
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
মেশিন লার্নিং অ্যালগরিদমগুলি সাধারণত গণনাগতভাবে ব্যয়বহুল। আপনি আপনার মডেলের সবচেয়ে অপ্টিমাইজ করা সংস্করণটি চালাচ্ছেন তা নিশ্চিত করার জন্য আপনার মেশিন লার্নিং অ্যাপ্লিকেশনটির কার্যকারিতা পরিমাপ করা অত্যাবশ্যক৷ আপনার টেনসরফ্লো কোডের এক্সিকিউশন প্রোফাইল করতে টেনসরফ্লো প্রোফাইলার ব্যবহার করুন।
সেটআপ
from datetime import datetime
from packaging import version
import os
TensorFlow প্রোফাইলার TensorFlow এবং TensorBoard (এর সর্বশেষ সংস্করণ প্রয়োজন >=2.2 )।
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
নিশ্চিত করুন যে TensorFlow GPU অ্যাক্সেস করতে পারে।
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
TensorBoard কলব্যাক সহ একটি চিত্র শ্রেণীবিভাগ মডেল প্রশিক্ষিত করুন
এই টিউটোরিয়ালে, আপনার কর্মক্ষমতা প্রোফাইলে শ্রেণীভুক্ত ইমেজ একটি মডেল প্রশিক্ষণ দ্বারা প্রাপ্ত ক্যাপচার দ্বারা TensorFlow প্রোফাইলার ক্ষমতার অন্বেষণ MNIST ডেটা সেটটি ।
প্রশিক্ষণ ডেটা আমদানি করতে এবং প্রশিক্ষণ এবং পরীক্ষা সেটে বিভক্ত করতে TensorFlow ডেটাসেট ব্যবহার করুন।
