
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini mendemonstrasikan klasifikasi teks mulai dari file teks biasa yang disimpan di disk. Anda akan melatih pengklasifikasi biner untuk melakukan analisis sentimen pada kumpulan data IMDB. Di akhir buku catatan, ada latihan untuk Anda coba, di mana Anda akan melatih pengklasifikasi multi-kelas untuk memprediksi tag untuk pertanyaan pemrograman di Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Analisis sentimen
Notebook ini melatih model analisis sentimen untuk mengklasifikasikan ulasan film sebagai positif atau negatif , berdasarkan teks ulasan. Ini adalah contoh klasifikasi biner — atau dua kelas —, jenis masalah pembelajaran mesin yang penting dan dapat diterapkan secara luas.
Anda akan menggunakan Kumpulan Data Ulasan Film Besar yang berisi teks dari 50.000 ulasan film dari Database Film Internet . Ini dibagi menjadi 25.000 ulasan untuk pelatihan dan 25.000 ulasan untuk pengujian. Set pelatihan dan pengujian seimbang , artinya berisi jumlah ulasan positif dan negatif yang sama.
Unduh dan jelajahi kumpulan data IMDB
Mari unduh dan ekstrak dataset, lalu jelajahi struktur direktori.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
Direktori aclImdb/train/pos dan aclImdb/train/neg berisi banyak file teks, yang masing-masing merupakan ulasan film tunggal. Mari kita lihat salah satunya.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Muat kumpulan data
Selanjutnya, Anda akan memuat data dari disk dan menyiapkannya ke dalam format yang sesuai untuk pelatihan. Untuk melakukannya, Anda akan menggunakan utilitas text_dataset_from_directory yang berguna, yang mengharapkan struktur direktori sebagai berikut.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Untuk menyiapkan kumpulan data untuk klasifikasi biner, Anda memerlukan dua folder pada disk, yang sesuai dengan class_a dan class_b . Ini akan menjadi ulasan film positif dan negatif, yang dapat ditemukan di aclImdb/train/pos dan aclImdb/train/neg . Karena dataset IMDB berisi folder tambahan, Anda akan menghapusnya sebelum menggunakan utilitas ini.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Selanjutnya, Anda akan menggunakan utilitas text_dataset_from_directory untuk membuat tf.data.Dataset berlabel . tf.data adalah kumpulan alat yang ampuh untuk bekerja dengan data.
Saat menjalankan eksperimen pembelajaran mesin, praktik terbaik adalah membagi set data Anda menjadi tiga bagian: train , validation , dan test .
Set data IMDB telah dibagi menjadi pelatihan dan pengujian, tetapi tidak memiliki set validasi. Mari buat set validasi menggunakan pemisahan 80:20 dari data pelatihan dengan menggunakan argumen validation_split di bawah ini.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Seperti yang Anda lihat di atas, ada 25.000 contoh di folder pelatihan, di mana Anda akan menggunakan 80% (atau 20.000) untuk pelatihan. Seperti yang akan Anda lihat sebentar lagi, Anda dapat melatih model dengan meneruskan kumpulan data langsung ke model.fit . Jika Anda baru tf.data , Anda juga dapat mengulangi set data dan mencetak beberapa contoh sebagai berikut.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Perhatikan ulasan berisi teks mentah (dengan tanda baca dan tag HTML sesekali seperti <br/> ). Anda akan menunjukkan cara menanganinya di bagian berikut.
Labelnya adalah 0 atau 1. Untuk melihat mana yang sesuai dengan ulasan film positif dan negatif, Anda dapat memeriksa properti class_names pada dataset.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Selanjutnya, Anda akan membuat dataset validasi dan pengujian. Anda akan menggunakan sisa 5.000 ulasan dari set pelatihan untuk validasi.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Siapkan dataset untuk pelatihan
Selanjutnya, Anda akan membuat standar, tokenize, dan vektorisasi data menggunakan lapisan tf.keras.layers.TextVectorization yang berguna.
