
Các sự kiện thảm khốc liên quan đến NaN đôi khi có thể xảy ra trong chương trình TensorFlow, làm tê liệt quá trình đào tạo mô hình. Nguyên nhân cốt lõi của những sự kiện như vậy thường không rõ ràng, đặc biệt đối với các mô hình có quy mô và độ phức tạp không hề nhỏ. Để giúp việc gỡ lỗi loại lỗi mô hình này dễ dàng hơn, TensorBoard 2.3+ (cùng với TensorFlow 2.3+) cung cấp một bảng thông tin chuyên dụng có tên Debugger V2. Ở đây chúng tôi trình bày cách sử dụng công cụ này bằng cách xử lý một lỗi thực sự liên quan đến NaN trong mạng thần kinh được viết bằng TensorFlow.
Các kỹ thuật được minh họa trong hướng dẫn này có thể áp dụng cho các loại hoạt động gỡ lỗi khác, chẳng hạn như kiểm tra hình dạng tenxơ thời gian chạy trong các chương trình phức tạp. Hướng dẫn này tập trung vào NaN do tần suất xuất hiện tương đối cao của chúng.
Quan sát lỗi
Mã nguồn của chương trình TF2 mà chúng tôi sẽ gỡ lỗi có sẵn trên GitHub . Chương trình ví dụ cũng được đóng gói trong gói tensorflow pip (phiên bản 2.3+) và có thể được gọi bằng cách:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Chương trình TF2 này tạo ra nhận thức nhiều lớp (MLP) và huấn luyện nó để nhận dạng hình ảnh MNIST . Ví dụ này sử dụng API cấp thấp của TF2 một cách có mục đích để xác định cấu trúc lớp tùy chỉnh, hàm mất và vòng huấn luyện, vì khả năng xảy ra lỗi NaN cao hơn khi chúng ta sử dụng API linh hoạt hơn nhưng dễ bị lỗi hơn này so với khi chúng ta sử dụng API dễ dàng hơn. -các API cấp cao dễ sử dụng nhưng kém linh hoạt hơn một chút, chẳng hạn như tf.keras .
Chương trình in kết quả kiểm tra độ chính xác sau mỗi bước huấn luyện. Chúng ta có thể thấy trong bảng điều khiển rằng độ chính xác của thử nghiệm bị kẹt ở mức gần như có thể xảy ra (~0,1) sau bước đầu tiên. Đây chắc chắn không phải là cách hoạt động của quá trình đào tạo mô hình được mong đợi: chúng tôi kỳ vọng độ chính xác sẽ dần dần đạt đến 1,0 (100%) khi bước tăng lên.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Một phỏng đoán có cơ sở là vấn đề này xảy ra do sự mất ổn định về mặt số học, chẳng hạn như NaN hoặc vô cực. Tuy nhiên, làm cách nào để chúng tôi xác nhận trường hợp này thực sự xảy ra và làm cách nào để chúng tôi tìm ra hoạt động TensorFlow (op) chịu trách nhiệm tạo ra sự mất ổn định về số? Để trả lời những câu hỏi này, hãy cài đặt chương trình có lỗi bằng Debugger V2.
Thiết bị mã TensorFlow với Debugger V2
tf.debugging.experimental.enable_dump_debug_info() là điểm vào API của Trình gỡ lỗi V2. Nó tạo ra một chương trình TF2 với một dòng mã duy nhất. Ví dụ: việc thêm dòng sau vào gần đầu chương trình sẽ khiến thông tin gỡ lỗi được ghi vào thư mục nhật ký (logdir) tại /tmp/tfdbg2_logdir. Thông tin gỡ lỗi bao gồm nhiều khía cạnh khác nhau của thời gian chạy TensorFlow. Trong TF2, nó bao gồm toàn bộ lịch sử thực thi mong muốn, xây dựng biểu đồ được thực hiện bởi @tf.function , việc thực thi biểu đồ, các giá trị tensor được tạo bởi các sự kiện thực thi cũng như vị trí mã (dấu vết ngăn xếp Python) của các sự kiện đó . Sự phong phú của thông tin gỡ lỗi cho phép người dùng thu hẹp các lỗi khó hiểu.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
Đối số tensor_debug_mode kiểm soát thông tin mà Debugger V2 trích xuất từ mỗi tensor háo hức hoặc trong biểu đồ. “FULL_HEALTH” là chế độ ghi lại các thông tin sau về từng tensor kiểu float (ví dụ: float32 thường thấy và dtype bfloat16 ít phổ biến hơn):
- Loại D
- Thứ hạng
- Tổng số phần tử
- Phân tích các phần tử kiểu động thành các loại sau: hữu hạn âm (
-), 0 (0), hữu hạn dương (+), vô cực âm (-∞), vô cực dương (+∞) vàNaN.
