| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
TensorBoard এমবেডিং প্রজেক্টর ব্যবহার করে, আপনি গ্রাফিক্যালি উচ্চ মাত্রিক embeddings উপস্থাপন করতে পারেন। এটি আপনার এম্বেডিং স্তরগুলিকে ভিজ্যুয়ালাইজ করতে, পরীক্ষা করতে এবং বুঝতে সহায়ক হতে পারে।

এই টিউটোরিয়ালে, আপনি শিখবেন কিভাবে এই ধরনের প্রশিক্ষিত স্তরটি কল্পনা করা যায়।
সেটআপ
এই টিউটোরিয়ালটির জন্য, আমরা মুভি পর্যালোচনা ডেটা শ্রেণীবদ্ধ করার জন্য তৈরি করা একটি এমবেডিং স্তর কল্পনা করতে টেনসরবোর্ড ব্যবহার করব।
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
আইএমডিবি ডেটা
আমরা 25,000 IMDB মুভি পর্যালোচনার একটি ডেটাসেট ব্যবহার করব, যার প্রত্যেকটির একটি সেন্টিমেন্ট লেবেল (ইতিবাচক/নেতিবাচক) রয়েছে। প্রতিটি পর্যালোচনা শব্দ সূচকের (পূর্ণসংখ্যা) ক্রম হিসাবে প্রিপ্রসেসড এবং এনকোড করা হয়। সরলতার জন্য, ডেটাসেটের সামগ্রিক ফ্রিকোয়েন্সি দ্বারা শব্দগুলিকে সূচিত করা হয়, উদাহরণস্বরূপ পূর্ণসংখ্যা "3" সমস্ত পর্যালোচনাগুলিতে উপস্থিত হওয়া তৃতীয় সর্বাধিক ঘন ঘন শব্দটিকে এনকোড করে৷ এটি দ্রুত