
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
В этом руководстве представлены примеры использования данных CSV с TensorFlow.
В этом есть две основные части:
- Загрузка данных с диска
- Предварительно переработав его в форму, пригодную для тренировок.
В этом руководстве основное внимание уделяется загрузке и дается несколько быстрых примеров предварительной обработки. Учебное пособие, посвященное аспекту предварительной обработки, см. в руководстве и учебном пособии по слоям предварительной обработки .
Настраивать
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
Данные в памяти
Для любого небольшого набора данных CSV самый простой способ обучить на нем модель TensorFlow — загрузить его в память в виде кадра данных pandas или массива NumPy.
Относительно простой пример — набор данных с морским ушком.
- Набор данных небольшой.
- Все входные функции представляют собой значения с плавающей запятой ограниченного диапазона.
Вот как загрузить данные в Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Набор данных содержит набор измерений морского ушка , разновидности морской улитки.

«Морское ушко» (автор: Ники Дуган Пог , CC BY-SA 2.0)
Номинальная задача для этого набора данных — предсказать возраст по другим измерениям, поэтому разделите функции и метки для обучения:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Для этого набора данных вы будете обрабатывать все функции одинаково. Упакуйте функции в один массив NumPy.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Затем сделайте регрессионную модель, предсказывающую возраст. Поскольку имеется только один входной тензор, здесь достаточно модели keras.Sequential .
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Чтобы обучить эту модель, передайте функции и метки в Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Вы только что увидели самый простой способ обучения модели с использованием данных CSV. Далее вы узнаете, как применять предварительную обработку для нормализации числовых столбцов.
Базовая предварительная обработка
Хорошей практикой является нормализация входных данных для вашей модели. Слои предварительной обработки Keras предоставляют удобный способ встроить эту нормализацию в вашу модель.
Слой будет предварительно вычислять среднее значение и дисперсию каждого столбца и использовать их для нормализации данных.
Сначала вы создаете слой:
normalize = layers.Normalization()
Затем вы используете метод Normalization.adapt() , чтобы адаптировать уровень нормализации к вашим данным.
normalize.adapt(abalone_features)
Затем используйте слой нормализации в своей модели:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Смешанные типы данных
Набор данных «Титаник» содержит информацию о пассажирах Титаника. Номинальная задача в этом наборе данных — предсказать, кто выжил.

Изображение из Викимедиа
{kind=link}
Необработанные данные можно легко загрузить как Pandas DataFrame , но их нельзя сразу использовать в качестве входных данных для модели TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Из-за разных типов данных и диапазонов вы не можете просто сложить функции в массив NumPy и передать его в модель keras.Sequential . Каждую колонку нужно обрабатывать отдельно.
В качестве одного из вариантов вы можете предварительно обработать свои данные в автономном режиме (с помощью любого инструмента, который вам нравится), чтобы преобразовать категориальные столбцы в числовые столбцы, а затем передать обработанный вывод в вашу модель TensorFlow. Недостатком этого подхода является то, что если вы сохраняете и экспортируете свою модель, предварительная обработка не сохраняется вместе с ней. Слои предварительной обработки Keras позволяют избежать этой проблемы, потому что они являются частью модели.
В этом примере вы создадите модель, реализующую логику предварительной обработки с помощью функционального API Keras . Вы также можете сделать это, создав подкласс .
Функциональный API работает с «символическими» тензорами. Нормальные «нетерпеливые» тензоры имеют значение. Напротив, эти «символические» тензоры этого не делают. Вместо этого они отслеживают, какие операции с ними выполняются, и создают представление вычислений, которое вы можете запустить позже. Вот краткий пример:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Чтобы построить модель предварительной обработки, начните с создания набора символических объектов keras.Input , соответствующих именам и типам данных столбцов CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Первым шагом в вашей логике предварительной обработки является объединение числовых входных данных вместе и прогон их через слой нормализации:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Соберите все символические результаты предварительной обработки, чтобы потом соединить их.
preprocessed_inputs = [all_numeric_inputs]
Для строковых входных данных используйте функцию tf.keras.layers.StringLookup для сопоставления строк с целочисленными индексами в словаре. Затем используйте tf.keras.layers.CategoryEncoding , чтобы преобразовать индексы в данные float32 , подходящие для модели.