Chế độ “FULL_HEALTH” phù hợp để gỡ lỗi các lỗi liên quan đến NaN và vô cực. Xem bên dưới để biết các tensor_debug_mode được hỗ trợ khác.
Đối số circular_buffer_size kiểm soát số lượng sự kiện tensor được lưu vào logdir. Nó mặc định là 1000, điều này khiến chỉ 1000 tensor cuối cùng trước khi kết thúc chương trình TF2 được trang bị thiết bị mới được lưu vào đĩa. Hành vi mặc định này làm giảm chi phí của trình gỡ lỗi bằng cách hy sinh tính đầy đủ của dữ liệu gỡ lỗi. Nếu tính đầy đủ được ưu tiên, như trong trường hợp này, chúng ta có thể vô hiệu hóa bộ đệm tròn bằng cách đặt đối số thành giá trị âm (ví dụ: -1 ở đây).
Ví dụ debug_mnist_v2 gọi enable_dump_debug_info() bằng cách chuyển cờ dòng lệnh tới nó. Để chạy lại chương trình TF2 có vấn đề của chúng tôi khi bật công cụ gỡ lỗi này, hãy làm:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Khởi động GUI Debugger V2 trong TensorBoard
Việc chạy chương trình với công cụ gỡ lỗi sẽ tạo ra một logdir tại /tmp/tfdbg2_logdir. Chúng ta có thể khởi động TensorBoard và trỏ nó vào logdir bằng:
tensorboard --logdir /tmp/tfdbg2_logdir
Trong trình duyệt web, điều hướng đến trang của TensorBoard tại http://localhost:6006. Theo mặc định, plugin “Trình gỡ lỗi V2” sẽ không hoạt động, vì vậy hãy chọn nó từ menu “Plugin không hoạt động” ở trên cùng bên phải. Sau khi được chọn, nó sẽ trông giống như sau:
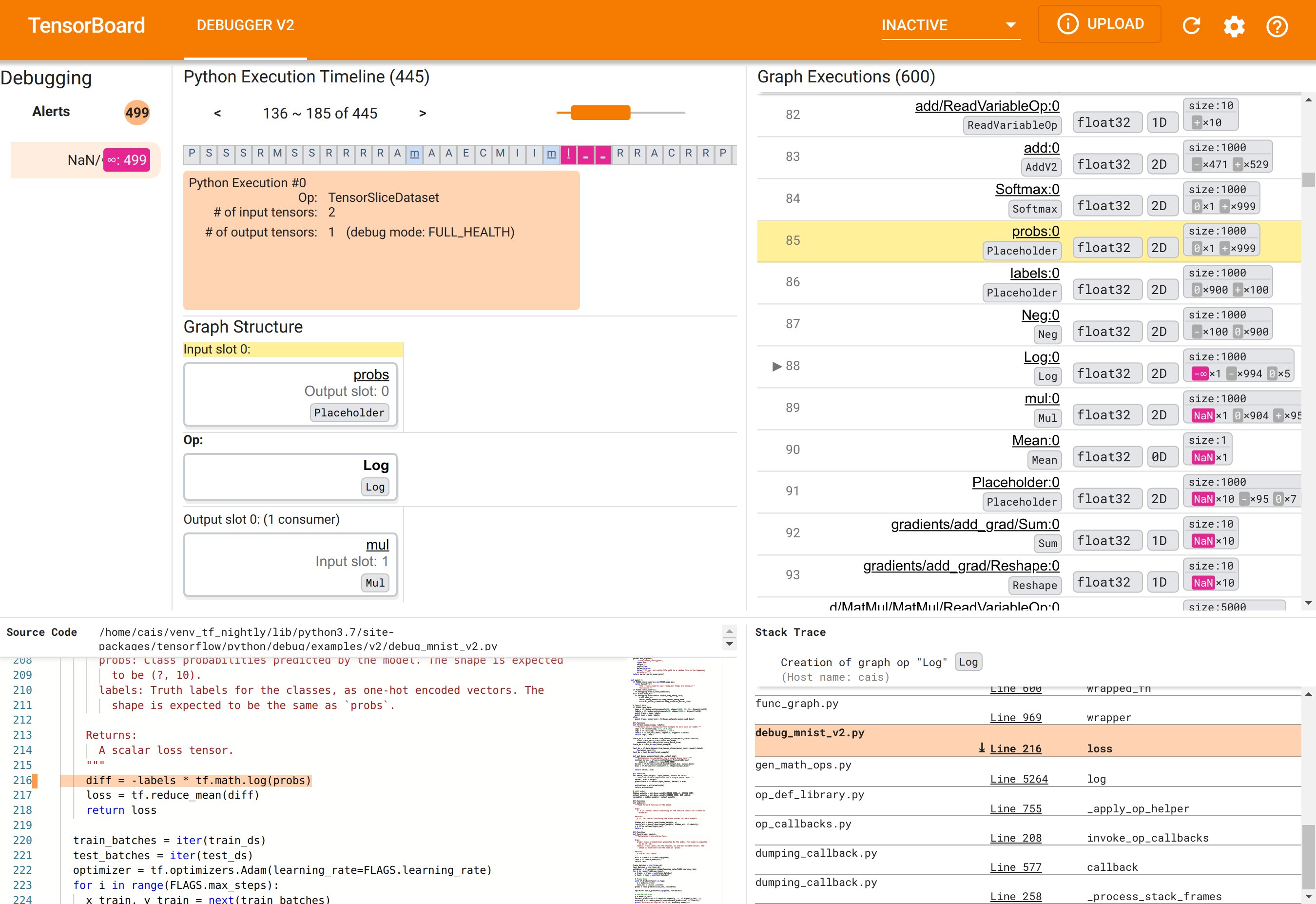
Sử dụng GUI Debugger V2 để tìm nguyên nhân gốc rễ của NaN
GUI Debugger V2 trong TensorBoard được tổ chức thành sáu phần:
- Cảnh báo : Phần trên cùng bên trái này chứa danh sách các sự kiện “cảnh báo” được trình gỡ lỗi phát hiện trong dữ liệu gỡ lỗi từ chương trình TensorFlow được trang bị thiết bị. Mỗi cảnh báo chỉ ra một điểm bất thường nhất định cần được chú ý. Trong trường hợp của chúng tôi, phần này làm nổi bật 499 sự kiện NaN/∞ với màu đỏ hồng nổi bật. Điều này xác nhận sự nghi ngờ của chúng tôi rằng mô hình không học được do sự hiện diện của NaN và/hoặc các giá trị vô hạn trong các giá trị tensor bên trong của nó. Chúng tôi sẽ sớm đi sâu vào những cảnh báo này.