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
পিক্সেল মান 0 এবং 1 এর মধ্যে হতে স্বাভাবিক করে প্রশিক্ষণ এবং পরীক্ষার ডেটা প্রিপ্রসেস করুন।
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
কেরাস ব্যবহার করে ইমেজ ক্লাসিফিকেশন মডেল তৈরি করুন।
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
পারফরম্যান্স প্রোফাইল ক্যাপচার করতে একটি TensorBoard কলব্যাক তৈরি করুন এবং মডেল প্রশিক্ষণের সময় এটি কল করুন।
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
মডেল প্রশিক্ষণ কর্মক্ষমতা প্রোফাইল TensorFlow প্রোফাইলার ব্যবহার করুন
টেনসরফ্লো প্রোফাইলার টেনসরবোর্ডের মধ্যে এমবেড করা আছে। Colab ম্যাজিক ব্যবহার করে TensorBoard লোড করুন এবং এটি চালু করুন। প্রোফাইল ট্যাব নেভিগেট করে কর্মক্ষমতা প্রোফাইলের দেখুন।
# Load the TensorBoard notebook extension.
%load_ext tensorboard
এই মডেলের জন্য কর্মক্ষমতা প্রোফাইল নীচের ছবির অনুরূপ।
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
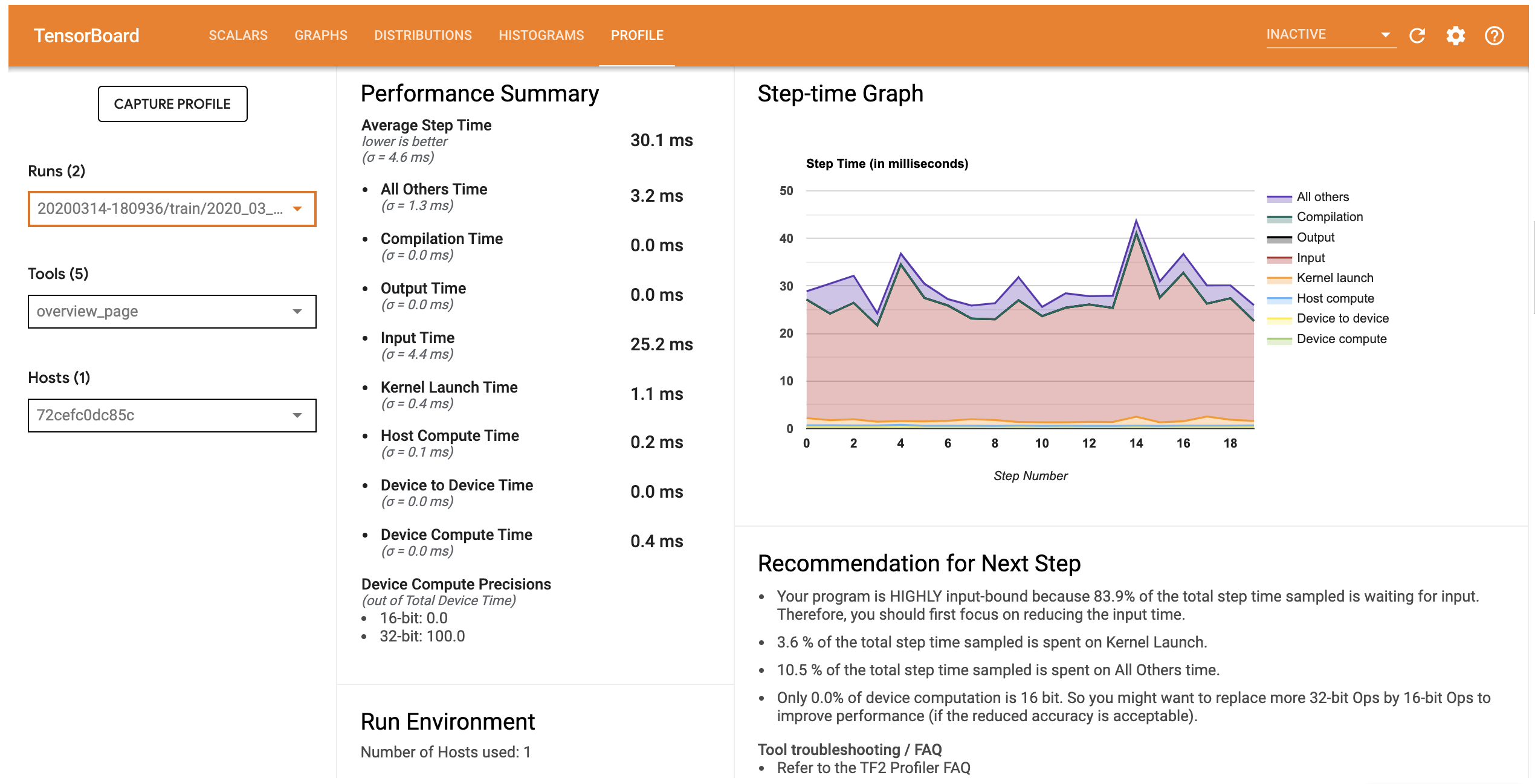