Настройки по умолчанию для слоя tf.keras.layers.CategoryEncoding создают однократный вектор для каждого входа. layers.Embedding также будет работать. См. руководство и учебник по слоям предварительной обработки для получения дополнительной информации по этой теме.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
С помощью набора inputs и processed_inputs вы можете объединить все предварительно обработанные входные данные вместе и построить модель, которая обрабатывает предварительную обработку:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
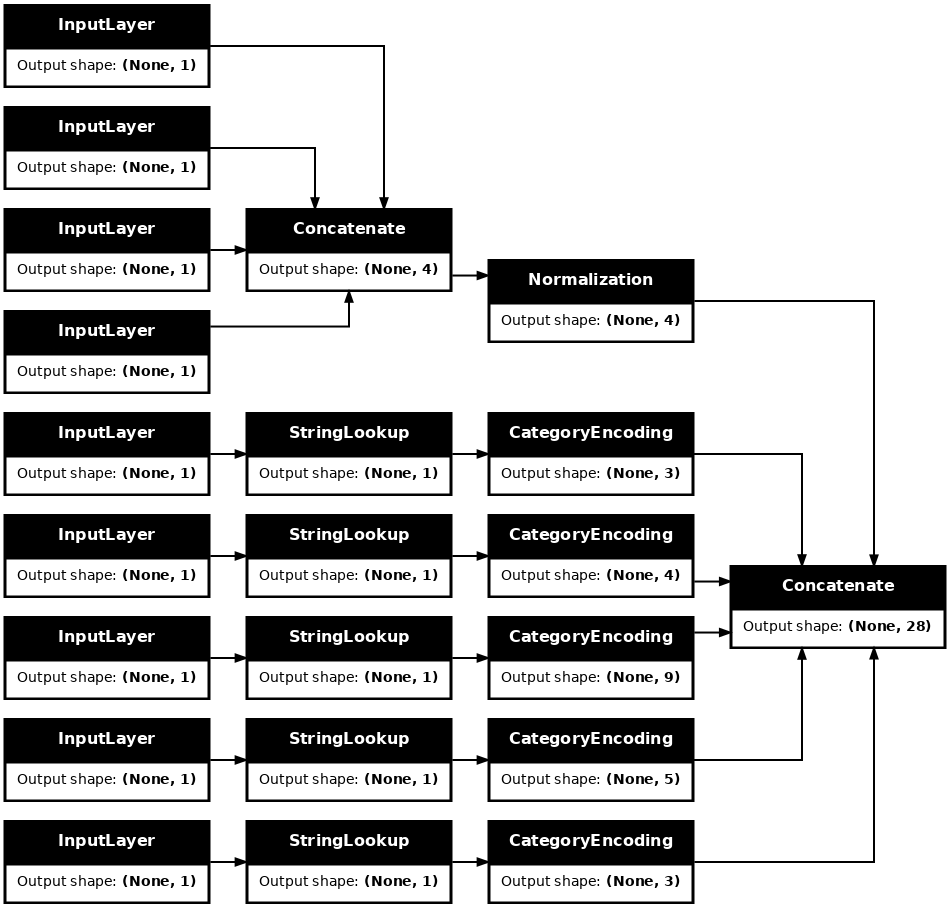
Эта model содержит только входную предварительную обработку. Вы можете запустить его, чтобы увидеть, что он делает с вашими данными. Модели Keras не преобразуют автоматически Pandas DataFrames , потому что неясно, следует ли преобразовывать их в один тензор или в словарь тензоров. Итак, преобразуйте его в словарь тензоров:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Вырежьте первый обучающий пример и передайте его в эту модель предварительной обработки, вы увидите, что числовые функции и однозначные строки объединены вместе:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Теперь постройте модель поверх этого:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Когда вы обучаете модель, передайте словарь функций как x и метку как y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Поскольку предварительная обработка является частью модели, вы можете сохранить модель и перезагрузить ее в другом месте и получить идентичные результаты:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Использование tf.data
В предыдущем разделе вы полагались на встроенные в модель функции перетасовки и пакетной обработки данных при обучении модели.
