
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
באמצעות המקרן והטבעת TensorBoard, אתה יכול לייצג שיבוצים ממדיים גבוהים גרפי. זה יכול להיות מועיל בהצגה, בחינה והבנה של שכבות ההטמעה שלך.

במדריך זה, תלמד כיצד לדמיין סוג זה של שכבה מאומנת.
להכין
עבור הדרכה זו, נשתמש ב-TensorBoard כדי לדמיין שכבת הטמעה שנוצרה לסיווג נתוני ביקורת סרטים.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
נתוני IMDB
אנו נשתמש במערך נתונים של 25,000 ביקורות סרטי IMDB, שלכל אחת מהן יש תווית סנטימנט (חיובית/שלילית). כל סקירה מעובדת מראש ומקודדת כרצף של מדדי מילים (מספרים שלמים). למען הפשטות, מילים מתווספות לפי התדירות הכוללת במערך הנתונים, למשל המספר השלם "3" מקודד את המילה השלישית בשכיחותה המופיעה בכל הסקירות. זה מאפשר פעולות סינון מהירות כגון: "שקול רק את 10,000 המילים הנפוצות ביותר, אך בטל את 20 המילים הנפוצות ביותר".
כמוסכמה, "0" אינו מייצג אף מילה ספציפית, אלא משמש לקידוד כל מילה לא ידועה. בהמשך המדריך, נסיר את השורה עבור "0" בהדמיה.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
שכבת הטבעה של Keras
Layer Keras והטבעה יכול לשמש כדי לאמן הטבעה עבור כל מילה אוצר המילים שלך. כל מילה (או תת-מילה במקרה זה) תקושר לווקטור (או הטבעה) 16 מימדי שיאומן על ידי המודל.
ראה מדריך זה כדי ללמוד עוד על מילת שיבוצים.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
שמירת נתונים עבור TensorBoard
TensorBoard קורא טנזורים ומטא נתונים מהיומנים של פרויקטי tensorflow שלך. השביל אלי ספריית היומן מצוין עם log_dir להלן. עבור הדרכה זו, נשתמש /logs/imdb-example/ .
על מנת לטעון את הנתונים לתוך Tensorboard, עלינו לשמור נקודת ביקורת אימון בספרייה זו, יחד עם מטא נתונים המאפשרים הדמיה של שכבת עניין ספציפית במודל.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
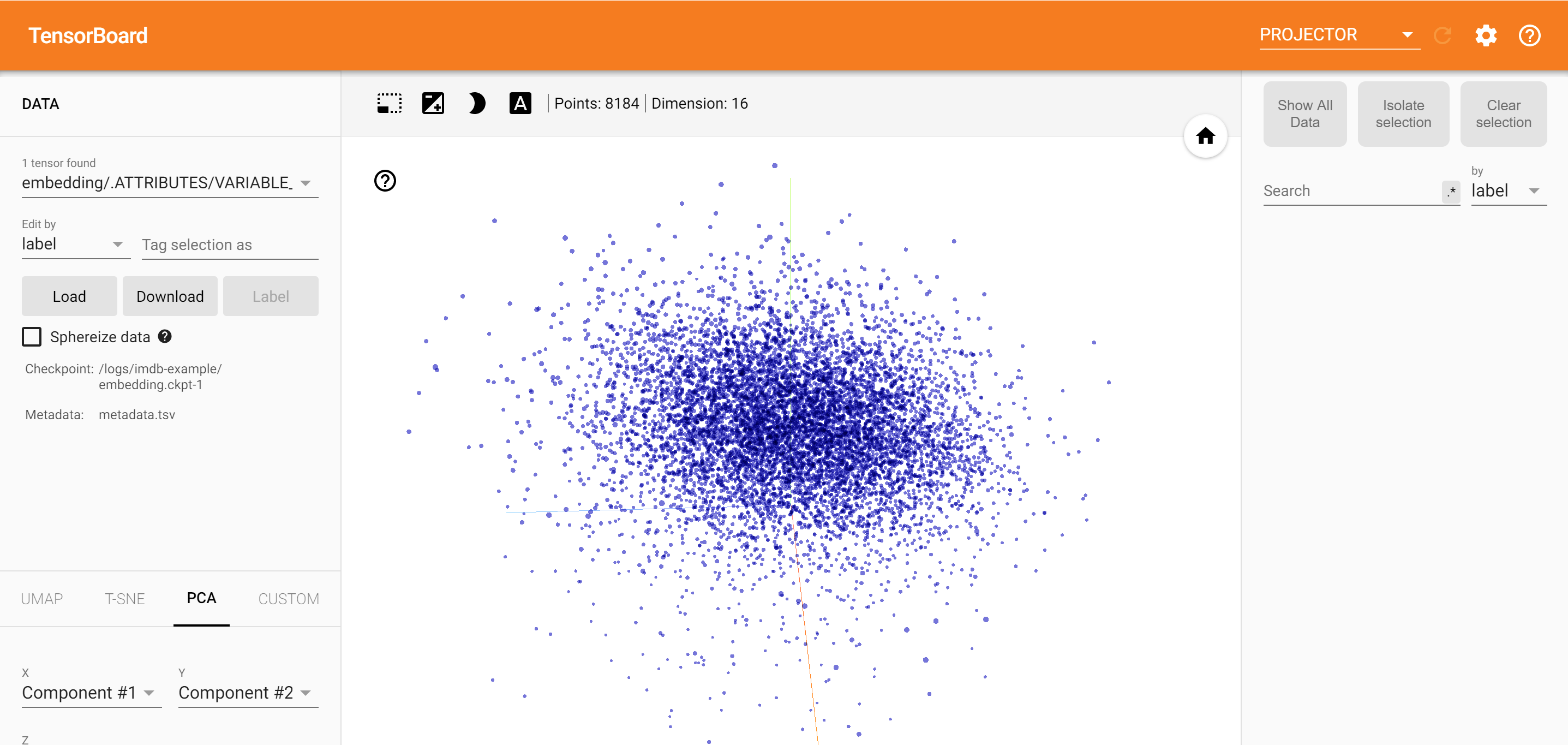
אָנָלִיזָה
מקרן TensorBoard הוא כלי נהדר לפירוש והצגה של הטבעה. לוח המחוונים מאפשר למשתמשים לחפש מונחים ספציפיים, ומדגיש מילים שצמודות זו לזו במרחב ההטמעה (בממד נמוך). מדוגמה זו ניתן לראות כי ווס אנדרסון ואלפרד היצ'קוק הן במונחים די נייטרלי, אבל הם בהפניה בהקשרים שונים.