প্রোফাইল ট্যাব অবলোকন পৃষ্ঠা যা আপনি শো আপনার মডেল কর্মক্ষমতা একটি উচ্চ পর্যায়ের সারসংক্ষেপ প্রর্দশিত হবে। ডানদিকে স্টেপ-টাইম গ্রাফের দিকে তাকালে, আপনি দেখতে পাবেন যে মডেলটি অত্যন্ত ইনপুট আবদ্ধ (অর্থাৎ, এটি ডেটা ইনপুট পাইপলাইনে অনেক সময় ব্যয় করে)। ওভারভিউ পৃষ্ঠাটি আপনাকে সম্ভাব্য পরবর্তী পদক্ষেপগুলির বিষয়ে সুপারিশও দেয় যা আপনি আপনার মডেলের কার্যকারিতা অপ্টিমাইজ করতে অনুসরণ করতে পারেন।
বোঝার জন্য যেখানে কর্মক্ষমতা বোতলের ইনপুট পাইপলাইন ঘটে, সরঞ্জাম বাম ড্রপডাউন থেকে ট্রেস ভিউয়ার নির্বাচন করুন। ট্রেস ভিউয়ার আপনাকে প্রোফাইলিং সময়কালে CPU এবং GPU-তে ঘটে যাওয়া বিভিন্ন ইভেন্টের একটি টাইমলাইন দেখায়।
ট্রেস ভিউয়ার উল্লম্ব অক্ষে একাধিক ইভেন্ট গ্রুপ দেখায়। প্রতিটি ইভেন্ট গ্রুপে একাধিক অনুভূমিক ট্র্যাক রয়েছে, যা ট্রেস ইভেন্টে পূর্ণ। ট্র্যাকটি একটি থ্রেড বা একটি GPU স্ট্রীমে সম্পাদিত ইভেন্টগুলির জন্য একটি ইভেন্ট টাইমলাইন। ব্যক্তিগত ইভেন্ট হল টাইমলাইন ট্র্যাকের রঙিন, আয়তক্ষেত্রাকার ব্লক। সময় বাম থেকে ডানে চলে। কীবোর্ড শর্টকাট ব্যবহার করে ট্রেস ঘটনা নেভিগেট করুন W (জুম), S (জুম আউট), A (বাম দিকে স্ক্রোল করুন), এবং D (ডান দিকে স্ক্রোল করুন)।