- Dòng thời gian thực thi Python : Đây là nửa trên của phần trên cùng giữa. Nó trình bày toàn bộ lịch sử của việc thực hiện các hoạt động và đồ thị một cách háo hức. Mỗi hộp của dòng thời gian được đánh dấu bằng chữ cái đầu của tên op hoặc tên biểu đồ (ví dụ: “T” cho “TensorSliceDataset” op, “m” cho “model”
tf.function). Chúng ta có thể điều hướng dòng thời gian này bằng cách sử dụng các nút điều hướng và thanh cuộn phía trên dòng thời gian. - Thực thi đồ thị : Nằm ở góc trên bên phải của GUI, phần này sẽ là trọng tâm trong nhiệm vụ gỡ lỗi của chúng tôi. Nó chứa lịch sử của tất cả các tensor dtype nổi được tính toán bên trong các biểu đồ (nghĩa là được biên dịch bởi
@tf-functions). - Cấu trúc biểu đồ (nửa dưới của phần trên cùng ở giữa), Mã nguồn (phần dưới cùng bên trái) và Dấu vết ngăn xếp (phần dưới cùng bên phải) ban đầu trống. Nội dung của chúng sẽ được điền khi chúng ta tương tác với GUI. Ba phần này cũng sẽ đóng vai trò quan trọng trong nhiệm vụ gỡ lỗi của chúng tôi.
Sau khi đã định hướng về cách tổ chức giao diện người dùng, chúng ta hãy thực hiện các bước sau để tìm hiểu lý do tại sao NaN lại xuất hiện. Đầu tiên, nhấp vào cảnh báo NaN/∞ trong phần Cảnh báo. Thao tác này sẽ tự động cuộn danh sách 600 tensor biểu đồ trong phần Thực thi biểu đồ và tập trung vào #88, là tensor có tên