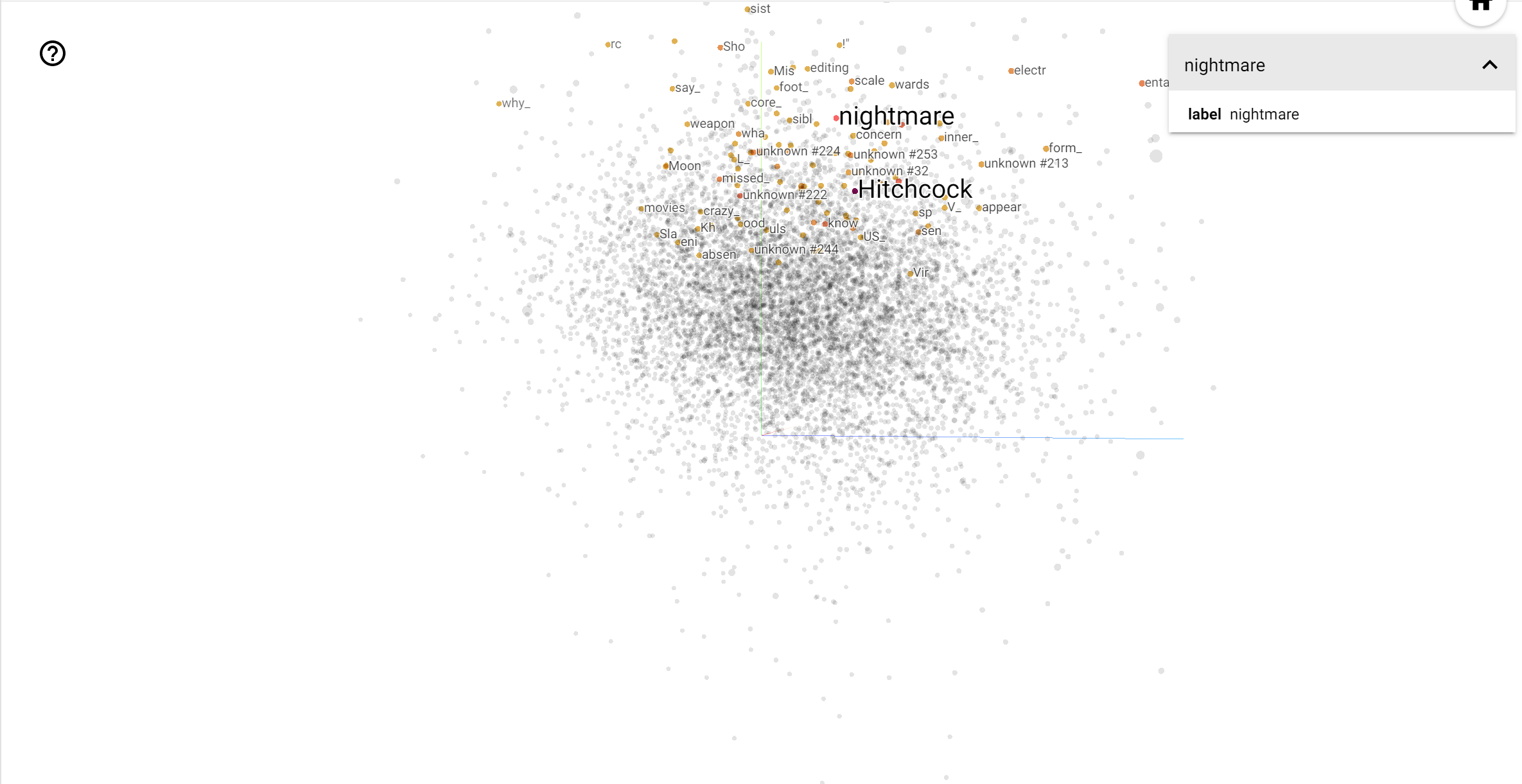
במרחב הזה, היצ'קוק הוא קרוב יותר מילות כמו nightmare , אשר צפוי בשל העובדה כי הוא ידוע בתור "ריבונו של מתח", ואילו אנדרסון קרובה למילת heart , אשר עולה בקנה אחד עם הסגנון המפורט שלו ללא הרף מחמם את הלב .
