
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini berisi pengantar penyisipan kata. Anda akan melatih penyematan kata Anda sendiri menggunakan model Keras sederhana untuk tugas klasifikasi sentimen, dan kemudian memvisualisasikannya di Proyektor Penyematan (ditunjukkan pada gambar di bawah).

Mewakili teks sebagai angka
Model pembelajaran mesin mengambil vektor (array angka) sebagai input. Saat bekerja dengan teks, hal pertama yang harus Anda lakukan adalah membuat strategi untuk mengubah string menjadi angka (atau untuk "memvektorisasi" teks) sebelum memasukkannya ke model. Di bagian ini, Anda akan melihat tiga strategi untuk melakukannya.
Pengkodean satu-panas
Sebagai ide pertama, Anda mungkin "satu-panas" menyandikan setiap kata dalam kosa kata Anda. Perhatikan kalimat "Kucing itu duduk di atas tikar". Kosakata (atau kata-kata unik) dalam kalimat ini adalah (kucing, tikar, di, duduk, itu). Untuk mewakili setiap kata, Anda akan membuat vektor nol dengan panjang yang sama dengan kosakata, lalu menempatkan satu di indeks yang sesuai dengan kata tersebut. Pendekatan ini ditunjukkan dalam diagram berikut.
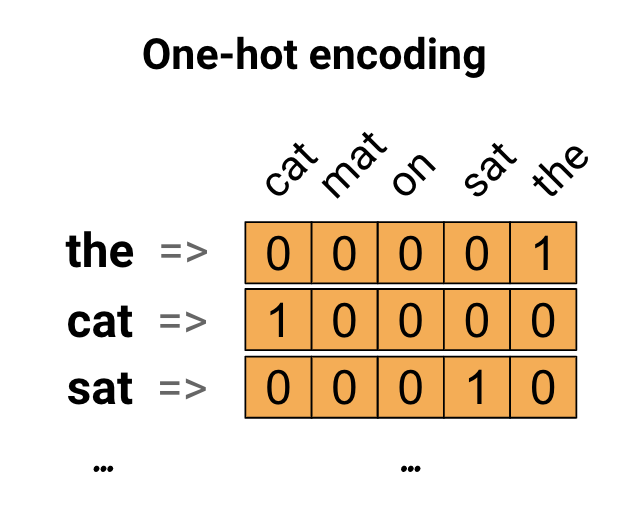
Untuk membuat vektor yang berisi penyandian kalimat, Anda dapat menggabungkan vektor satu-panas untuk setiap kata.
Encode setiap kata dengan nomor unik
Pendekatan kedua yang mungkin Anda coba adalah mengkodekan setiap kata menggunakan nomor unik. Melanjutkan contoh di atas, Anda dapat menetapkan 1 untuk "kucing", 2 untuk "tikar", dan seterusnya. Anda kemudian dapat mengkodekan kalimat "Kucing duduk di atas tikar" sebagai vektor padat seperti [5, 1, 4, 3, 5, 2]. Pendekatan ini efisien. Alih-alih vektor jarang, Anda sekarang memiliki vektor padat (di mana semua elemen penuh).
Namun, ada dua kelemahan dari pendekatan ini:
Pengkodean bilangan bulat bersifat arbitrer (tidak menangkap hubungan apa pun antara kata-kata).
Pengkodean bilangan bulat dapat menjadi tantangan bagi model untuk diinterpretasikan. Pengklasifikasi linier, misalnya, mempelajari bobot tunggal untuk setiap fitur. Karena tidak ada hubungan antara kesamaan dua kata dan kesamaan penyandiannya, kombinasi bobot fitur ini tidak bermakna.
Penyematan kata
Penyematan kata memberi kita cara untuk menggunakan representasi padat yang efisien di mana kata-kata yang serupa memiliki penyandian yang serupa. Yang penting, Anda tidak perlu menentukan pengkodean ini secara manual. Embedding adalah vektor padat nilai floating point (panjang vektor adalah parameter yang Anda tentukan). Alih-alih menentukan nilai untuk penyematan secara manual, nilai tersebut adalah parameter yang dapat dilatih (bobot yang dipelajari oleh model selama pelatihan, dengan cara yang sama seperti model mempelajari bobot untuk lapisan padat). Adalah umum untuk melihat penyematan kata yang 8-dimensi (untuk kumpulan data kecil), hingga 1024-dimensi saat bekerja dengan kumpulan data besar. Penyematan dimensi yang lebih tinggi dapat menangkap hubungan halus antar kata, tetapi membutuhkan lebih banyak data untuk dipelajari.