Log:0 được tạo bởi Log (logarit tự nhiên) op. Màu đỏ hồng nổi bật làm nổi bật phần tử -∞ trong số 1000 phần tử của tenxơ float32 2D. Đây là tensor đầu tiên trong lịch sử thời gian chạy của chương trình TF2 chứa bất kỳ NaN hoặc vô cực nào: tensor được tính toán trước đó không chứa NaN hoặc ∞; nhiều (trên thực tế là hầu hết) tensor được tính toán sau đó đều chứa NaN. Chúng ta có thể xác nhận điều này bằng cách cuộn lên xuống danh sách Thực thi đồ thị. Quan sát này cung cấp một gợi ý rõ ràng rằng Log op là nguồn gốc của sự mất ổn định về mặt số học trong chương trình TF2 này.
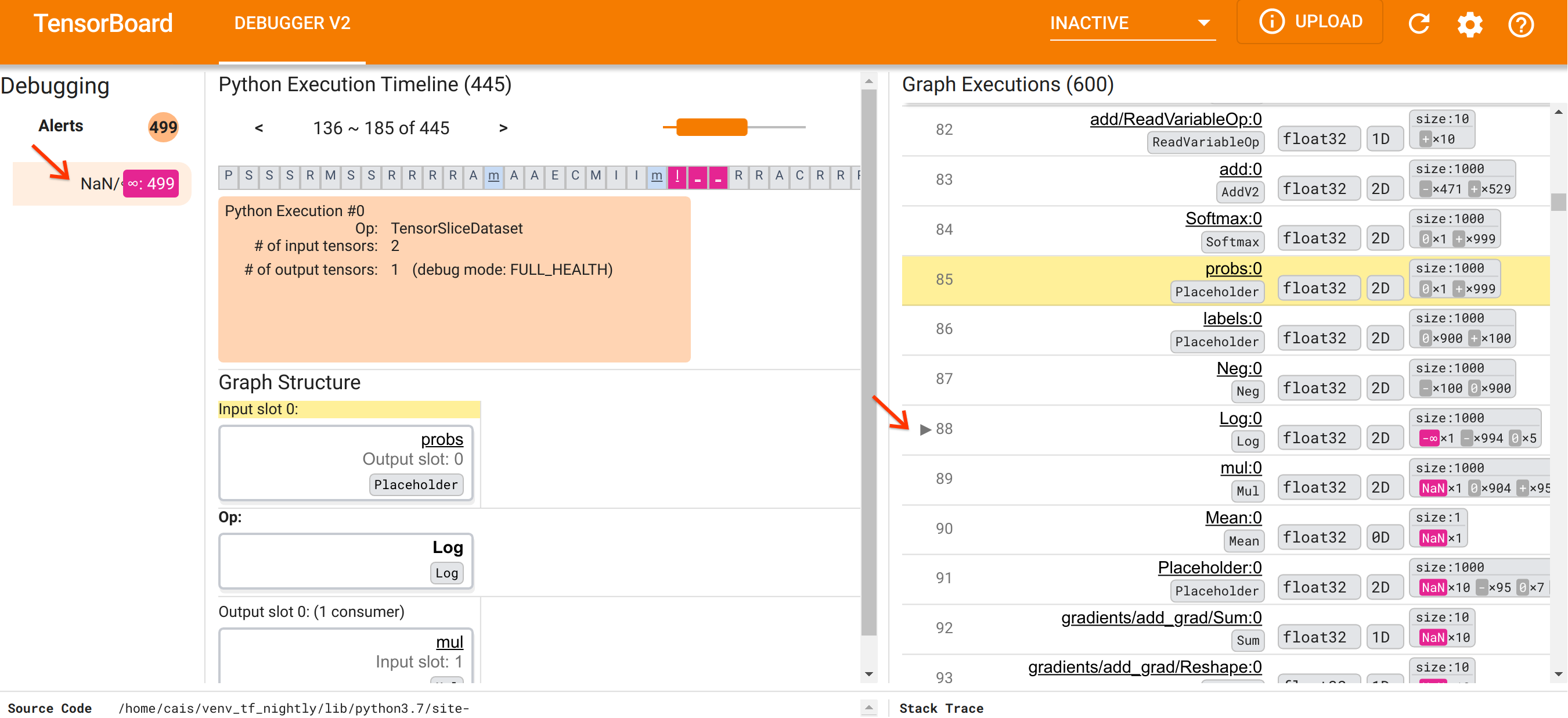
Tại sao Log op này lại xuất hiện -∞? Trả lời câu hỏi đó yêu cầu kiểm tra đầu vào của op. Nhấp vào tên của tensor ( Log:0 ) sẽ hiển thị một hình ảnh đơn giản nhưng đầy thông tin về vùng lân cận của Log op trong biểu đồ TensorFlow của nó trong phần Cấu trúc biểu đồ. Lưu ý hướng từ trên xuống dưới của luồng thông tin. Bản thân op được in đậm ở giữa. Ngay phía trên nó, chúng ta có thể thấy Placeholder op cung cấp đầu vào duy nhất cho Log op. Tenxor được tạo ra bởi phần giữ chỗ probs này trong danh sách Thực thi biểu đồ ở đâu? Bằng cách sử dụng màu nền màu vàng làm công cụ hỗ trợ trực quan, chúng ta có thể thấy rằng tensor probs:0 nằm phía trên tensor Log:0 ba hàng, tức là ở hàng 85.
