
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
כאשר בונים מודלים של למידת מכונה, אתה צריך לבחור שונה hyperparameters , כגון שיעור הנשירה בשכבה או שיעור הלמידה. החלטות אלו משפיעות על מדדי המודל, כגון דיוק. לכן, שלב חשוב בתהליך העבודה של למידת מכונה הוא לזהות את ההיפרפרמטרים הטובים ביותר לבעיה שלך, שלעתים קרובות כרוכה בניסויים. תהליך זה מכונה "אופטימיזציית היפרפרמטרים" או "כוונון היפרפרמטרים".
לוח המחוונים של HParams ב-TensorBoard מספק מספר כלים שיעזרו בתהליך זה של זיהוי הניסוי הטוב ביותר או הקבוצות המבטיחות ביותר של היפרפרמטרים.
מדריך זה יתמקד בשלבים הבאים:
- הגדרת הניסוי וסיכום HParams
- התאם ריצות TensorFlow לרישום היפרפרמטרים ומדדים
- התחל ריצות ורשום את כולם תחת ספריית אב אחת
- דמיין את התוצאות בלוח המחוונים HParams של TensorBoard
התחל בהתקנת TF 2.0 וטעינת תוסף המחברת TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
יבא את TensorFlow ואת התוסף TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
הורד את FashionMNIST במערך ולהרחיב אותו:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. הגדרת הניסוי וסיכום הניסוי של HParams
ניסוי עם שלושה היפרפרמטרים במודל:
- מספר יחידות בשכבה הצפופה הראשונה
- שיעור הנשירה בשכבת הנשירה
- מייעל
רשום את הערכים שיש לנסות, ורשם תצורת ניסוי ל-TensorBoard. שלב זה הוא אופציונלי: אתה יכול לספק מידע תחום כדי לאפשר סינון מדויק יותר של היפרפרמטרים בממשק המשתמש, ותוכל לציין אילו מדדים יש להציג.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
אם תבחר לדלג על שלב זה, אתה יכול להשתמש מילולי מחרוזת מקום שאתה שאחרת להשתמש HParam ערך: למשל, hparams['dropout'] במקום hparams[HP_DROPOUT] .
2. התאם ריצות TensorFlow לרישום היפרפרמטרים ומדדים
הדגם יהיה די פשוט: שתי שכבות צפופות עם שכבת נשירה ביניהן. קוד האימון ייראה מוכר, למרות שההיפרפרמטרים אינם מקודדים עוד. במקום זאת, hyperparameters ניתן באופן hparams מילון בשימוש ברחבי פונקצית אימונים:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
עבור כל ריצה, רישום סיכום hparams עם הפרמטרים ההיפר והדיוק הסופי:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
בעת אימון דגמי Keras, אתה יכול להשתמש בהתקשרות חוזרת במקום לכתוב את אלה ישירות:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. התחל ריצות ורשום את כולן תחת ספריית אב אחת
כעת אתה יכול לנסות מספר ניסויים, לאמן כל אחד עם קבוצה שונה של היפרפרמטרים.
למען הפשטות, השתמש בחיפוש רשת: נסה את כל השילובים של הפרמטרים הבדידים ורק את הגבול התחתון והעליון של הפרמטר בעל הערך האמיתי. עבור תרחישים מורכבים יותר, ייתכן שיהיה יעיל יותר לבחור כל ערך היפרפרמטר באופן אקראי (זה נקרא חיפוש אקראי). ישנן שיטות מתקדמות יותר שניתן להשתמש בהן.
הפעל כמה ניסויים, שייקחו כמה דקות:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. דמיינו את התוצאות בתוסף HParams של TensorBoard
כעת ניתן לפתוח את לוח המחוונים של HParams. הפעל את TensorBoard ולחץ על "HParams" בחלק העליון.