একটি একক আয়তক্ষেত্র একটি ট্রেস ইভেন্ট প্রতিনিধিত্ব করে। ভাসমান টুল বারে মাউস কার্সার আইকনটি নির্বাচন করুন (অথবা কী-বোর্ড শর্টকাট ব্যবহার 1 ) এবং ট্রেস ইভেন্টে ক্লিক করেন তা বিশ্লেষণ করতে। এটি ইভেন্ট সম্পর্কে তথ্য প্রদর্শন করবে, যেমন এর শুরুর সময় এবং সময়কাল।
ক্লিক করার পাশাপাশি, আপনি ট্রেস ইভেন্টের একটি গ্রুপ নির্বাচন করতে মাউস টেনে আনতে পারেন। এটি আপনাকে একটি ইভেন্ট সারাংশ সহ সেই এলাকার সমস্ত ইভেন্টের একটি তালিকা দেবে৷ ব্যবহার করুন M নির্বাচিত ঘটনা সময় সময়কাল পরিমাপ করতে কি।
ট্রেস ইভেন্টগুলি থেকে সংগ্রহ করা হয়:
- CPU- র: CPU- র ঘটনা নামে একটি ইভেন্ট গ্রুপ অধীনে প্রদর্শিত হয়
/host:CPU। প্রতিটি ট্র্যাক CPU-তে একটি থ্রেড উপস্থাপন করে। সিপিইউ ইভেন্টের মধ্যে রয়েছে ইনপুট পাইপলাইন ইভেন্ট, জিপিইউ অপারেশন (অপ) শিডিউলিং ইভেন্ট, সিপিইউ অপ এক্সিকিউশন ইভেন্ট ইত্যাদি। - জিপিইউ: জিপিইউ ঘটনা পূর্বে সমাধান ঘটনা গ্রুপ অধীনে প্রদর্শিত হয়
/device:GPU:। প্রতিটি ইভেন্ট গ্রুপ GPU-তে একটি স্ট্রীম প্রতিনিধিত্ব করে।