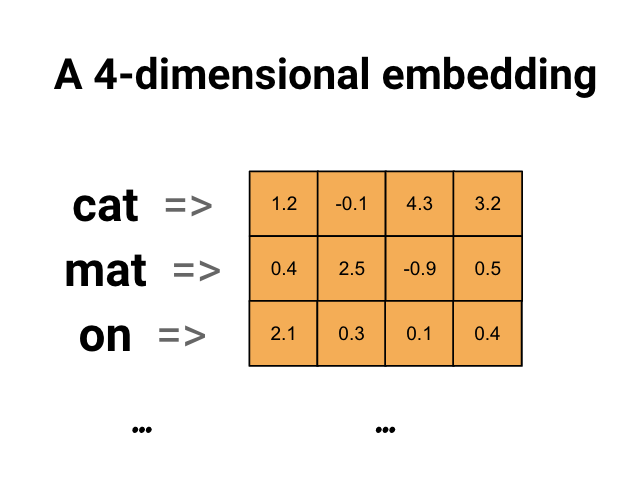
Di atas adalah diagram untuk penyisipan kata. Setiap kata direpresentasikan sebagai vektor 4 dimensi dari nilai floating point. Cara lain untuk memikirkan penyematan adalah sebagai "tabel pencarian". Setelah bobot ini dipelajari, Anda dapat menyandikan setiap kata dengan mencari vektor padat yang sesuai dengannya dalam tabel.
Mempersiapkan
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Unduh Kumpulan Data IMDb
Anda akan menggunakan Dataset Ulasan Film Besar melalui tutorial. Anda akan melatih model pengklasifikasi sentimen pada kumpulan data ini dan dalam prosesnya mempelajari penyematan dari awal. Untuk membaca selengkapnya tentang memuat kumpulan data dari awal, lihat tutorial Memuat teks .
Unduh dataset menggunakan utilitas file Keras dan lihat direktori.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Lihatlah direktori train/ . Ini memiliki folder pos dan neg dengan ulasan film berlabel positif dan negatif masing-masing. Anda akan menggunakan ulasan dari folder pos dan neg untuk melatih model klasifikasi biner.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
Direktori train juga memiliki folder tambahan yang harus dihapus sebelum membuat kumpulan data pelatihan.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Selanjutnya, buat tf.data.Dataset menggunakan tf.keras.utils.text_dataset_from_directory . Anda dapat membaca lebih lanjut tentang penggunaan utilitas ini dalam tutorial klasifikasi teks ini.
Gunakan direktori train untuk membuat set data train dan validasi dengan pembagian 20% untuk validasi.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Lihatlah beberapa ulasan film dan labelnya (1: positive, 0: negative) dari dataset kereta.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Konfigurasikan kumpulan data untuk kinerja
Ini adalah dua metode penting yang harus Anda gunakan saat memuat data untuk memastikan bahwa I/O tidak menjadi pemblokiran.
.cache() menyimpan data dalam memori setelah dimuat dari disk. Ini akan memastikan kumpulan data tidak menjadi hambatan saat melatih model Anda. Jika kumpulan data Anda terlalu besar untuk dimasukkan ke dalam memori, Anda juga dapat menggunakan metode ini untuk membuat cache di disk yang berkinerja baik, yang lebih efisien untuk dibaca daripada banyak file kecil.
.prefetch() tumpang tindih prapemrosesan data dan eksekusi model saat pelatihan.
Anda dapat mempelajari lebih lanjut tentang kedua metode tersebut, serta cara menyimpan data ke dalam cache di panduan kinerja data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Menggunakan lapisan Embedding
Keras memudahkan penggunaan penyisipan kata. Lihatlah lapisan Embedding .
Lapisan Embedding dapat dipahami sebagai tabel pencarian yang memetakan dari indeks bilangan bulat (yang merupakan singkatan dari kata-kata tertentu) ke vektor padat (penyematannya). Dimensi (atau lebar) penyematan adalah parameter yang dapat Anda coba untuk melihat apa yang bekerja dengan baik untuk masalah Anda, sama seperti Anda akan bereksperimen dengan jumlah neuron dalam lapisan Padat.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Saat Anda membuat layer Embedding, bobot untuk embedding diinisialisasi secara acak (sama seperti layer lainnya). Selama pelatihan, mereka secara bertahap disesuaikan melalui backpropagation. Setelah dilatih, penyematan kata yang dipelajari akan secara kasar mengkodekan kesamaan antara kata-kata (seperti yang dipelajari untuk masalah spesifik model Anda dilatih).