%tensorboard --logdir logs/hparam_tuning
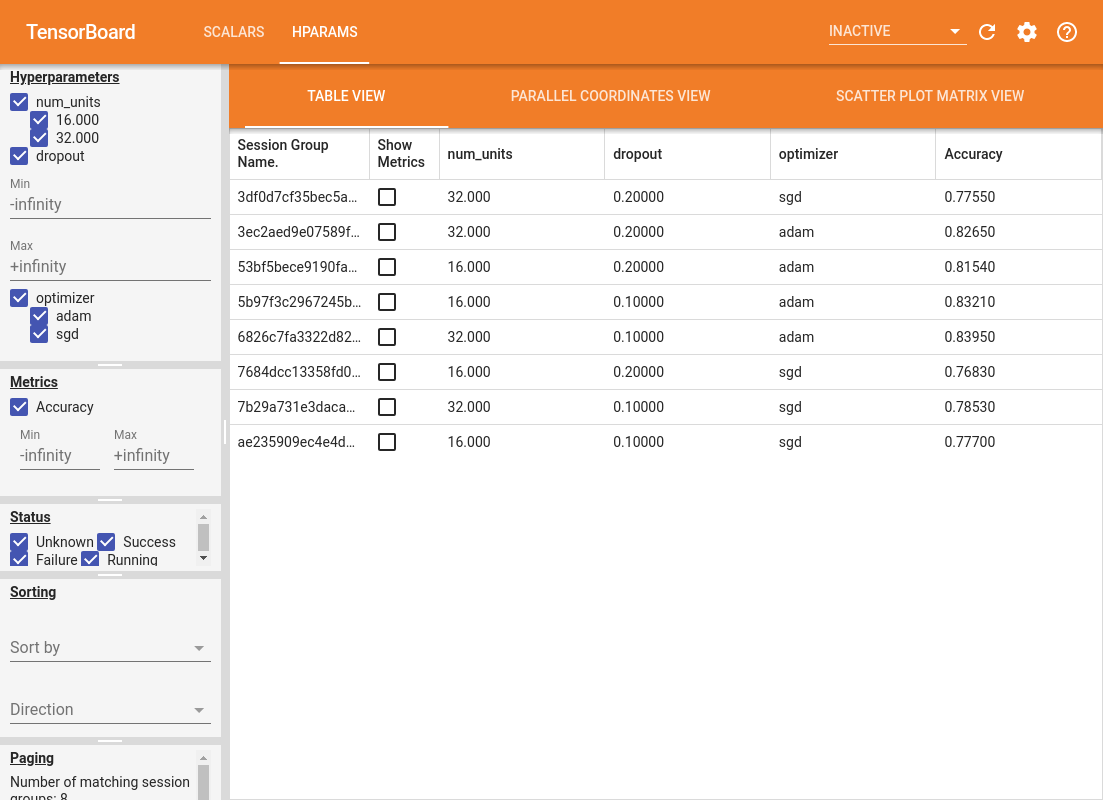
החלונית השמאלית של לוח המחוונים מספקת יכולות סינון הפעילות בכל התצוגות בלוח המחוונים של HParams:
- סנן אילו היפרפרמטרים/ערכים מוצגים בלוח המחוונים
- סנן אילו ערכי היפרפרמטר/ערכים מוצגים בלוח המחוונים
- סינון על מצב ריצה (ריצה, הצלחה,...)
- מיין לפי היפרפרמטר/מדד בתצוגת הטבלה
- מספר קבוצות הפעלות להצגה (שימושי לביצועים כאשר יש ניסויים רבים)
ללוח המחוונים של HParams יש שלוש תצוגות שונות, עם מידע שימושי מגוון:
- השולחן צפה מפרט את הריצות, hyperparameters שלהם, והמדדים שלהם.
- The View קואורדינטות במקביל מציגה כל ריצה כקו עובר ציר לכל hyperparemeter ו מטרי. לחץ וגרור את העכבר על כל ציר כדי לסמן אזור שידגיש רק את הריצות שעוברות דרכו. זה יכול להיות שימושי לזיהוי קבוצות ההיפרפרמטרים החשובות ביותר. ניתן לסדר מחדש את הצירים עצמם על ידי גרירתם.
- מגרשי המופעים צפו עלילת פיזור השוואה כול hyperparameter / מטרי עם כול מדד. זה יכול לעזור לזהות מתאמים. לחץ וגרור כדי לבחור אזור בחלקה ספציפית ולהדגיש את הפעלות הללו על פני החלקות האחרות.
ניתן ללחוץ על שורת טבלה, קו קואורדינטות מקבילות ושוק עלילת פיזור כדי לראות עלילה של המדדים כפונקציה של שלבי האימון לאותה מפגש (אם כי במדריך זה נעשה שימוש רק בשלב אחד עבור כל ריצה).