Standardisasi mengacu pada pra-pemrosesan teks, biasanya untuk menghapus tanda baca atau elemen HTML untuk menyederhanakan kumpulan data. Tokenisasi mengacu pada pemisahan string menjadi token (misalnya, memisahkan kalimat menjadi kata-kata individual, dengan memisahkan spasi). Vektorisasi mengacu pada konversi token menjadi angka sehingga dapat dimasukkan ke dalam jaringan saraf. Semua tugas ini dapat diselesaikan dengan lapisan ini.
Seperti yang Anda lihat di atas, ulasan berisi berbagai tag HTML seperti <br /> . Tag ini tidak akan dihapus oleh standardizer default di lapisan TextVectorization (yang mengubah teks menjadi huruf kecil dan menghapus tanda baca secara default, tetapi tidak menghapus HTML). Anda akan menulis fungsi standarisasi khusus untuk menghapus HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Selanjutnya, Anda akan membuat layer TextVectorization . Anda akan menggunakan lapisan ini untuk membakukan, menandai, dan membuat vektor data kami. Anda mengatur output_mode ke int untuk membuat indeks integer unik untuk setiap token.
Perhatikan bahwa Anda menggunakan fungsi pemisahan default, dan fungsi standarisasi khusus yang Anda tetapkan di atas. Anda juga akan menentukan beberapa konstanta untuk model, seperti sequence_length maksimum yang eksplisit, yang akan menyebabkan layer mengisi atau memotong urutan ke nilai sequence_length yang tepat.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Selanjutnya, Anda akan memanggil adapt agar sesuai dengan status lapisan prapemrosesan ke kumpulan data. Ini akan menyebabkan model membangun indeks string ke bilangan bulat.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Mari kita buat sebuah fungsi untuk melihat hasil dari penggunaan layer ini untuk melakukan preprocess beberapa data.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Seperti yang Anda lihat di atas, setiap token telah diganti dengan bilangan bulat. Anda dapat mencari token (string) yang terkait dengan setiap bilangan bulat dengan memanggil .get_vocabulary() pada layer.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Anda hampir siap untuk melatih model Anda. Sebagai langkah prapemrosesan terakhir, Anda akan menerapkan layer TextVectorization yang Anda buat sebelumnya ke dataset kereta, validasi, dan pengujian.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Konfigurasikan kumpulan data untuk kinerja
Ini adalah dua metode penting yang harus Anda gunakan saat memuat data untuk memastikan bahwa I/O tidak menjadi pemblokiran.
.cache() menyimpan data dalam memori setelah dimuat dari disk. Ini akan memastikan kumpulan data tidak menjadi hambatan saat melatih model Anda. Jika kumpulan data Anda terlalu besar untuk dimasukkan ke dalam memori, Anda juga dapat menggunakan metode ini untuk membuat cache di disk yang berkinerja baik, yang lebih efisien untuk dibaca daripada banyak file kecil.
.prefetch() tumpang tindih prapemrosesan data dan eksekusi model saat pelatihan.
Anda dapat mempelajari lebih lanjut tentang kedua metode tersebut, serta cara menyimpan data ke dalam cache di panduan kinerja data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Buat modelnya
Saatnya membuat jaringan saraf Anda:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Lapisan ditumpuk secara berurutan untuk membangun pengklasifikasi:
- Lapisan pertama adalah lapisan
Embedding. Lapisan ini mengambil ulasan yang dikodekan dengan bilangan bulat dan mencari vektor penyematan untuk setiap indeks kata. Vektor-vektor ini dipelajari sebagai model kereta. Vektor menambahkan dimensi ke larik keluaran. Dimensi yang dihasilkan adalah:(batch, sequence, embedding). Untuk mempelajari lebih lanjut tentang penyematan, lihat tutorial penyematan kata . - Selanjutnya, lapisan
GlobalAveragePooling1Dmengembalikan vektor keluaran dengan panjang tetap untuk setiap contoh dengan merata-ratakan dimensi urutan. Ini memungkinkan model untuk menangani input dengan panjang variabel, dengan cara yang sesederhana mungkin. - Vektor keluaran dengan panjang tetap ini disalurkan melalui lapisan yang terhubung penuh (
Dense) dengan 16 unit tersembunyi. - Lapisan terakhir terhubung erat dengan simpul keluaran tunggal.