Jika Anda meneruskan bilangan bulat ke lapisan penyematan, hasilnya akan menggantikan setiap bilangan bulat dengan vektor dari tabel penyematan:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Untuk masalah teks atau urutan, lapisan Embedding mengambil tensor 2D bilangan bulat, berbentuk (samples, sequence_length) , di mana setiap entri adalah urutan bilangan bulat. Itu dapat menanamkan urutan panjang variabel. Anda dapat memasukkan lapisan penyematan di atas kumpulan dengan bentuk (32, 10) (kumpulan 32 urutan dengan panjang 10) atau (64, 15) (kumpulan 64 urutan dengan panjang 15).
Tensor yang dikembalikan memiliki satu sumbu lebih banyak daripada input, vektor penyematan disejajarkan di sepanjang sumbu terakhir yang baru. Berikan batch input (2, 3) dan outputnya adalah (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Saat diberi sekumpulan urutan sebagai input, lapisan penyematan mengembalikan tensor titik mengambang 3D, berbentuk (samples, sequence_length, embedding_dimensionality) . Untuk mengkonversi dari urutan panjang variabel ini ke representasi tetap ada berbagai pendekatan standar. Anda dapat menggunakan lapisan RNN, Attention, atau pooling sebelum meneruskannya ke lapisan Padat. Tutorial ini menggunakan pooling karena ini yang paling sederhana. Klasifikasi Teks dengan tutorial RNN adalah langkah selanjutnya yang bagus.
Pra-pemrosesan teks
Selanjutnya, tentukan langkah-langkah prapemrosesan kumpulan data yang diperlukan untuk model klasifikasi sentimen Anda. Inisialisasi layer TextVectorization dengan parameter yang diinginkan untuk membuat vektor ulasan film. Anda dapat mempelajari lebih lanjut tentang menggunakan lapisan ini dalam tutorial Klasifikasi Teks .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Buat model klasifikasi
Gunakan Keras Sequential API untuk menentukan model klasifikasi sentimen. Dalam hal ini adalah model gaya "kantong kata-kata yang berkelanjutan".
- Lapisan
TextVectorizationmengubah string menjadi indeks kosakata. Anda telah menginisialisasivectorize_layersebagai layer TextVectorization dan membangun kosakatanya dengan memanggiladaptpadatext_ds. Sekarang vectorize_layer dapat digunakan sebagai lapisan pertama dari model klasifikasi ujung-ke-ujung Anda, memasukkan string yang diubah ke dalam lapisan Embedding. Lapisan
Embeddingmengambil kosakata yang dikodekan integer dan mencari vektor embedding untuk setiap indeks kata. Vektor-vektor ini dipelajari sebagai model kereta. Vektor menambahkan dimensi ke larik keluaran. Dimensi yang dihasilkan adalah:(batch, sequence, embedding).Lapisan
GlobalAveragePooling1Dmengembalikan vektor keluaran dengan panjang tetap untuk setiap contoh dengan rata-rata pada dimensi urutan. Ini memungkinkan model untuk menangani input dengan panjang variabel, dengan cara yang sesederhana mungkin.Vektor keluaran dengan panjang tetap disalurkan melalui lapisan yang terhubung penuh (
Dense) dengan 16 unit tersembunyi.Lapisan terakhir terhubung erat dengan simpul keluaran tunggal.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Kompilasi dan latih modelnya
Anda akan menggunakan TensorBoard untuk memvisualisasikan metrik termasuk kehilangan dan akurasi. Buat tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Kompilasi dan latih model menggunakan pengoptimal Adam dan kerugian BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Dengan pendekatan ini, model mencapai akurasi validasi sekitar 78% (perhatikan bahwa modelnya overfitting karena akurasi pelatihan lebih tinggi).