Если вам нужен больший контроль над конвейером входных данных или вам нужно использовать данные, которые не помещаются в память: используйте tf.data .
Дополнительные примеры см. в руководстве по tf.data .
Включено в данных памяти
В качестве первого примера применения tf.data к данным CSV рассмотрим следующий код, который вручную нарезает словарь функций из предыдущего раздела. Для каждого индекса он берет этот индекс для каждой функции:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Запустите это и распечатайте первый пример:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
Самый простой tf.data.Dataset в загрузчике данных в памяти — это конструктор Dataset.from_tensor_slices . Это возвращает tf.data.Dataset , который реализует обобщенную версию вышеуказанной функции slices в TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Вы можете перебирать tf.data.Dataset , как и любой другой итерируемый Python:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
Функция from_tensor_slices может обрабатывать любую структуру вложенных словарей или кортежей. Следующий код создает набор данных из пар (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Чтобы обучить модель с использованием этого Dataset , вам нужно как минимум shuffle и batch данные.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Вместо передачи features и labels в Model.fit вы передаете набор данных:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Из одного файла
До сих пор это руководство работало с данными в памяти. tf.data — это хорошо масштабируемый набор инструментов для построения конвейеров данных, который предоставляет несколько функций для загрузки CSV-файлов.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Теперь прочитайте данные CSV из файла и создайте tf.data.Dataset .
(Полную документацию см. tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Эта функция включает в себя множество удобных функций, поэтому с данными легко работать. Это включает в себя:
- Использование заголовков столбцов в качестве ключей словаря.
- Автоматическое определение типа каждого столбца.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Он также может распаковывать данные на лету. Вот сжатый с помощью gzip файл CSV, содержащий набор данных о трафике между штатами.

Изображение из Викимедиа
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Задайте аргумент compression_type для чтения непосредственно из сжатого файла:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Кэширование
Есть некоторые накладные расходы на анализ данных csv. Для небольших моделей это может быть узким местом в обучении.
В зависимости от вашего варианта использования может быть хорошей идеей использовать Dataset.cache или data.experimental.snapshot , чтобы данные csv анализировались только в первую эпоху.
Основное различие между методами cache и snapshot заключается в том, что файлы cache могут использоваться только создавшим их процессом TensorFlow, но файлы snapshot могут быть прочитаны другими процессами.
Например, итерация traffic_volume_csv_gz_ds 20 раз занимает ~15 секунд без кэширования или ~2 секунды с кэшированием.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Если загрузка данных замедляется из-за загрузки CSV-файлов, а cache и snapshot недостаточно для вашего варианта использования, рассмотрите возможность перекодирования данных в более оптимизированный формат.
Несколько файлов
Все примеры в этом разделе можно легко выполнить без tf.data . Одно место, где tf.data действительно может упростить ситуацию, — это работа с коллекциями файлов.
Например, набор данных изображений шрифтов символов распространяется в виде набора CSV-файлов, по одному на каждый шрифт.

Изображение Willi Heidelbach с сайта Pixabay
Загрузите набор данных и посмотрите на файлы внутри:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
При работе с кучей файлов вы можете передать file_pattern в стиле experimental.make_csv_dataset в функцию Experiment.make_csv_dataset. Порядок файлов перемешивается каждую итерацию.
