - accuracy: 0.8344 <keras.callbacks.History at 0x7f25fc04cad0>
Для оценки вы можете пройти ряд шагов оценки:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4340 - accuracy: 0.8518 Loss : 0.43400809168815613 Accuracy : 0.8517833352088928
Для длинных наборов данных установите количество шагов для оценки:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.3548 - accuracy: 0.8750 Loss : 0.3548365533351898 Accuracy : 0.875
Метки не требуются при вызове Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Но метки игнорируются, если вы передаете набор данных, содержащий их:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)