כדי להמשיך ולחקור את היכולות של לוח המחוונים של HParams, הורד קבוצה של יומנים שנוצרו מראש עם ניסויים נוספים:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
הצג את היומנים האלה ב-TensorBoard:
%tensorboard --logdir logs/hparam_demo
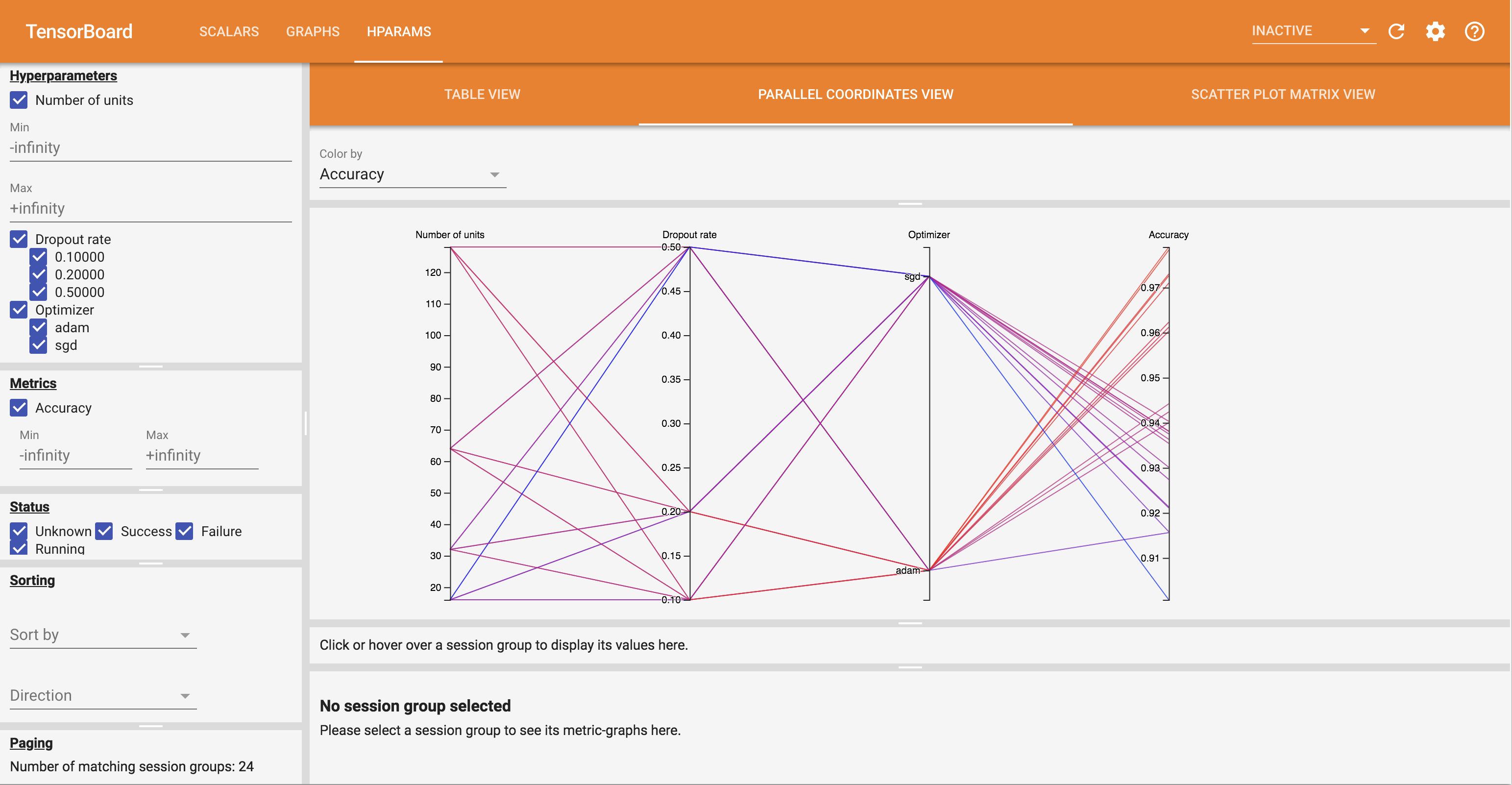
אתה יכול לנסות את התצוגות השונות בלוח המחוונים של HParams.
לדוגמה, על ידי מעבר לתצוגת הקואורדינטות המקבילות ולחיצה וגרירה על ציר הדיוק, ניתן לבחור את הריצות עם הדיוק הגבוה ביותר. כאשר ריצות אלו עוברות דרך 'אדם' בציר האופטימיזציה, אתה יכול להסיק ש'אדם' הציג ביצועים טובים יותר מ-'sgd' בניסויים אלה.