| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Panoramica
Utilizzando l'Embedding proiettore TensorBoard, è possibile rappresentare graficamente elevati incastri dimensionali. Questo può essere utile per visualizzare, esaminare e comprendere i livelli di incorporamento.

In questo tutorial imparerai come visualizzare questo tipo di livello addestrato.
Impostare
Per questo tutorial, utilizzeremo TensorBoard per visualizzare un livello di incorporamento generato per classificare i dati di revisione del film.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Dati IMDB
Utilizzeremo un set di dati di 25.000 recensioni di film IMDB, ognuna delle quali ha un'etichetta di sentimento (positivo/negativo). Ogni recensione è preelaborata e codificata come una sequenza di indici di parole (interi). Per semplicità, le parole sono indicizzate per frequenza complessiva nel set di dati, ad esempio l'intero "3" codifica la terza parola più frequente che appare in tutte le recensioni. Ciò consente operazioni di filtraggio rapide come: "considera solo le prime 10.000 parole più comuni, ma elimina le prime 20 parole più comuni".
Per convenzione, "0" non sta per una parola specifica, ma viene invece utilizzato per codificare qualsiasi parola sconosciuta. Più avanti nel tutorial, rimuoveremo la riga per "0" nella visualizzazione.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Livello di incorporamento Keras
Un layer Keras Embedding può essere utilizzato per addestrare un'immersione per ogni parola nel vostro vocabolario. Ogni parola (o sotto-parola in questo caso) sarà associata a un vettore (o incorporamento) a 16 dimensioni che verrà addestrato dal modello.
Vedere questo tutorial per imparare di più su incastri di parole.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Salvataggio dei dati per TensorBoard
TensorBoard legge tensori e metadati dai log dei tuoi progetti tensorflow. Il percorso della directory di registro è specificato con log_dir di seguito. Per questo tutorial, useremo /logs/imdb-example/ .
Per caricare i dati in Tensorboard, dobbiamo salvare un checkpoint di addestramento in quella directory, insieme ai metadati che consentono la visualizzazione di uno specifico livello di interesse nel modello.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
Analisi
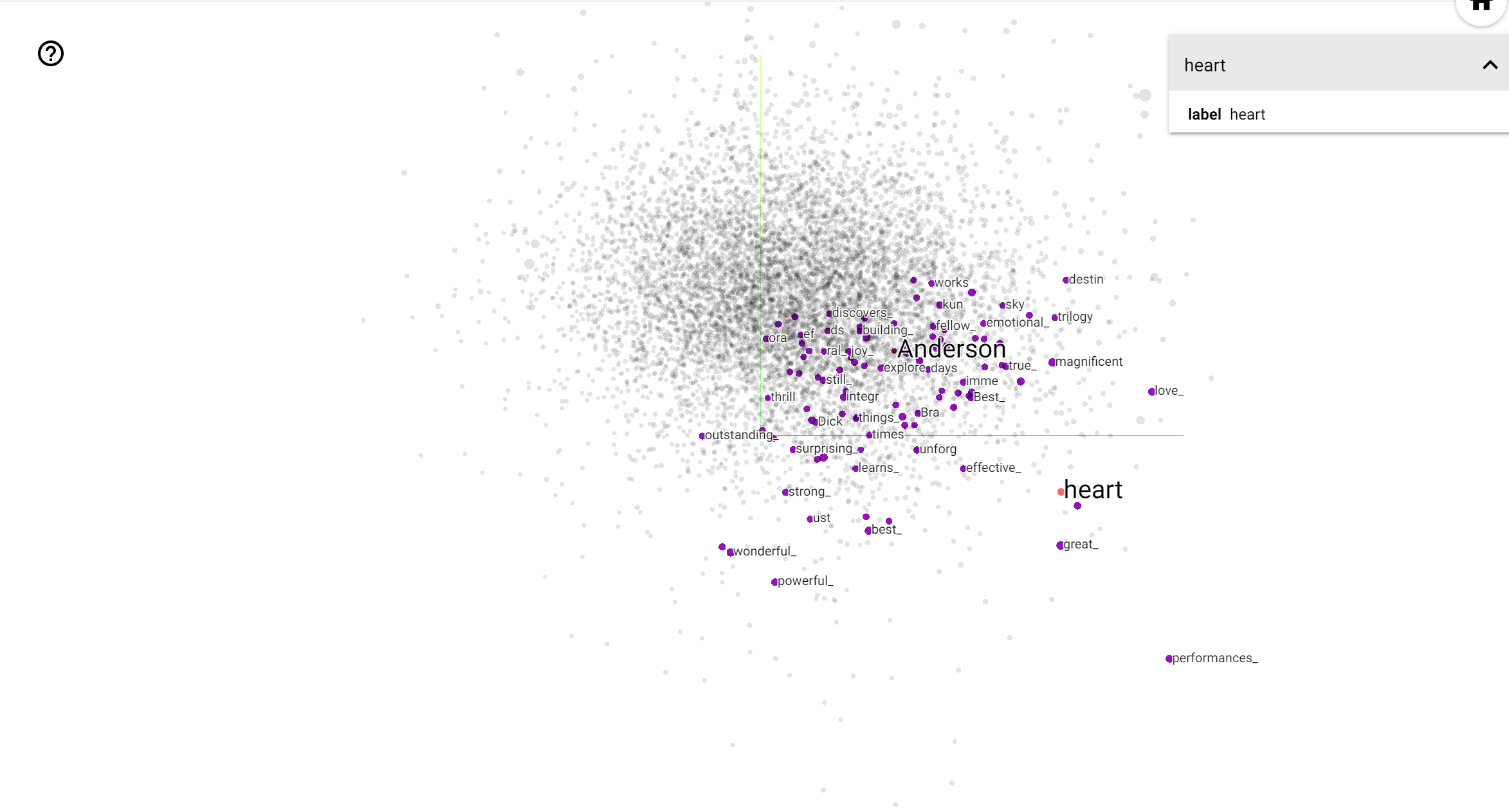
Il TensorBoard Projector è un ottimo strumento per interpretare e visualizzare l'incorporamento. La dashboard consente agli utenti di cercare termini specifici ed evidenzia le parole adiacenti l'una all'altra nello spazio di incorporamento (a bassa dimensione). Da questo esempio possiamo vedere che Wes Anderson e Alfred Hitchcock sono entrambi termini piuttosto neutri, ma che si fa riferimento in contesti diversi.