ফিল্টারিং ক্রিয়াকলাপগুলির জন্য অনুমতি দেয় যেমন: "শুধুমাত্র শীর্ষ 10,000টি সর্বাধিক সাধারণ শব্দ বিবেচনা করুন, তবে শীর্ষ 20টি সবচেয়ে সাধারণ শব্দগুলিকে বাদ দিন"।
একটি নিয়ম হিসাবে, "0" কোনো নির্দিষ্ট শব্দের জন্য দাঁড়ায় না, কিন্তু পরিবর্তে কোনো অজানা শব্দ এনকোড করতে ব্যবহৃত হয়। পরবর্তীতে টিউটোরিয়ালে, আমরা ভিজ্যুয়ালাইজেশনে "0" এর জন্য সারিটি সরিয়ে দেব।
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
কেরাস এম্বেডিং লেয়ার
একজন Keras এমবেডিং লেয়ার আপনার শব্দভান্ডার প্রতিটি শব্দের জন্য একটি এম্বেড প্রশিক্ষণের ব্যবহার করা যাবে। প্রতিটি শব্দ (বা এই ক্ষেত্রে উপ-শব্দ) একটি 16-মাত্রিক ভেক্টর (বা এমবেডিং) এর সাথে যুক্ত হবে যা মডেল দ্বারা প্রশিক্ষিত হবে।
দেখুন এই টিউটোরিয়াল শব্দ embeddings সম্পর্কে আরো জানতে।
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
টেনসরবোর্ডের জন্য ডেটা সংরক্ষণ করা হচ্ছে
টেনসরবোর্ড আপনার টেনসরফ্লো প্রকল্পের লগ থেকে টেনসর এবং মেটাডেটা পড়ে। লগ ডিরেক্টরির পাথ সঙ্গে উল্লেখ করা হয় log_dir নিচে। এই টিউটোরিয়াল, আমরা ব্যবহার করা হবে /logs/imdb-example/ ।