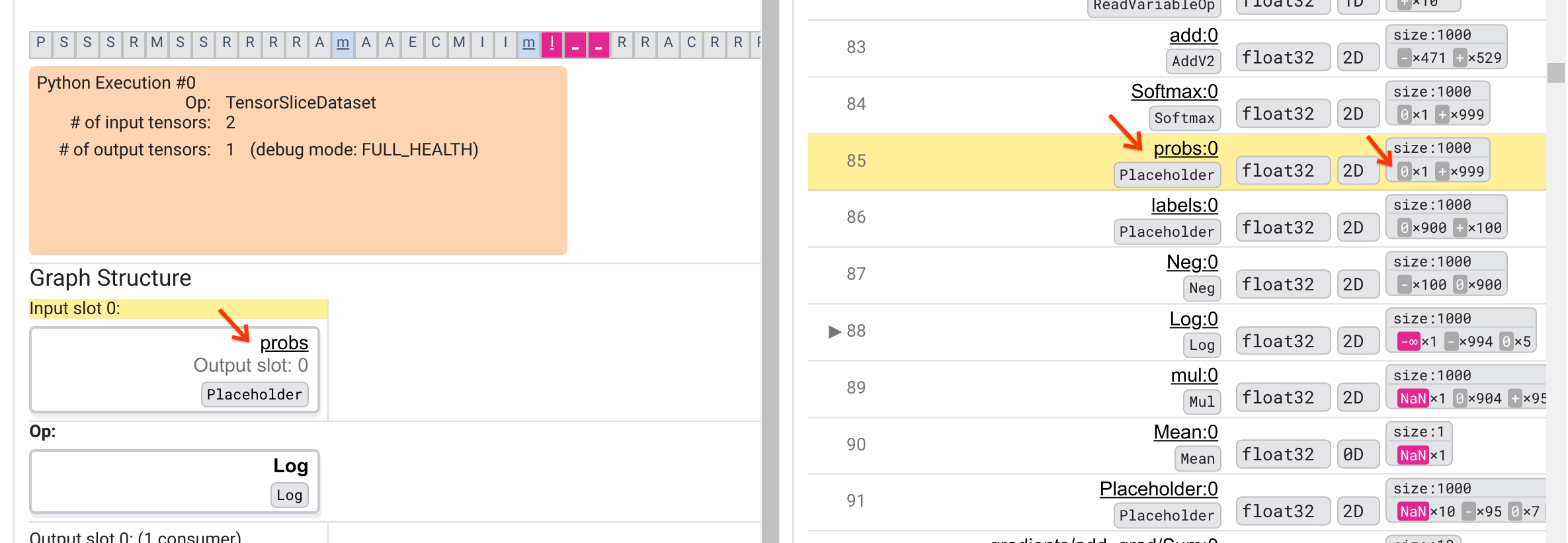
Xem xét kỹ hơn về phân tích số của tensor probs:0 ở hàng 85 sẽ tiết lộ lý do tại sao Log:0 tiêu dùng của nó tạo ra -∞: Trong số 1000 phần tử của probs:0 , một phần tử có giá trị 0. -∞ là là kết quả của việc tính logarit tự nhiên bằng 0! Nếu bằng cách nào đó chúng ta có thể đảm bảo rằng Log op chỉ được tiếp xúc với các đầu vào tích cực, thì chúng ta sẽ có thể ngăn NaN/∞ xảy ra. Điều này có thể đạt được bằng cách áp dụng tính năng cắt bớt (ví dụ: bằng cách sử dụng tf.clip_by_value() ) trên tensor probs giữ chỗ.
Chúng tôi đang tiến gần hơn đến việc giải quyết lỗi nhưng vẫn chưa hoàn thành. Để áp dụng bản sửa lỗi, chúng tôi cần biết Log op và đầu vào Placeholder của nó bắt nguồn từ đâu trong mã nguồn Python. Trình gỡ lỗi V2 cung cấp hỗ trợ hạng nhất để theo dõi các hoạt động biểu đồ và sự kiện thực thi tới nguồn của chúng. Khi chúng tôi nhấp vào tensor Log:0 trong Thực thi biểu đồ, phần Dấu vết ngăn xếp được điền bằng dấu vết ngăn xếp ban đầu của quá trình tạo Log . Dấu vết ngăn xếp hơi lớn vì nó bao gồm nhiều khung từ mã nội bộ của TensorFlow (ví dụ: gen_math_ops.py và dumping_callback.py), mà chúng ta có thể bỏ qua một cách an toàn đối với hầu hết các tác vụ gỡ lỗi. Khung quan tâm là Dòng 216 của debug_mnist_v2.py (tức là tệp Python mà chúng tôi thực sự đang cố gắng gỡ lỗi). Nhấp vào “Dòng 216” sẽ hiển thị chế độ xem dòng mã tương ứng trong phần Mã nguồn.