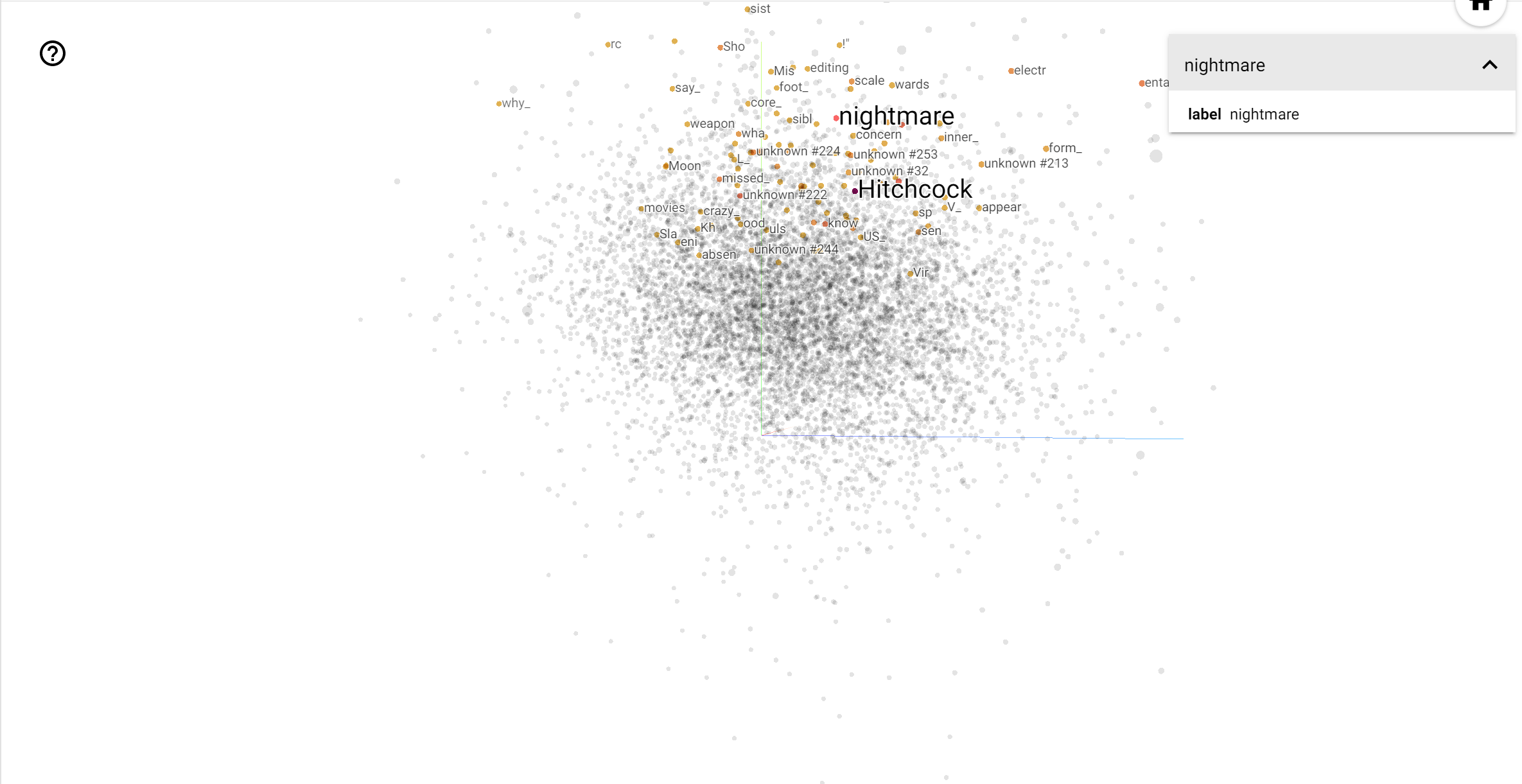
In questo spazio, Hitchcock è più vicino a parole come nightmare , che è probabilmente dovuto al fatto che egli è conosciuto come il "Master of Suspense", mentre Anderson è più vicino alla parola heart , che è coerente con il suo stile e inesorabilmente dettagliato commovente .