| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
Использование TensorBoard Встраивание проектора, вы можете графически представить высокие размерные вложения. Это может быть полезно для визуализации, изучения и понимания ваших встраиваемых слоев.

В этом руководстве вы узнаете, как визуализировать этот тип обученного слоя.
Настраивать
В этом руководстве мы будем использовать TensorBoard для визуализации слоя внедрения, созданного для классификации данных обзора фильмов.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Данные IMDB
Мы будем использовать набор данных из 25000 обзоров фильмов IMDB, каждый из которых имеет метку настроения (положительный / отрицательный). Каждый отзыв предварительно обрабатывается и кодируется как последовательность индексов слов (целых чисел). Для простоты слова индексируются по общей частоте в наборе данных, например, целое число «3» кодирует 3-е наиболее часто встречающееся слово во всех обзорах. Это позволяет выполнять такие операции быстрой фильтрации, как: «рассматривать только 10 000 самых распространенных слов, но исключать 20 самых распространенных слов».
По соглашению, «0» не означает какое-либо конкретное слово, а вместо этого используется для кодирования любого неизвестного слова. Позже в этом руководстве мы удалим строку для «0» в визуализации.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Слой встраивания Keras
Keras Встраивание слой может быть использован для подготовки вложения для каждого слова в своем словарном запасе. Каждое слово (или подслово в данном случае) будет связано с 16-мерным вектором (или вложением), который будет обучен моделью.
Смотрите этот учебник , чтобы узнать о более словах вложений.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Сохранение данных для TensorBoard
TensorBoard считывает тензоры и метаданные из журналов ваших проектов tenorflow. Путь к каталогу журнала указывается с log_dir ниже. Для этого урока мы будем использовать /logs/imdb-example/ .
Чтобы загрузить данные в Tensorboard, нам нужно сохранить контрольную точку обучения в этом каталоге вместе с метаданными, которые позволяют визуализировать определенный интересующий слой модели.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
Анализ
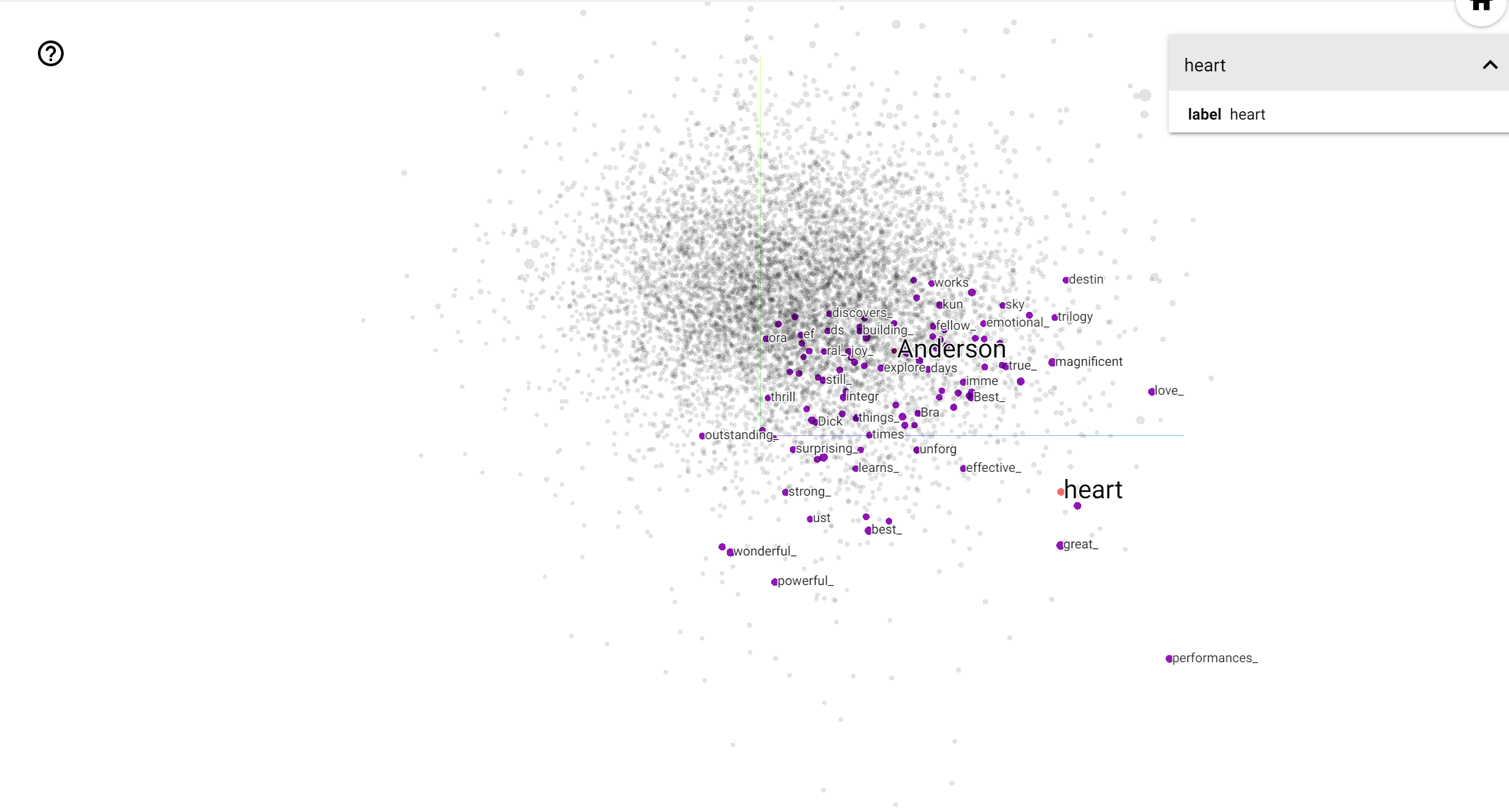
Проектор TensorBoard - отличный инструмент для интерпретации и визуализации встраивания. Панель инструментов позволяет пользователям искать определенные термины и выделять слова, которые находятся рядом друг с другом в пространстве встраивания (низкоразмерном). Из этого примера мы видим , что Уэс Андерсон и Альфред Хичкок являются довольно нейтральным, но они упоминаются в различных контекстах.