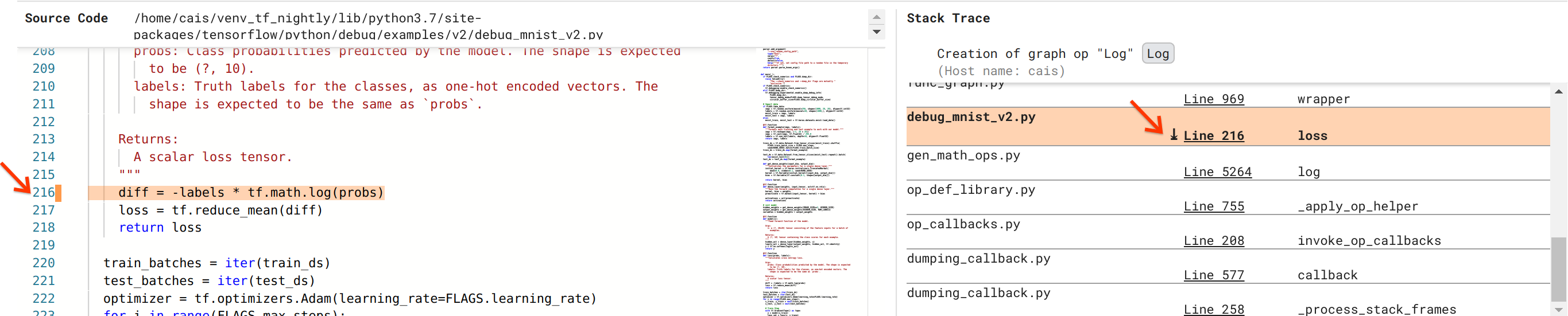
Điều này cuối cùng đưa chúng ta đến mã nguồn đã tạo ra Log có vấn đề từ đầu vào probs của nó. Đây là hàm mất entropy chéo phân loại tùy chỉnh của chúng tôi được trang trí bằng @tf.function và do đó được chuyển đổi thành biểu đồ TensorFlow. Các placeholder op probs tương ứng với đối số đầu vào đầu tiên của hàm mất. Log được tạo bằng lệnh gọi API tf.math.log().
Bản sửa lỗi cắt giảm giá trị cho lỗi này sẽ trông giống như sau:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Nó sẽ giải quyết sự mất ổn định về mặt số học trong chương trình TF2 này và khiến MLP huấn luyện thành công. Một cách tiếp cận khả thi khác để khắc phục sự mất ổn định về số là sử dụng tf.keras.losses.CategoricalCrossentropy .
Điều này kết thúc hành trình của chúng tôi từ việc quan sát lỗi mô hình TF2 đến việc thay đổi mã để sửa lỗi, được hỗ trợ bởi công cụ Debugger V2, cung cấp khả năng hiển thị đầy đủ về lịch sử thực thi biểu đồ và háo hức của chương trình TF2 được trang bị công cụ, bao gồm cả các tóm tắt bằng số của các giá trị tensor và sự liên kết giữa các op, tensor và mã nguồn ban đầu của chúng.
Khả năng tương thích phần cứng của Debugger V2
Debugger V2 hỗ trợ phần cứng đào tạo phổ thông bao gồm CPU và GPU. Đào tạo đa GPU với tf.distributed.MirroredStrategy cũng được hỗ trợ. Sự hỗ trợ cho TPU vẫn đang ở giai đoạn đầu và cần phải gọi điện
tf.config.set_soft_device_placement(True)
trước khi gọi enable_dump_debug_info() . Nó cũng có thể có những hạn chế khác đối với TPU. Nếu bạn gặp sự cố khi sử dụng Trình gỡ lỗi V2, vui lòng báo cáo lỗi trên trang sự cố GitHub của chúng tôi.
Khả năng tương thích API của Trình gỡ lỗi V2
Trình gỡ lỗi V2 được triển khai ở cấp độ tương đối thấp trong ngăn xếp phần mềm của TensorFlow và do đó tương thích với tf.keras , tf.data và các API khác được xây dựng dựa trên các cấp độ thấp hơn của TensorFlow. Trình gỡ lỗi V2 cũng tương thích ngược với TF1, mặc dù Dòng thời gian thực thi Eager sẽ trống đối với các nhật ký gỡ lỗi được tạo bởi các chương trình TF1.
