
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве представлены примеры того, как загружать кадры данных pandas в TensorFlow .
Вы будете использовать небольшой набор данных о сердечных заболеваниях , предоставленный репозиторием машинного обучения UCI. В CSV несколько сотен строк. Каждая строка описывает пациента, а каждый столбец описывает атрибут. Вы будете использовать эту информацию, чтобы предсказать, есть ли у пациента заболевание сердца, что является задачей бинарной классификации.
Чтение данных с помощью панд
import pandas as pd
import tensorflow as tf
SHUFFLE_BUFFER = 500
BATCH_SIZE = 2
Загрузите файл CSV, содержащий набор данных о сердечных заболеваниях:
csv_file = tf.keras.utils.get_file('heart.csv', 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
Прочитайте файл CSV с помощью pandas:
df = pd.read_csv(csv_file)
Вот как выглядят данные:
df.head()
df.dtypes
age int64 sex int64 cp int64 trestbps int64 chol int64 fbs int64 restecg int64 thalach int64 exang int64 oldpeak float64 slope int64 ca int64 thal object target int64 dtype: object
Вы создадите модели для прогнозирования метки, содержащейся в target столбце.
target = df.pop('target')
DataFrame как массив
Если ваши данные имеют универсальный тип данных или dtype , можно использовать DataFrame pandas везде, где вы могли бы использовать массив NumPy. Это работает, потому что класс pandas.DataFrame поддерживает протокол __array__ , а функция tf.convert_to_tensor принимает объекты, поддерживающие протокол.
Возьмите числовые признаки из набора данных (пока пропустите категориальные признаки):
numeric_feature_names = ['age', 'thalach', 'trestbps', 'chol', 'oldpeak']
numeric_features = df[numeric_feature_names]
numeric_features.head()
DataFrame можно преобразовать в массив NumPy с помощью свойства DataFrame.values или numpy.array(df) . Чтобы преобразовать его в тензор, используйте tf.convert_to_tensor :
tf.convert_to_tensor(numeric_features)
<tf.Tensor: shape=(303, 5), dtype=float64, numpy=
array([[ 63. , 150. , 145. , 233. , 2.3],
[ 67. , 108. , 160. , 286. , 1.5],
[ 67. , 129. , 120. , 229. , 2.6],
...,
[ 65. , 127. , 135. , 254. , 2.8],
[ 48. , 150. , 130. , 256. , 0. ],
[ 63. , 154. , 150. , 407. , 4. ]])>
В общем, если объект можно преобразовать в тензор с помощью tf.convert_to_tensor , его можно передать везде, где вы можете передать tf.Tensor .
С моделью.fit
DataFrame, интерпретируемый как один тензор, может использоваться непосредственно в качестве аргумента метода Model.fit .
Ниже приведен пример обучения модели числовым признакам набора данных.
Первым шагом является нормализация входных диапазонов. Используйте для этого слой tf.keras.layers.Normalization .
Чтобы установить среднее значение и стандартное отклонение слоя перед его запуском, обязательно вызовите метод Normalization.adapt :
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(numeric_features)
Вызовите слой в первых трех строках DataFrame, чтобы визуализировать пример вывода этого слоя:
normalizer(numeric_features.iloc[:3])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[ 0.93383914, 0.03480718, 0.74578077, -0.26008663, 1.0680453 ],
[ 1.3782105 , -1.7806165 , 1.5923285 , 0.7573877 , 0.38022864],
[ 1.3782105 , -0.87290466, -0.6651321 , -0.33687714, 1.3259765 ]],
dtype=float32)>
Используйте слой нормализации в качестве первого слоя простой модели:
def get_basic_model():
model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
Когда вы передаете DataFrame в качестве аргумента x в Model.fit , Keras обрабатывает DataFrame так же, как массив NumPy:
model = get_basic_model()
model.fit(numeric_features, target, epochs=15, batch_size=BATCH_SIZE)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.6839 - accuracy: 0.7690 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5789 - accuracy: 0.7789 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5195 - accuracy: 0.7723 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.7855 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4566 - accuracy: 0.7789 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4427 - accuracy: 0.7888 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4342 - accuracy: 0.7921 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4290 - accuracy: 0.7855 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4240 - accuracy: 0.7987 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4232 - accuracy: 0.7987 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4208 - accuracy: 0.7987 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4186 - accuracy: 0.7954 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4172 - accuracy: 0.8020 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.8020 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4138 - accuracy: 0.8020 <keras.callbacks.History at 0x7f1ddc27b110>
С tf.data
