
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как классифицировать структурированные данные, такие как табличные данные, с помощью упрощенной версии набора данных PetFinder из конкурса Kaggle, хранящегося в файле CSV.
Вы будете использовать Keras для определения модели и слоев предварительной обработки Keras в качестве моста для сопоставления столбцов в файле CSV с функциями, используемыми для обучения модели. Цель состоит в том, чтобы предсказать, будет ли домашнее животное усыновлено.
Этот учебник содержит полный код для:
- Загрузка CSV-файла в DataFrame с помощью pandas .
- Создание входного конвейера для пакетной обработки и перемешивания строк с использованием
tf.data. (Посетите tf.data: Сборка входных конвейеров TensorFlow для более подробной информации.) - Сопоставление столбцов в файле CSV с функциями, используемыми для обучения модели с помощью слоев предварительной обработки Keras.
- Создание, обучение и оценка модели с использованием встроенных методов Keras.
Мини-набор данных PetFinder.my
В CSV-файле набора данных PetFinder.my mini есть несколько тысяч строк, где каждая строка описывает домашнее животное (собаку или кошку), а каждый столбец описывает атрибут, такой как возраст, порода, цвет и т. д.
Обратите внимание, что в приведенной ниже сводке набора данных в основном представлены числовые и категориальные столбцы. В этом руководстве вы будете иметь дело только с этими двумя типами функций, отбрасывая Description (функция произвольного текста) и AdoptionSpeed (функция классификации) во время предварительной обработки данных.
| Столбец | Описание питомца | Тип функции | Тип данных |
|---|---|---|---|
Type | Тип животного ( Dog , Cat ) | Категориальный | Нить |
Age | Возраст | Числовой | Целое число |
Breed1 | Основная порода | Категориальный | Нить |
Color1 | Цвет 1 | Категориальный | Нить |
Color2 | Цвет 2 | Категориальный | Нить |
MaturitySize | Размер при погашении | Категориальный | Нить |
FurLength | Длина меха | Категориальный | Нить |
Vaccinated | Животное было вакцинировано | Категориальный | Нить |
Sterilized | животное было стерилизовано | Категориальный | Нить |
Health | Состояние здоровья | Категориальный | Нить |
Fee | Плата за усыновление | Числовой | Целое число |
Description | Написание профиля | Текст | Нить |
PhotoAmt | Всего загруженных фотографий | Числовой | Целое число |
AdoptionSpeed | Категориальная скорость принятия | Классификация | Целое число |
Импорт TensorFlow и других библиотек
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
Загрузите набор данных и прочитайте его в pandas DataFrame.
pandas — это библиотека Python с множеством полезных утилит для загрузки и работы со структурированными данными. Используйте tf.keras.utils.get_file для загрузки и извлечения CSV-файла с мини-набором данных PetFinder.my и загрузки его в DataFrame с помощью pandas.read_csv :
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
Проверьте набор данных, проверив первые пять строк DataFrame:
dataframe.head()
Создайте целевую переменную
Первоначальная задача конкурса Kaggle PetFinder.my Adoption Prediction состояла в том, чтобы предсказать скорость, с которой домашнее животное будет усыновлено (например, в первую неделю, первый месяц, первые три месяца и т. д.).
В этом уроке вы упростите задачу, превратив ее в проблему бинарной классификации, где вам просто нужно предсказать, было ли домашнее животное усыновлено или нет.
После изменения столбца AdoptionSpeed 0 будет означать, что питомец не был усыновлен, а 1 — что да.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
Разделите DataFrame на наборы для обучения, проверки и тестирования.
Набор данных находится в одном кадре данных pandas. Разделите его на наборы для обучения, проверки и тестирования, используя, например, соотношение 80:10:10 соответственно:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
Создайте входной конвейер, используя tf.data
Затем создайте служебную функцию, которая преобразует каждый обучающий, проверочный и тестовый набор данных DataFrame в tf.data.Dataset , а затем перемешивает и группирует данные.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Теперь используйте только что созданную функцию ( df_to_dataset ), чтобы проверить формат данных, которые возвращает вспомогательная функция входного конвейера, вызвав ее для обучающих данных, и используйте небольшой размер пакета, чтобы выходные данные оставались читаемыми:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
Как видно из выходных данных, обучающий набор возвращает словарь имен столбцов (из DataFrame), которые сопоставляются со значениями столбцов из строк.
Примените слои предварительной обработки Keras
Уровни предварительной обработки Keras позволяют создавать собственные конвейеры обработки ввода Keras, которые можно использовать в качестве независимого кода предварительной обработки в рабочих процессах, отличных от Keras, напрямую объединять с моделями Keras и экспортировать как часть Keras SavedModel.