Anda dapat melihat ringkasan model untuk mempelajari lebih lanjut tentang setiap lapisan model.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Visualisasikan metrik model di TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
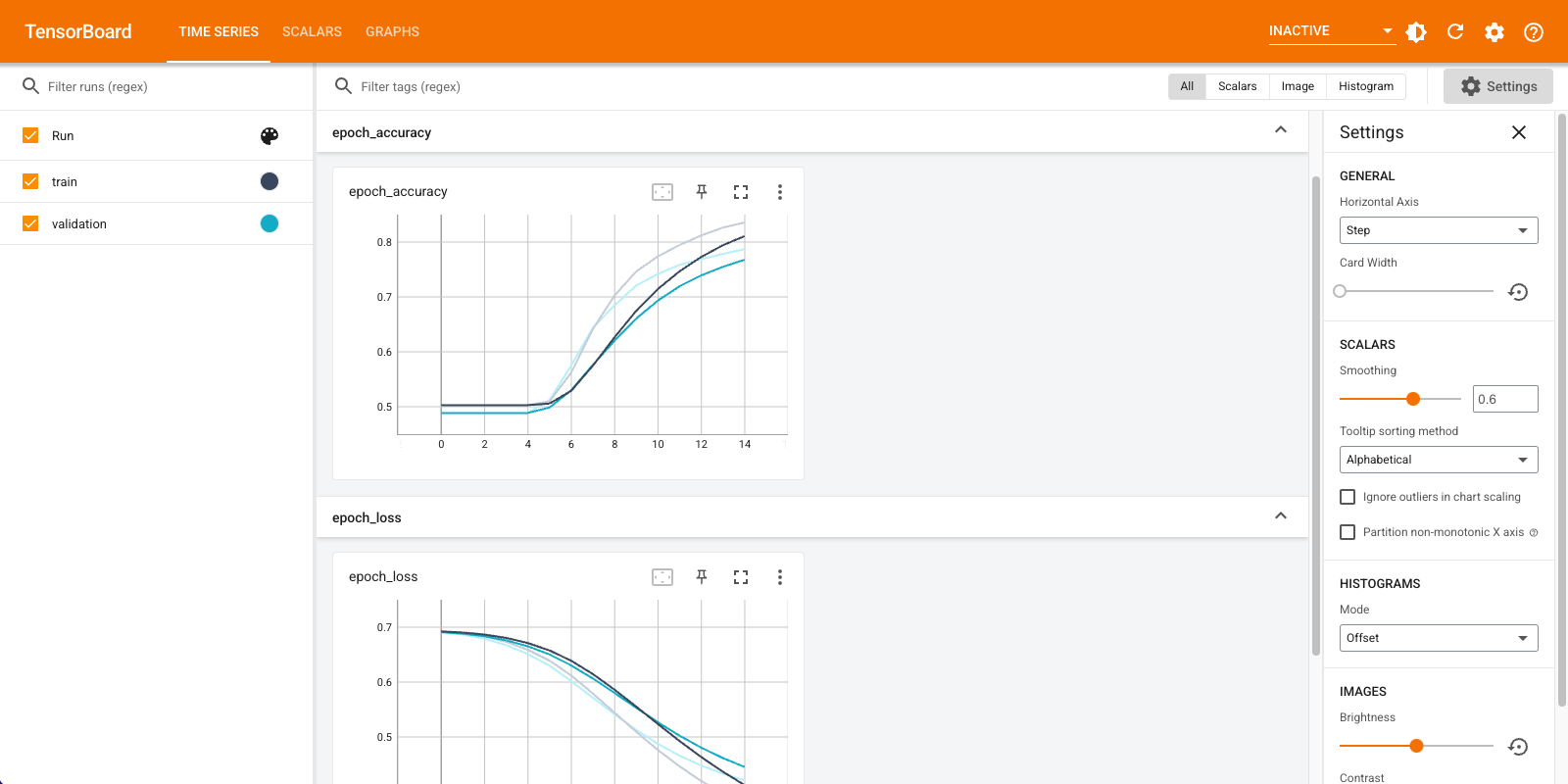
Ambil penyematan kata yang terlatih dan simpan ke disk
Selanjutnya, ambil kata yang disematkan yang dipelajari selama pelatihan. Embeddings adalah bobot dari lapisan Embedding dalam model. Matriks bobot berbentuk (vocab_size, embedding_dimension) .
Dapatkan bobot dari model menggunakan get_layer() dan get_weights() . Fungsi get_vocabulary() menyediakan kosakata untuk membangun file metadata dengan satu token per baris.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Tulis bobot ke disk. Untuk menggunakan Embedding Projector , Anda akan mengunggah dua file dalam format yang dipisahkan tab: file vektor (berisi embedding), dan file meta data (berisi kata-kata).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Jika Anda menjalankan tutorial ini di Colaboratory , Anda dapat menggunakan cuplikan berikut untuk mengunduh file-file ini ke mesin lokal Anda (atau menggunakan browser file, View -> Table of Contents -> File browser ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Visualisasikan embeddings
Untuk memvisualisasikan penyematan, unggah ke proyektor penyematan.
Buka Embedding Projector (ini juga dapat berjalan di instance TensorBoard lokal).
Klik "Muat data".
Unggah dua file yang Anda buat di atas:
vecs.tsvdanmeta.tsv.
Penyematan yang telah Anda latih sekarang akan ditampilkan. Anda dapat mencari kata-kata untuk menemukan tetangga terdekat mereka. Misalnya, coba telusuri "cantik". Anda mungkin melihat tetangga seperti "luar biasa".
Langkah selanjutnya
Tutorial ini telah menunjukkan kepada Anda cara melatih dan memvisualisasikan penyisipan kata dari awal pada kumpulan data kecil.
Untuk melatih penyisipan kata menggunakan algoritma Word2Vec, coba tutorial Word2Vec .
Untuk mempelajari lebih lanjut tentang pemrosesan teks tingkat lanjut, baca model Transformer untuk pemahaman bahasa .