Если вы хотите применить преобразования tf.data к DataFrame универсального dtype , метод Dataset.from_tensor_slices создаст набор данных, который перебирает строки DataFrame. Каждая строка изначально является вектором значений. Для обучения модели вам нужны пары (inputs, labels) , поэтому pass (features, labels) и Dataset.from_tensor_slices вернет необходимые пары срезов:
numeric_dataset = tf.data.Dataset.from_tensor_slices((numeric_features, target))
for row in numeric_dataset.take(3):
print(row)
(<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 63. , 150. , 145. , 233. , 2.3])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 108. , 160. , 286. , 1.5])>, <tf.Tensor: shape=(), dtype=int64, numpy=1>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 129. , 120. , 229. , 2.6])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
numeric_batches = numeric_dataset.shuffle(1000).batch(BATCH_SIZE)
model = get_basic_model()
model.fit(numeric_batches, epochs=15)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.7677 - accuracy: 0.6865 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.6319 - accuracy: 0.7591 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5717 - accuracy: 0.7459 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7558 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.7624 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4584 - accuracy: 0.7657 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4454 - accuracy: 0.7657 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4379 - accuracy: 0.7789 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4324 - accuracy: 0.7789 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4282 - accuracy: 0.7756 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4273 - accuracy: 0.7789 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4268 - accuracy: 0.7756 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4248 - accuracy: 0.7789 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4235 - accuracy: 0.7855 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4223 - accuracy: 0.7888 <keras.callbacks.History at 0x7f1ddc406510>
DataFrame как словарь
Когда вы начинаете работать с разнородными данными, уже невозможно обращаться с DataFrame, как если бы это был один массив. Тензоры TensorFlow требуют, чтобы все элементы имели одинаковый dtype .
Итак, в этом случае вам нужно начать рассматривать его как словарь столбцов, где каждый столбец имеет единый тип dtype. DataFrame очень похож на словарь массивов, поэтому обычно все, что вам нужно сделать, это преобразовать DataFrame в словарь Python. Многие важные API-интерфейсы TensorFlow поддерживают (вложенные) словари массивов в качестве входных данных.
Конвейеры ввода tf.data справляются с этим довольно хорошо. Все операции tf.data обрабатывают словари и кортежи автоматически. Итак, чтобы создать набор данных примеров-словарей из DataFrame, просто приведите его к словарю, прежде чем нарезать его с помощью Dataset.from_tensor_slices :
numeric_dict_ds = tf.data.Dataset.from_tensor_slices((dict(numeric_features), target))
Вот первые три примера из этого набора данных:
for row in numeric_dict_ds.take(3):
print(row)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=63>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=150>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=145>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=233>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.3>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=108>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=160>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=286>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=1.5>}, <tf.Tensor: shape=(), dtype=int64, numpy=1>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=129>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=120>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=229>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.6>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
Словари с Керасом
Как правило, модели и слои Keras ожидают один входной тензор, но эти классы могут принимать и возвращать вложенные структуры словарей, кортежей и тензоров. Эти структуры известны как «гнезда» (подробности см. в модуле tf.nest ).
Есть два эквивалентных способа написать модель keras, которая принимает словарь в качестве входных данных.
1. Стиль подкласса модели
Вы пишете подкласс tf.keras.Model (или tf.keras.Layer ). Вы напрямую обрабатываете входные данные и создаете выходные данные:
def stack_dict(inputs, fun=tf.stack):
values = []
for key in sorted(inputs.keys()):
values.append(tf.cast(inputs[key], tf.float32))
return fun(values, axis=-1)
class MyModel(tf.keras.Model):
def __init__(self):
# Create all the internal layers in init.
super().__init__(self)
self.normalizer = tf.keras.layers.Normalization(axis=-1)
self.seq = tf.keras.Sequential([
self.normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
def adapt(self, inputs):
# Stach the inputs and `adapt` the normalization layer.
inputs = stack_dict(inputs)
self.normalizer.adapt(inputs)
def call(self, inputs):
# Stack the inputs
inputs = stack_dict(inputs)