ডিবাগ কর্মক্ষমতা বাধা
আপনার ইনপুট পাইপলাইনে কর্মক্ষমতা বাধাগুলি সনাক্ত করতে ট্রেস ভিউয়ার ব্যবহার করুন৷ নীচের ছবিটি পারফরম্যান্স প্রোফাইলের একটি স্ন্যাপশট।
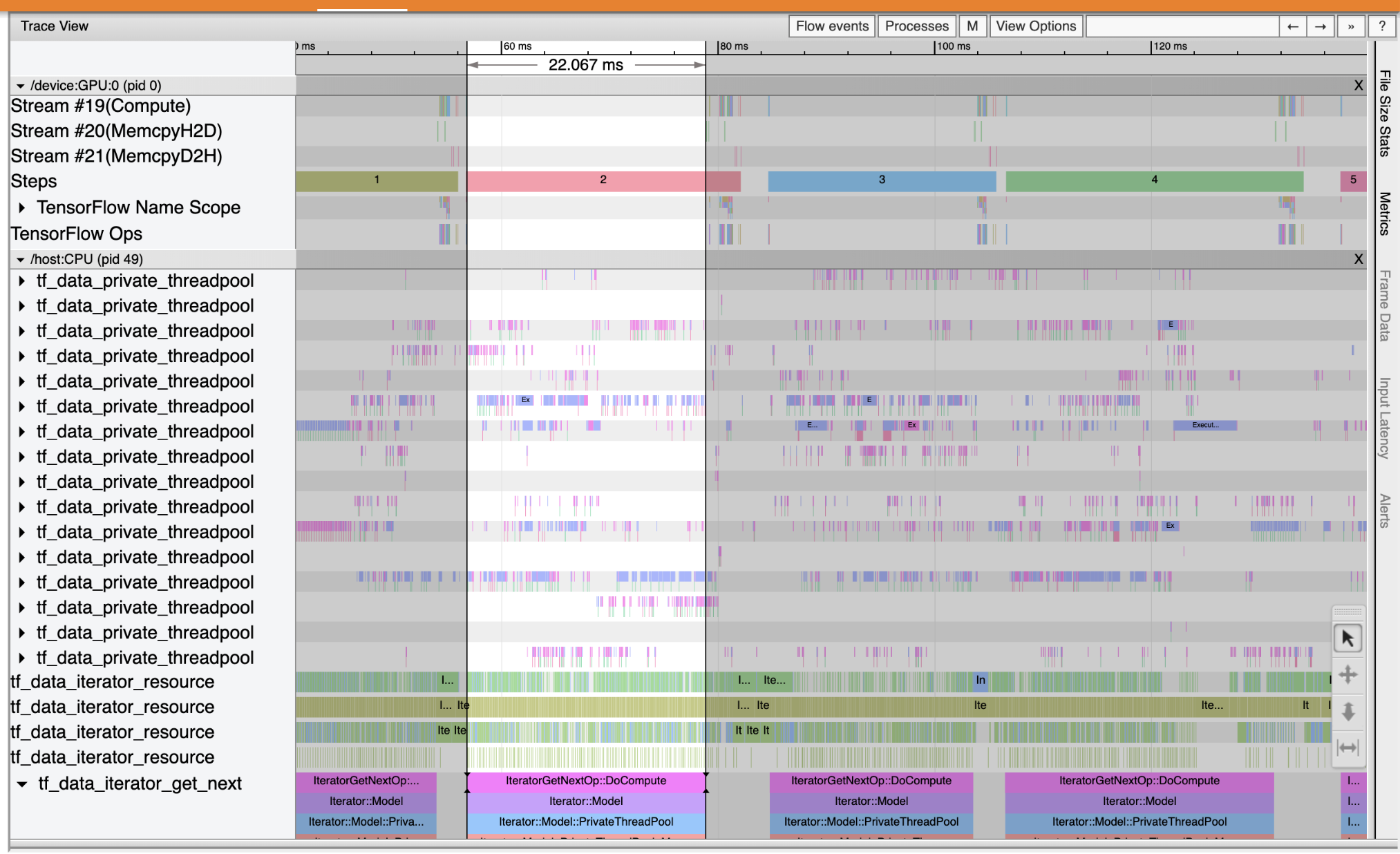
ঘটনা ট্রেস এ খুঁজছি, আপনি দেখতে পারেন যাতে GPU নিষ্ক্রিয় থাকাকালীন tf_data_iterator_get_next অপ CPU তে চলছে। এই অপটি ইনপুট ডেটা প্রক্রিয়াকরণ এবং প্রশিক্ষণের জন্য GPU-তে পাঠানোর জন্য দায়ী। একটি সাধারণ নিয়ম হিসাবে, ডিভাইসটি (GPU/TPU) সর্বদা সক্রিয় রাখা একটি ভাল ধারণা৷
ব্যবহার করুন tf.data ইনপুট পাইপলাইন নিখুত API- টি। এই ক্ষেত্রে, আসুন প্রশিক্ষণ ডেটাসেটটি ক্যাশে করি এবং GPU-এর প্রক্রিয়া করার জন্য সর্বদা ডেটা উপলব্ধ থাকে তা নিশ্চিত করতে ডেটা প্রিফেচ করি। দেখুন এখানে ব্যবহার আরও বিশদের জন্য tf.data আপনার ইনপুট পাইপলাইনগুলি নিখুত।
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
মডেলটিকে আবার প্রশিক্ষণ দিন এবং আগের থেকে কলব্যাক পুনরায় ব্যবহার করে কর্মক্ষমতা প্রোফাইল ক্যাপচার করুন৷
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