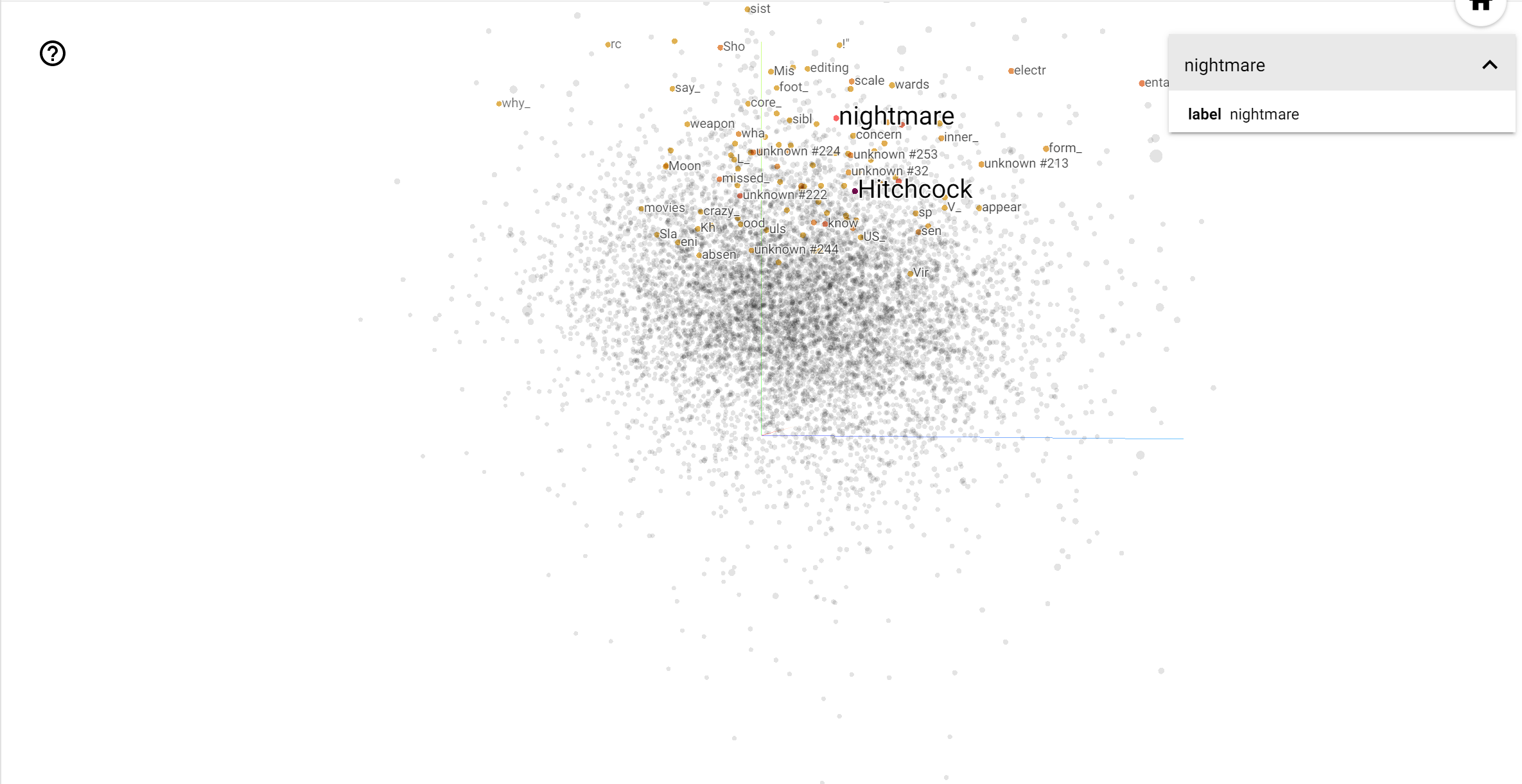
В этом пространстве, Хичкок ближе к словам , как nightmare , который, вероятно , связано с тем , что он известен как «Мастер саспенса», в то время как Андерсон ближе к слову heart , что согласуется с его неумолимо подробно и трогательный стиль .