# Run them through all the layers.
result = self.seq(inputs)
return result
model = MyModel()
model.adapt(dict(numeric_features))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
Эта модель может принимать либо словарь столбцов, либо набор данных элементов словаря для обучения:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 3s 17ms/step - loss: 0.6736 - accuracy: 0.7063 Epoch 2/5 152/152 [==============================] - 3s 17ms/step - loss: 0.5577 - accuracy: 0.7294 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4869 - accuracy: 0.7591 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4525 - accuracy: 0.7690 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4403 - accuracy: 0.7624 <keras.callbacks.History at 0x7f1de4fa9390>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4328 - accuracy: 0.7756 Epoch 2/5 152/152 [==============================] - 2s 14ms/step - loss: 0.4297 - accuracy: 0.7888 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4270 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4245 - accuracy: 0.8020 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4240 - accuracy: 0.7921 <keras.callbacks.History at 0x7f1ddc0dba90>
Вот прогнозы для первых трех примеров:
model.predict(dict(numeric_features.iloc[:3]))
array([[[0.00565109]],
[[0.60601974]],
[[0.03647463]]], dtype=float32)
2. Функциональный стиль Keras
inputs = {}
for name, column in numeric_features.items():
inputs[name] = tf.keras.Input(
shape=(1,), name=name, dtype=tf.float32)
inputs
{'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'thalach': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'thalach')>,
'trestbps': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'chol')>,
'oldpeak': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'oldpeak')>}
x = stack_dict(inputs, fun=tf.concat)
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
x = normalizer(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
tf.keras.utils.plot_model(model, rankdir="LR", show_shapes=True)

Вы можете обучать функциональную модель так же, как и подкласс модели:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.6529 - accuracy: 0.7492 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.5448 - accuracy: 0.7624 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4935 - accuracy: 0.7756 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4650 - accuracy: 0.7789 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4486 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1ddc0d0f90>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4398 - accuracy: 0.7855 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4330 - accuracy: 0.7855 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4294 - accuracy: 0.7921 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4271 - accuracy: 0.7888 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4231 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1d7c5d5d10>
Полный пример
Если вы передаете гетерогенный DataFrame в Keras, для каждого столбца может потребоваться уникальная предварительная обработка. Вы можете выполнить эту предварительную обработку непосредственно в DataFrame, но для правильной работы модели входные данные всегда должны предварительно обрабатываться одинаково. Таким образом, лучший подход — встроить предварительную обработку в модель. Слои предварительной обработки Keras охватывают многие общие задачи.
Создайте головку предварительной обработки
В этом наборе данных некоторые из «целочисленных» признаков в необработанных данных на самом деле являются категориальными индексами. Эти индексы на самом деле не являются упорядоченными числовыми значениями (подробности см. в описании набора данных). Поскольку они неупорядочены, их нецелесообразно подавать прямо в модель; модель будет интерпретировать их как упорядоченные. Чтобы использовать эти входные данные, вам нужно будет закодировать их либо как горячие векторы, либо как векторы встраивания. То же самое относится и к строковым категориальным функциям.
С другой стороны, бинарные функции обычно не нужно кодировать или нормализовать.
Начните с создания списка функций, которые попадают в каждую группу:
binary_feature_names = ['sex', 'fbs', 'exang']
categorical_feature_names = ['cp', 'restecg', 'slope', 'thal', 'ca']
Следующим шагом является построение модели предварительной обработки, которая будет применять соответствующую предварительную обработку к каждому входу и объединять результаты.
В этом разделе для реализации предварительной обработки используется функциональный API Keras. Вы начинаете с создания одного tf.keras.Input для каждого столбца фрейма данных:
inputs = {}
for name, column in df.items():
if type(column[0]) == str:
dtype = tf.string
elif (name in categorical_feature_names or
name in binary_feature_names):
dtype = tf.int64
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype)
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
Для каждого ввода вы примените некоторые преобразования, используя слои Keras и операции TensorFlow. Каждая функция начинается с набора скаляров ( shape=(batch,) ). Выход для каждого должен быть пакетом векторов tf.float32 ( shape=(batch, n) ). Последний шаг объединит все эти векторы вместе.
Двоичные входы
Поскольку бинарные входы не нуждаются в какой-либо предварительной обработке, просто добавьте векторную ось, приведите их к float32 и добавьте в список предварительно обработанных входов:
preprocessed = []
for name in binary_feature_names:
inp = inputs[name]
inp = inp[:, tf.newaxis]
float_value = tf.cast(inp, tf.float32)
preprocessed.append(float_value)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>]
Числовые входы
Как и в предыдущем разделе, вы захотите запустить эти числовые входные данные через слой tf.keras.layers.Normalization перед их использованием. Разница в том, что на этот раз они вводятся как диктофон. Приведенный ниже код собирает числовые функции из DataFrame, объединяет их вместе и передает в метод Normalization.adapt .