টেনসরবোর্ডে ডেটা লোড করার জন্য, আমাদের সেই ডিরেক্টরিতে একটি প্রশিক্ষণ চেকপয়েন্ট সংরক্ষণ করতে হবে, মেটাডেটা সহ যা মডেলটিতে আগ্রহের একটি নির্দিষ্ট স্তরের ভিজ্যুয়ালাইজেশনের অনুমতি দেয়।
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
বিশ্লেষণ
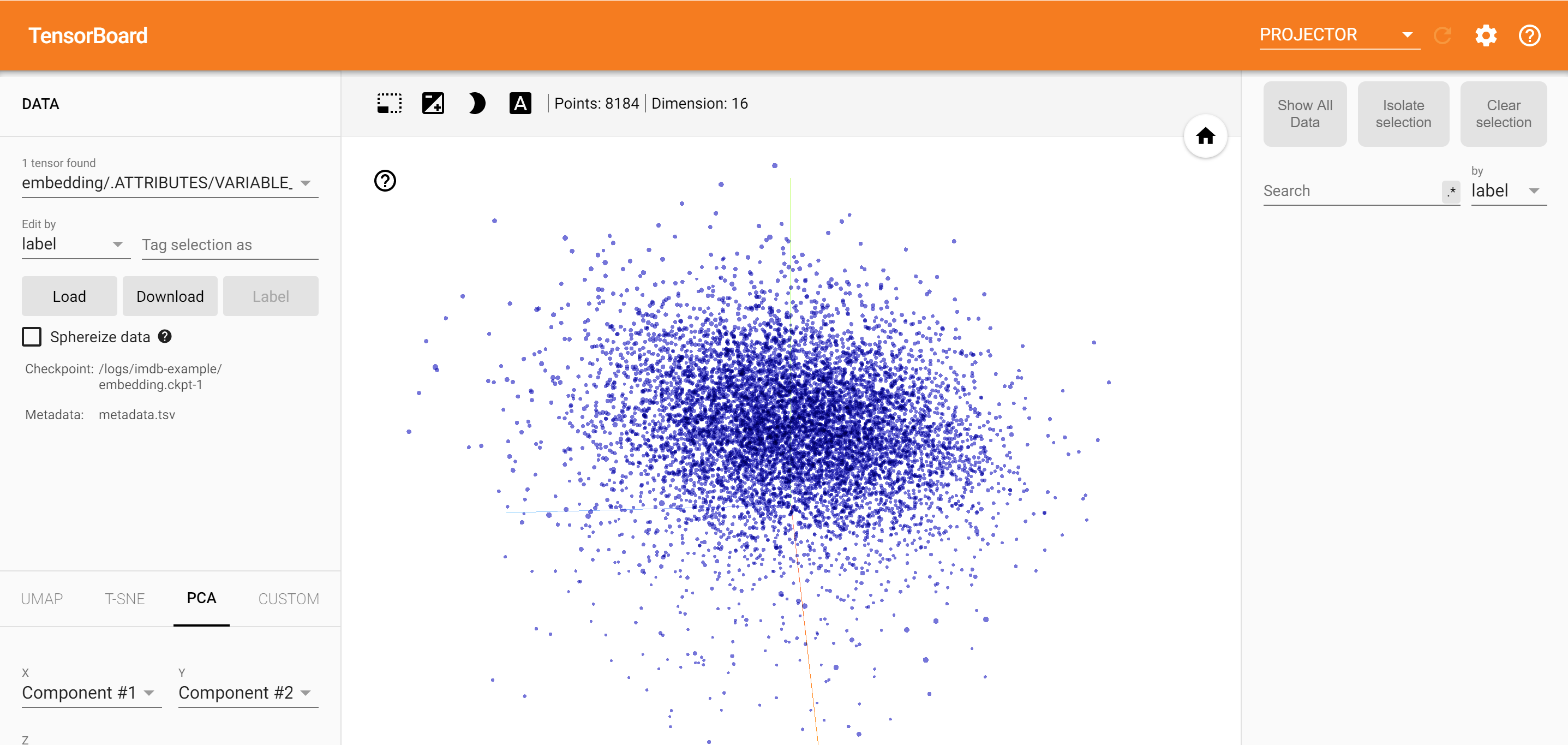
টেনসরবোর্ড প্রজেক্টর এম্বেডিং ব্যাখ্যা এবং ভিজ্যুয়ালাইজ করার জন্য একটি দুর্দান্ত সরঞ্জাম। ড্যাশবোর্ড ব্যবহারকারীদের নির্দিষ্ট পদ অনুসন্ধান করতে দেয় এবং এম্বেডিং (নিম্ন-মাত্রিক) স্থানে একে অপরের সংলগ্ন শব্দগুলিকে হাইলাইট করে। এই উদাহরণ থেকে আমরা যে ওয়েস অ্যান্ডারসন ও আলফ্রেড হিচককের উভয় বরং নিরপেক্ষ পদ, কিন্তু তারা প্রেক্ষাপটের রেফারেন্সড হয় দেখতে পারেন।
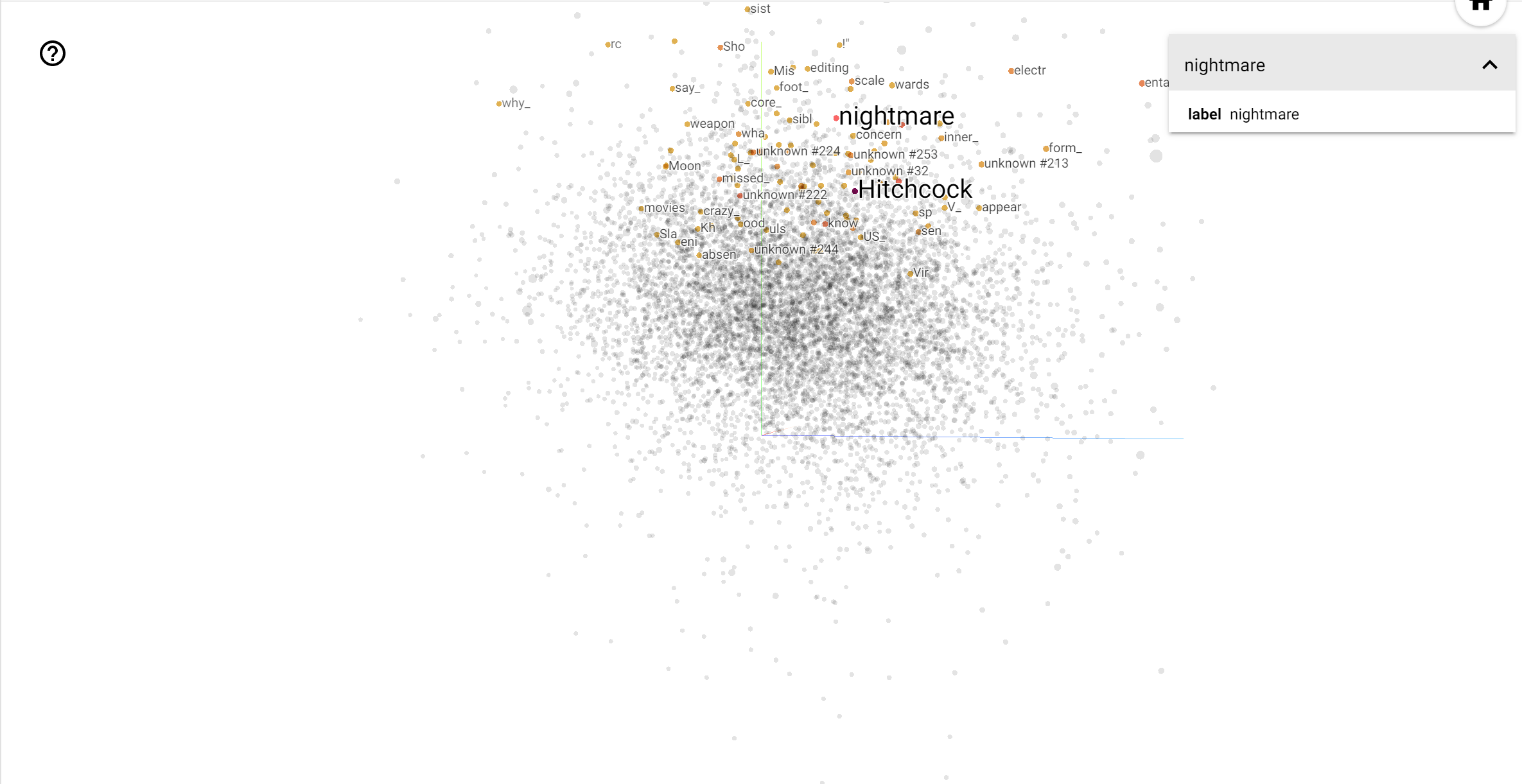
এই স্থান, হিচককের মত শব্দ কাছাকাছি nightmare , যা সত্য যে তিনি "রোমাঞ্চ মাস্টার" নামে পরিচিত কারণে সম্ভবত যেহেতু অ্যান্ডারসন শব্দ কাছাকাছি heart , যা তার নিরলসভাবে বিস্তারিত এবং হৃদয়গ্রাহী শৈলী সঙ্গে সামঞ্জস্যপূর্ণ .