রি-লঞ্চ TensorBoard এবং আপডেট ইনপুট পাইপলাইন জন্য কর্মক্ষমতা প্রফাইল পালন করা প্রোফাইল ট্যাব খুলুন।
অপ্টিমাইজ করা ইনপুট পাইপলাইন সহ মডেলটির কার্যকারিতা প্রোফাইল নীচের চিত্রের মতো।
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
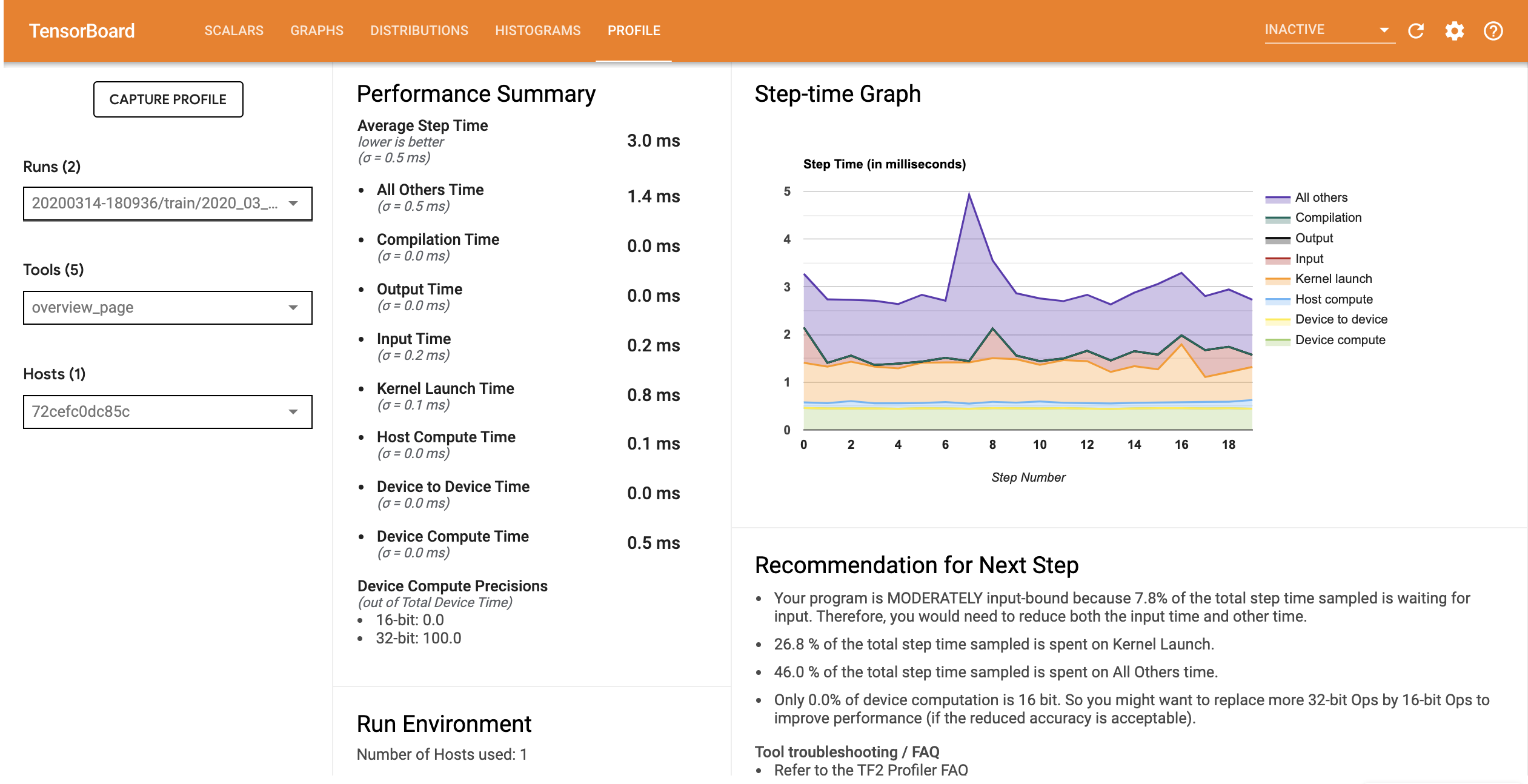
ওভারভিউ পৃষ্ঠা থেকে, আপনি দেখতে পাচ্ছেন যে ইনপুট ধাপের সময় হিসাবে গড় ধাপের সময় কমে গেছে। স্টেপ-টাইম গ্রাফ এছাড়াও নির্দেশ করে যে মডেলটি আর বেশি ইনপুট আবদ্ধ নয়। অপ্টিমাইজ করা ইনপুট পাইপলাইনের সাথে ট্রেস ইভেন্টগুলি পরীক্ষা করতে ট্রেস ভিউয়ার খুলুন।
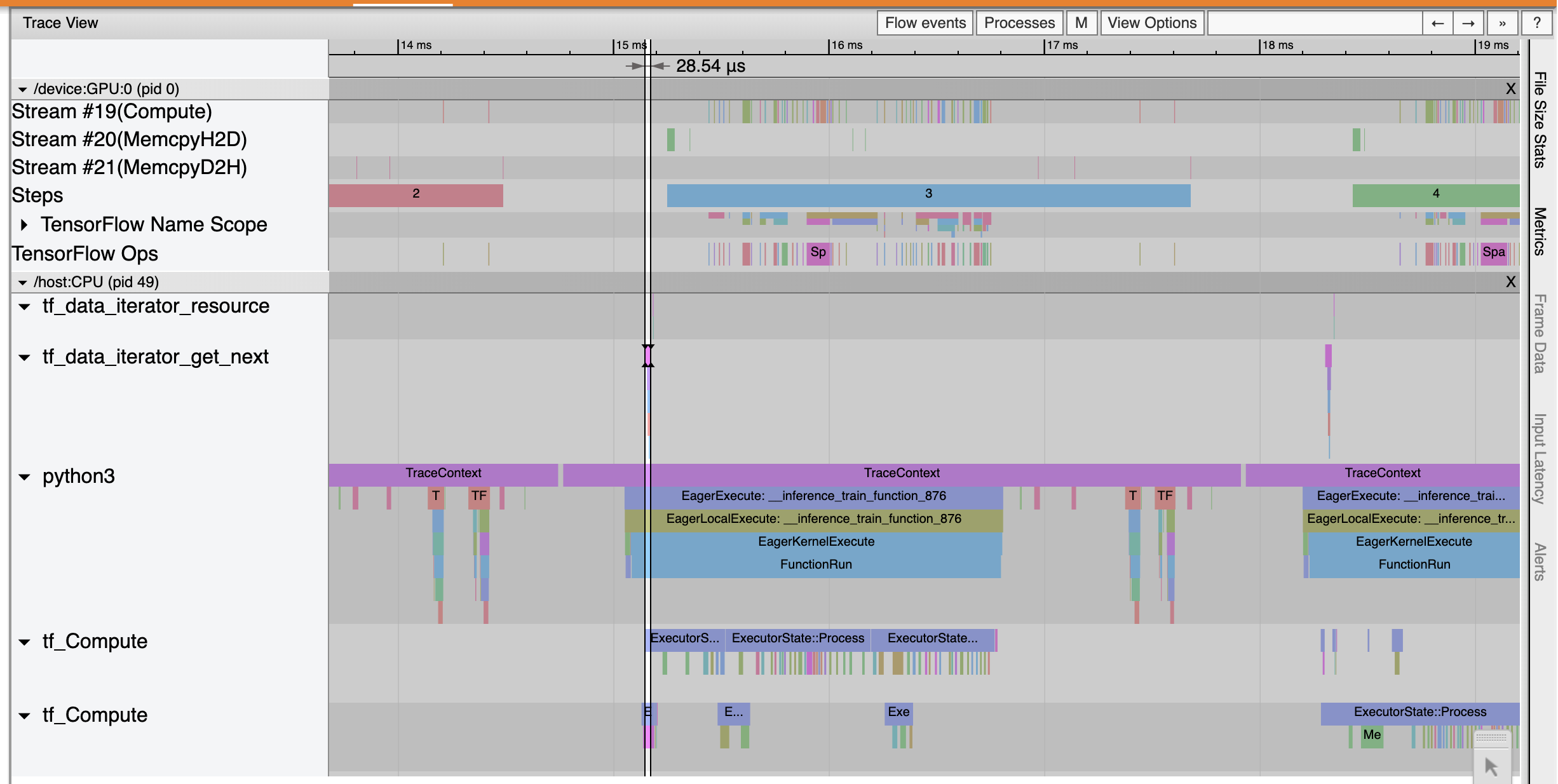
ট্রেস ভিউয়ার অনুষ্ঠান tf_data_iterator_get_next অপ অনেক দ্রুত সঞ্চালন করে। তাই GPU প্রশিক্ষণের জন্য ডেটার একটি স্থির প্রবাহ পায় এবং মডেল প্রশিক্ষণের মাধ্যমে অনেক ভালো ব্যবহার অর্জন করে।
সারসংক্ষেপ
মডেল প্রশিক্ষণ কর্মক্ষমতা প্রোফাইল এবং ডিবাগ করতে TensorFlow প্রোফাইলার ব্যবহার করুন। পড়ুন প্রোফাইলার নির্দেশিকা দেখতে মেমরি 2 পারফরমেন্স প্রোফাইলিং TensorFlow প্রোফাইলার সম্পর্কে আরো জানতে TensorFlow দেব সামিট 2020 থেকে আলাপ।