Mẹo sử dụng API
Một câu hỏi thường gặp về API gỡ lỗi này là vị trí trong mã TensorFlow nên chèn lệnh gọi tới enable_dump_debug_info() . Thông thường, API phải được gọi càng sớm càng tốt trong chương trình TF2 của bạn, tốt nhất là sau các dòng nhập Python và trước khi bắt đầu xây dựng và thực thi biểu đồ. Điều này sẽ đảm bảo bao phủ đầy đủ tất cả các hoạt động và đồ thị hỗ trợ mô hình của bạn cũng như quá trình đào tạo mô hình đó.
Các tensor_debug_modes hiện được hỗ trợ là: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH và SHAPE . Chúng khác nhau về lượng thông tin được trích xuất từ mỗi tensor và chi phí hoạt động của chương trình được gỡ lỗi. Vui lòng tham khảo phần đối số trong tài liệu của enable_dump_debug_info() .
Chi phí hiệu suất
API gỡ lỗi giới thiệu chi phí hiệu năng cho chương trình TensorFlow được trang bị thiết bị. Chi phí hoạt động thay đổi tùy theo tensor_debug_mode , loại phần cứng và tính chất của chương trình TensorFlow được trang bị thiết bị. Là một điểm tham chiếu, trên GPU, chế độ NO_TENSOR bổ sung thêm 15% chi phí trong quá trình đào tạo mô hình Máy biến áp theo kích thước lô 64. Phần trăm chi phí cho các tensor_debug_modes khác cao hơn: khoảng 50% cho CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH và SHAPE chế độ. Trên CPU, chi phí hoạt động thấp hơn một chút. Trên TPU, chi phí hiện cao hơn.
Mối liên quan với các API gỡ lỗi TensorFlow khác
Lưu ý rằng TensorFlow cung cấp các công cụ và API khác để gỡ lỗi. Bạn có thể duyệt các API như vậy trong không gian tên tf.debugging.* tại trang tài liệu API. Trong số các API này, API được sử dụng thường xuyên nhất là tf.print() . Khi nào nên sử dụng Debugger V2 và khi nào nên sử dụng tf.print() ? tf.print() thuận tiện trong trường hợp
- chúng ta biết chính xác tensor nào cần in,
- chúng tôi biết chính xác vị trí trong mã nguồn để chèn các câu lệnh
tf.print()đó, - số lượng tensor như vậy không quá lớn.
Đối với các trường hợp khác (ví dụ: kiểm tra nhiều giá trị tensor, kiểm tra các giá trị tensor được tạo bởi mã nội bộ của TensorFlow và tìm kiếm nguồn gốc của sự mất ổn định về số như chúng tôi đã trình bày ở trên), Debugger V2 cung cấp cách gỡ lỗi nhanh hơn. Ngoài ra, Debugger V2 còn cung cấp một cách tiếp cận thống nhất để kiểm tra các tensor mong muốn và đồ thị. Nó cũng cung cấp thông tin về cấu trúc biểu đồ và vị trí mã, vượt quá khả năng của tf.print() .
Một API khác có thể được sử dụng để gỡ lỗi các vấn đề liên quan đến ∞ và NaN là tf.debugging.enable_check_numerics() . Không giống như enable_dump_debug_info() , enable_check_numerics() không lưu thông tin gỡ lỗi trên đĩa. Thay vào đó, nó chỉ giám sát ∞ và NaN trong thời gian chạy TensorFlow và phát hiện lỗi vị trí mã gốc ngay khi bất kỳ hoạt động nào tạo ra các giá trị số xấu như vậy. Nó có chi phí hoạt động thấp hơn so với enable_dump_debug_info() nhưng không cung cấp đầy đủ dấu vết về lịch sử thực thi của chương trình và không đi kèm giao diện người dùng đồ họa như Debugger V2.