В этом руководстве вы будете использовать следующие четыре уровня предварительной обработки, чтобы продемонстрировать, как выполнять предварительную обработку, кодирование структурированных данных и разработку функций:
-
tf.keras.layers.Normalization: выполняет поэлементную нормализацию входных объектов. -
tf.keras.layers.CategoryEncoding: превращает целочисленные категориальные признаки в однократные, множественные или плотные представления tf-idf . -
tf.keras.layers.StringLookup: превращает строковые категориальные значения в целые индексы. -
tf.keras.layers.IntegerLookup: превращает целочисленные категориальные значения в целочисленные индексы.
Вы можете узнать больше о доступных слоях в руководстве Работа со слоями предварительной обработки .
- Для числовых характеристик мини-набора данных PetFinder.my вы будете использовать слой
tf.keras.layers.Normalizationдля стандартизации распределения данных. - Для категориальных функций , таких как pet
Type(строкиDogиCat), вы преобразуете их в тензоры с горячим кодированием с помощьюtf.keras.layers.CategoryEncoding.
Числовые столбцы
Для каждого числового признака в мини-наборе данных PetFinder.my вы будете использовать слой tf.keras.layers.Normalization для стандартизации распределения данных.
Определите новую служебную функцию, которая возвращает слой, который применяет поэлементную нормализацию к числовым функциям, используя этот слой предварительной обработки Keras:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Затем протестируйте новую функцию, вызвав ее на всех загруженных функциях фотографий домашних животных, чтобы нормализовать 'PhotoAmt' :
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
Категориальные столбцы
Type домашних животных в наборе данных представлены в виде строк — Dog и Cat — которые должны быть многократно закодированы перед тем, как быть загруженными в модель. Функция Age
Определите еще одну новую служебную функцию, которая возвращает слой, который сопоставляет значения из словаря с целочисленными индексами и выполняет многократное горячее кодирование функций с использованием предварительной tf.keras.layers.StringLookup , tf.keras.layers.IntegerLookup и tf.keras.CategoryEncoding слои:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
Протестируйте функцию get_category_encoding_layer , вызвав ее на функциях Pet 'Type' , чтобы превратить их в тензоры с множественным горячим кодированием:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
Повторите процесс для питомца 'Age' :
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
Предварительно обработайте выбранные функции для обучения модели.
Вы узнали, как использовать несколько типов слоев предварительной обработки Keras. Далее вы будете:
- Примените служебные функции предварительной обработки, определенные ранее, к 13 числовым и категориальным функциям из мини-набора данных PetFinder.my.
- Добавьте все входные данные функции в список.
Как упоминалось в начале, для обучения модели вы будете использовать числовой ( 'PhotoAmt' , 'Fee' ) и категориальный ( 'Age' , 'Type' , 'Color1' Цвет1», 'Color2' Цвет2», 'Gender' Цвет» мини-набора данных PetFinder.my). 'Gender' , «Размер 'MaturitySize' , 'FurLength' , 'Vaccinated' , 'Sterilized' , 'Health' , 'Breed1' ).
Ранее вы использовали небольшой пакет для демонстрации входного конвейера. Давайте теперь создадим новый входной конвейер с большим размером пакета 256:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
Нормализуйте числовые характеристики (количество фотографий домашних животных и плату за усыновление) и добавьте их в один список входных данных с именем encoded_features :
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
Превратите целочисленные категориальные значения из набора данных (возраст питомца) в целочисленные индексы, выполните многократное горячее кодирование и добавьте полученные входные данные функций в encoded_features :
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
Повторите тот же шаг для строковых категориальных значений:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
Создание, компиляция и обучение модели
Следующим шагом будет создание модели с помощью Keras Functional API . Для первого слоя в вашей модели объедините список входных признаков — encoded_features — в один вектор посредством конкатенации с помощью tf.keras.layers.concatenate .