Fungsi kerugian dan pengoptimal
Sebuah model membutuhkan fungsi kerugian dan pengoptimal untuk pelatihan. Karena ini adalah masalah klasifikasi biner dan model menghasilkan probabilitas (lapisan unit tunggal dengan aktivasi sigmoid), Anda akan menggunakan fungsi losses.BinaryCrossentropy loss.
Sekarang, konfigurasikan model untuk menggunakan pengoptimal dan fungsi kerugian:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Latih modelnya
Anda akan melatih model dengan meneruskan objek dataset ke metode fit.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Evaluasi modelnya
Mari kita lihat bagaimana kinerja modelnya. Dua nilai akan dikembalikan. Loss (angka yang mewakili kesalahan kami, nilai yang lebih rendah lebih baik), dan akurasi.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Pendekatan yang cukup naif ini mencapai akurasi sekitar 86%.
Buat plot akurasi dan kerugian seiring waktu
model.fit() mengembalikan objek History yang berisi kamus dengan semua yang terjadi selama pelatihan:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Ada empat entri: satu untuk setiap metrik yang dipantau selama pelatihan dan validasi. Anda dapat menggunakan ini untuk merencanakan kerugian pelatihan dan validasi untuk perbandingan, serta akurasi pelatihan dan validasi:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
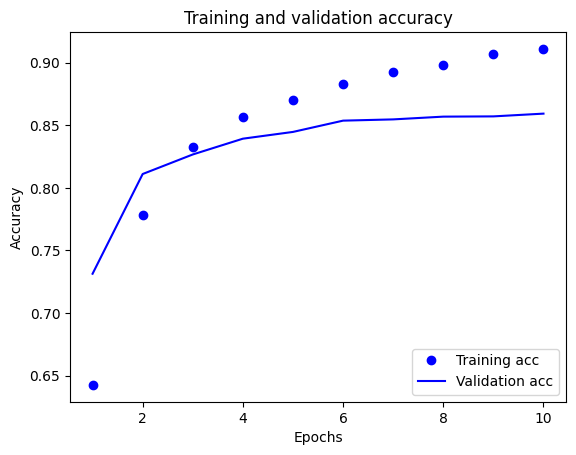
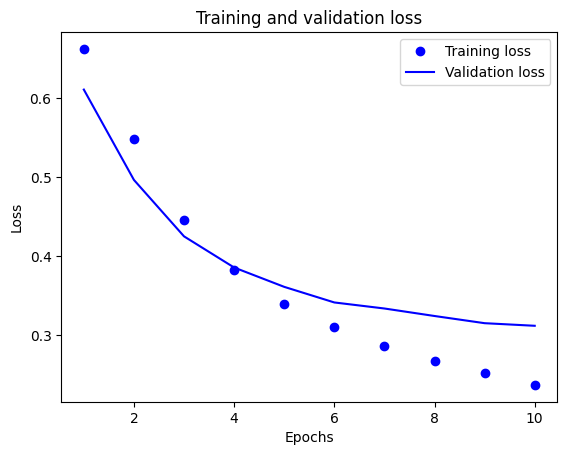
Dalam plot ini, titik-titik mewakili kehilangan dan akurasi pelatihan, dan garis padat adalah kehilangan dan akurasi validasi.
Perhatikan kerugian pelatihan berkurang dengan setiap zaman dan akurasi pelatihan meningkat dengan setiap zaman. Ini diharapkan saat menggunakan optimasi penurunan gradien—ini harus meminimalkan kuantitas yang diinginkan pada setiap iterasi.
Ini tidak berlaku untuk kehilangan validasi dan akurasi—mereka tampaknya mencapai puncaknya sebelum akurasi pelatihan. Ini adalah contoh overfitting: model berperforma lebih baik pada data pelatihan daripada pada data yang belum pernah dilihat sebelumnya. Setelah titik ini, model terlalu mengoptimalkan dan mempelajari representasi khusus untuk data pelatihan yang tidak digeneralisasi untuk data pengujian.