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
В приведенном ниже коде числовые функции складываются и проходят через слой нормализации.
numeric_inputs = {}
for name in numeric_feature_names:
numeric_inputs[name]=inputs[name]
numeric_inputs = stack_dict(numeric_inputs)
numeric_normalized = normalizer(numeric_inputs)
preprocessed.append(numeric_normalized)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>]
Категориальные признаки
Чтобы использовать категориальные функции, вам сначала нужно закодировать их в двоичные векторы или вложения. Поскольку эти функции содержат лишь небольшое количество категорий, преобразуйте входные данные непосредственно в горячие векторы с помощью output_mode='one_hot' , поддерживаемой слоями tf.keras.layers.StringLookup и tf.keras.layers.IntegerLookup .
Вот пример того, как работают эти слои:
vocab = ['a','b','c']
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
lookup(['c','a','a','b','zzz'])
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.]], dtype=float32)>
vocab = [1,4,7,99]
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
lookup([-1,4,1])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]], dtype=float32)>
Чтобы определить словарь для каждого входа, создайте слой для преобразования этого словаря в однократный вектор:
for name in categorical_feature_names:
vocab = sorted(set(df[name]))
print(f'name: {name}')
print(f'vocab: {vocab}\n')
if type(vocab[0]) is str:
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
else:
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
x = inputs[name][:, tf.newaxis]
x = lookup(x)
preprocessed.append(x)
name: cp vocab: [0, 1, 2, 3, 4] name: restecg vocab: [0, 1, 2] name: slope vocab: [1, 2, 3] name: thal vocab: ['1', '2', 'fixed', 'normal', 'reversible'] name: ca vocab: [0, 1, 2, 3]
Соберите головку предварительной обработки
На данный момент preprocessed — это просто список Python всех результатов предварительной обработки, каждый результат имеет вид (batch_size, depth) :
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'integer_lookup_1')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_2')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'string_lookup_1')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'integer_lookup_4')>]
Объедините все предварительно обработанные объекты по оси depth , чтобы каждый словарь-пример был преобразован в один вектор. Вектор содержит категориальные признаки, числовые признаки и категориальные одноразовые признаки:
preprocesssed_result = tf.concat(preprocessed, axis=-1)
preprocesssed_result
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'tf.concat_1')>
Теперь создайте модель из этого расчета, чтобы ее можно было использовать повторно:
preprocessor = tf.keras.Model(inputs, preprocesssed_result)
tf.keras.utils.plot_model(preprocessor, rankdir="LR", show_shapes=True)
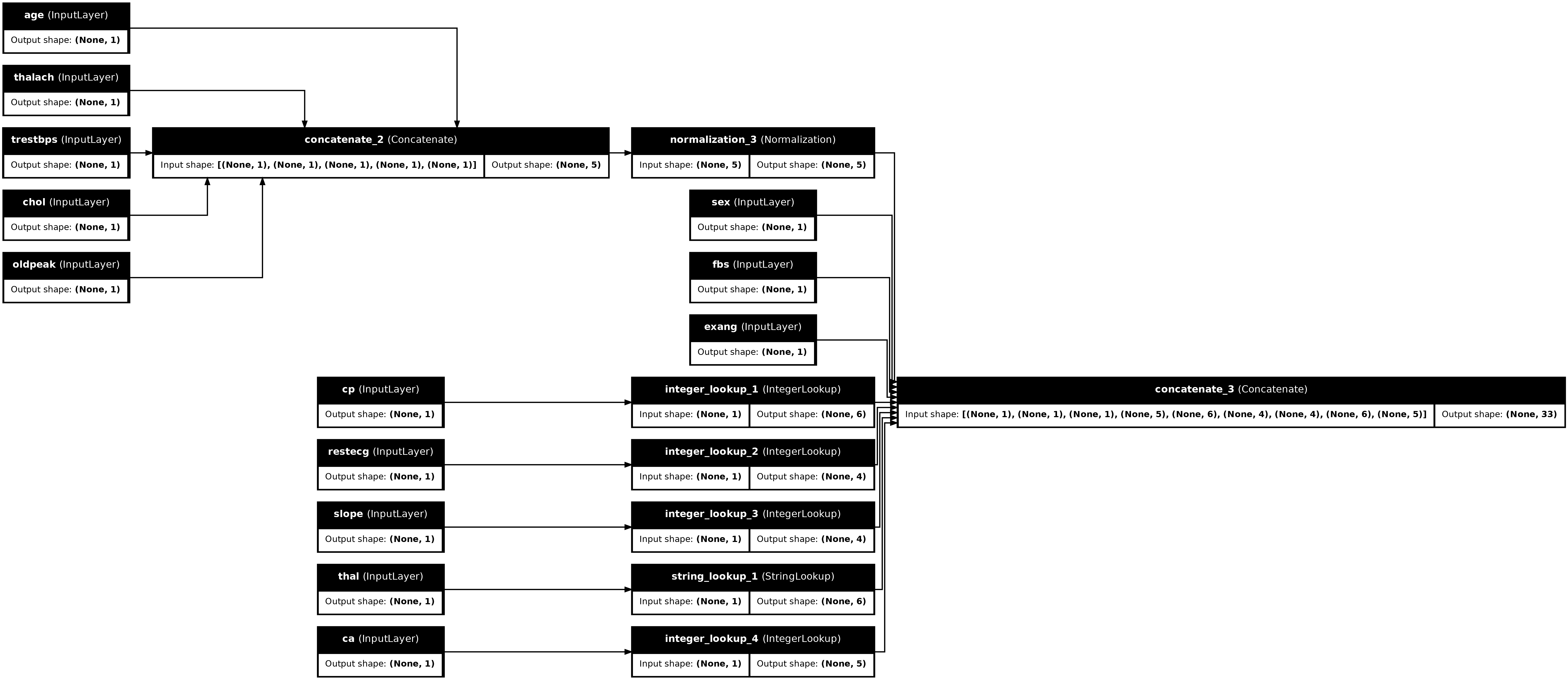
Чтобы протестировать препроцессор, используйте метод доступа DataFrame.iloc , чтобы вырезать первый пример из DataFrame. Затем преобразуйте его в словарь и передайте словарь препроцессору. Результатом является единый вектор, содержащий бинарные функции, нормализованные числовые функции и однократные категориальные функции в следующем порядке:
preprocessor(dict(df.iloc[:1]))
<tf.Tensor: shape=(1, 33), dtype=float32, numpy=
array([[ 1. , 1. , 0. , 0.93383914, -0.26008663,
1.0680453 , 0.03480718, 0.74578077, 0. , 0. ,
1. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. ]], dtype=float32)>
Создание и обучение модели
Теперь создайте основную часть модели. Используйте ту же конфигурацию, что и в предыдущем примере: пара слоев Dense rectified-linear и выходной слой Dense(1) для классификации.
body = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
Теперь соедините две части вместе, используя функциональный API Keras.
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
x = preprocessor(inputs)
x
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'model_1')>
result = body(x)
result
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'sequential_3')>
model = tf.keras.Model(inputs, result)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Эта модель ожидает словарь входных данных. Самый простой способ передать ему данные — преобразовать DataFrame в словарь и передать этот словарь в качестве аргумента x в Model.fit :
history = model.fit(dict(df), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 1s 4ms/step - loss: 0.6911 - accuracy: 0.6997 Epoch 2/5 152/152 [==============================] - 1s 4ms/step - loss: 0.5073 - accuracy: 0.7393 Epoch 3/5 152/152 [==============================] - 1s 4ms/step - loss: 0.4129 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3663 - accuracy: 0.7921 Epoch 5/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3363 - accuracy: 0.8152
Использование tf.data также работает:
ds = tf.data.Dataset.from_tensor_slices((
dict(df),
target
))
ds = ds.batch(BATCH_SIZE)
import pprint
for x, y in ds.take(1):
pprint.pprint(x)
print()
print(y)
{'age': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([63, 67])>,
'ca': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 3])>,
'chol': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([233, 286])>,
'cp': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 4])>,
'exang': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>,
'fbs': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 0])>,
'oldpeak': <tf.Tensor: shape=(2,), dtype=float64, numpy=array([2.3, 1.5])>,
'restecg': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 2])>,
'sex': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 1])>,
'slope': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 2])>,
'thal': <tf.Tensor: shape=(2,), dtype=string, numpy=array([b'fixed', b'normal'], dtype=object)>,
'thalach': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([150, 108])>,
'trestbps': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([145, 160])>}
tf.Tensor([0 1], shape=(2,), dtype=int64)
history = model.fit(ds, epochs=5)
Epoch 1/5 152/152 [==============================] - 1s 5ms/step - loss: 0.3150 - accuracy: 0.8284 Epoch 2/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2989 - accuracy: 0.8449 Epoch 3/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2870 - accuracy: 0.8449 Epoch 4/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2782 - accuracy: 0.8482 Epoch 5/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2712 - accuracy: 0.8482