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Настройте модель с помощью Model.compile :
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
Давайте визуализируем граф связности:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
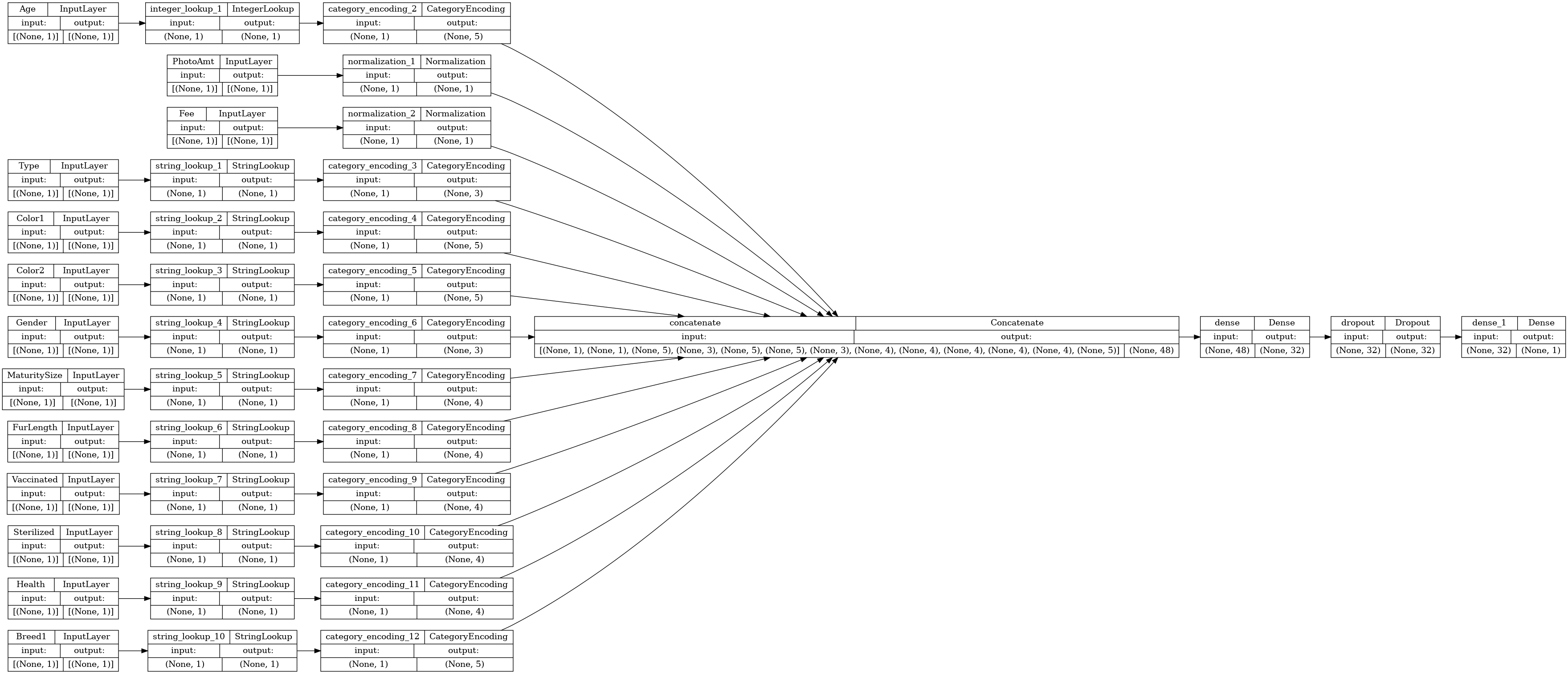
Затем обучите и протестируйте модель:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
Выполнить вывод
Разработанная вами модель теперь может классифицировать строку из CSV-файла сразу после того, как вы включили слои предварительной обработки в саму модель.
Теперь вы можете сохранить и перезагрузить модель Keras с помощью Model.save и Model.load_model перед выполнением вывода на новых данных:
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
Чтобы получить прогноз для нового образца, вы можете просто вызвать метод Model.predict . Вам нужно сделать всего две вещи:
- Оберните скаляры в список, чтобы иметь пакетное измерение (
Modelобрабатывает только пакеты данных, а не отдельные образцы). - Вызовите
tf.convert_to_tensorдля каждой функции.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
Следующие шаги
Чтобы узнать больше о классификации структурированных данных, попробуйте поработать с другими наборами данных. Чтобы повысить точность во время обучения и тестирования ваших моделей, тщательно продумайте, какие функции включить в вашу модель и как они должны быть представлены.
Ниже приведены некоторые предложения для наборов данных:
- Наборы данных TensorFlow: MovieLens : набор рейтингов фильмов из службы рекомендаций фильмов.
- Наборы данных TensorFlow: Качество вина : два набора данных, относящиеся к красному и белому вариантам португальского вина «Виньо Верде». Вы также можете найти набор данных Red Wine Quality на Kaggle .
- Kaggle: набор данных arXiv : сборник из 1,7 миллиона научных статей из arXiv, охватывающих физику, информатику, математику, статистику, электротехнику, количественную биологию и экономику.