Используйте аргумент num_parallel_reads , чтобы указать, сколько файлов читаются параллельно и чередуются вместе.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
В этих CSV-файлах изображения сведены в одну строку. Имена столбцов имеют формат r{row}c{column} . Вот первая партия:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Необязательно: поля упаковки
Вы, вероятно, не хотите работать с каждым пикселем в отдельных столбцах, подобных этому. Прежде чем пытаться использовать этот набор данных, обязательно упакуйте пиксели в тензор изображения.
Вот код, который анализирует имена столбцов для создания изображений для каждого примера:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Примените эту функцию к каждой партии в наборе данных:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Постройте полученные изображения:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Функции нижнего уровня
До сих пор это руководство было сосредоточено на утилитах самого высокого уровня для чтения данных csv. Есть еще два API, которые могут быть полезны опытным пользователям, если ваш вариант использования не соответствует базовым шаблонам.
-
tf.io.decode_csv— функция для разбора строк текста в список тензоров столбцов CSV. -
tf.data.experimental.CsvDataset— конструктор набора данных csv более низкого уровня.
В этом разделе воссоздаются функции, предоставляемые make_csv_dataset , чтобы продемонстрировать, как можно использовать эти функции более низкого уровня.
tf.io.decode_csv
Эта функция декодирует строку или список строк в список столбцов.
В отличие от make_csv_dataset эта функция не пытается угадать типы данных столбца. Вы указываете типы столбцов, предоставляя список record_defaults , содержащий значение правильного типа для каждого столбца.
Чтобы прочитать данные Титаника в виде строк с помощью decode_csv , вы должны сказать:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Чтобы проанализировать их с их фактическими типами, создайте список значений по умолчанию для record_defaults соответствующих типов:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
Класс tf.data.experimental.CsvDataset предоставляет минимальный интерфейс Dataset CSV без удобных функций функции make_csv_dataset : синтаксический анализ заголовков столбцов, определение типа столбцов, автоматическое перемешивание, чередование файлов.
Этот конструктор использует record_defaults так же, как io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Приведенный выше код в основном эквивалентен:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Несколько файлов
Чтобы проанализировать набор данных шрифтов с помощью experimental.CsvDataset , вам сначала нужно определить типы столбцов для record_defaults . Начните с проверки первой строки одного файла:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Только первые два поля являются строками, остальные представляют собой целые числа или числа с плавающей запятой, и вы можете получить общее количество функций, посчитав запятые:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Конструктор CsvDatasaet может принимать список входных файлов, но считывает их последовательно. Первый файл в списке CSV — AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Поэтому, когда вы передаете список файлов в CsvDataaset , сначала считываются записи из AGENCY.csv :
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Чтобы чередовать несколько файлов, используйте Dataset.interleave .
Вот исходный набор данных, содержащий имена CSV-файлов:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Это перемешивает имена файлов каждую эпоху:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
Метод interleave принимает функцию map_func , которая создает дочерний Dataset для каждого элемента родительского Dataset .
Здесь вы хотите создать CsvDataset из каждого элемента набора данных файлов:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset , возвращаемый чередованием, возвращает элементы путем циклического перебора ряда дочерних Dataset . Обратите внимание на то, как набор данных циклически циклически cycle_length=3 трех файлов шрифтов:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Представление
Ранее было отмечено, что io.decode_csv более эффективен при работе с пакетом строк.
Можно воспользоваться этим фактом при использовании больших размеров пакетов, чтобы повысить производительность загрузки CSV (но сначала попробуйте кэшировать ).
При использовании встроенного загрузчика 20 пакеты из примера 2048 занимают около 17 с.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Передача пакетов текстовых строк в decode_csv выполняется быстрее, примерно за 5 секунд:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Еще один пример повышения производительности csv за счет использования больших пакетов см. в учебнике по переобучению и недообучению .
Такой подход может работать, но рассмотрите другие варианты, такие как cache и snapshot или перекодирование данных в более оптимизированный формат.