Untuk kasus khusus ini, Anda dapat mencegah overfitting hanya dengan menghentikan pelatihan saat akurasi validasi tidak lagi meningkat. Salah satu cara untuk melakukannya adalah dengan menggunakan panggilan balik tf.keras.callbacks.EarlyStopping .
Ekspor modelnya
Dalam kode di atas, Anda menerapkan layer TextVectorization ke dataset sebelum memasukkan teks ke model. Jika Anda ingin membuat model Anda mampu memproses string mentah (misalnya, untuk menyederhanakan penerapannya), Anda dapat menyertakan lapisan TextVectorization di dalam model Anda. Untuk melakukannya, Anda dapat membuat model baru menggunakan beban yang baru saja Anda latih.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Inferensi pada data baru
Untuk mendapatkan prediksi untuk contoh baru, Anda cukup memanggil model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Menyertakan logika prapemrosesan teks di dalam model Anda memungkinkan Anda mengekspor model untuk produksi yang menyederhanakan penerapan, dan mengurangi potensi kemiringan train/test .
Ada perbedaan kinerja yang perlu diingat ketika memilih tempat untuk menerapkan layer TextVectorization Anda. Menggunakannya di luar model Anda memungkinkan Anda melakukan pemrosesan CPU asinkron dan buffering data Anda saat berlatih di GPU. Jadi, jika Anda melatih model Anda di GPU, Anda mungkin ingin menggunakan opsi ini untuk mendapatkan kinerja terbaik saat mengembangkan model Anda, lalu beralih ke menyertakan lapisan TextVectorization di dalam model Anda saat Anda siap untuk mempersiapkan penerapan .
Kunjungi tutorial ini untuk mempelajari lebih lanjut tentang menyimpan model.
Latihan: klasifikasi multi-kelas pada pertanyaan Stack Overflow
Tutorial ini menunjukkan cara melatih pengklasifikasi biner dari awal pada dataset IMDB. Sebagai latihan, Anda dapat memodifikasi buku catatan ini untuk melatih pengklasifikasi multi-kelas untuk memprediksi tag pertanyaan pemrograman di Stack Overflow .
Kumpulan data telah disiapkan untuk Anda gunakan yang berisi beberapa ribu pertanyaan pemrograman (misalnya, "Bagaimana saya bisa mengurutkan kamus berdasarkan nilai dengan Python?") yang diposting ke Stack Overflow. Masing-masing diberi label dengan tepat satu tag (baik Python, CSharp, JavaScript, atau Java). Tugas Anda adalah mengambil pertanyaan sebagai input, dan memprediksi tag yang sesuai, dalam hal ini, Python.
Set data yang akan Anda gunakan berisi beberapa ribu pertanyaan yang diambil dari set data Stack Overflow publik yang jauh lebih besar di BigQuery , yang berisi lebih dari 17 juta postingan.
Setelah mengunduh kumpulan data, Anda akan menemukannya memiliki struktur direktori yang mirip dengan kumpulan data IMDB yang Anda gunakan sebelumnya:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Untuk menyelesaikan latihan ini, Anda harus memodifikasi buku catatan ini agar berfungsi dengan kumpulan data Stack Overflow dengan melakukan modifikasi berikut:
Di bagian atas notebook Anda, perbarui kode yang mengunduh kumpulan data IMDB dengan kode untuk mengunduh kumpulan data Stack Overflow yang telah disiapkan. Karena kumpulan data Stack Overflow memiliki struktur direktori yang serupa, Anda tidak perlu melakukan banyak modifikasi.
Ubah lapisan terakhir model Anda menjadi
Dense(4), karena sekarang ada empat kelas keluaran.Saat mengkompilasi model, ubah yang hilang menjadi
tf.keras.losses.SparseCategoricalCrossentropy. Ini adalah fungsi kerugian yang benar untuk digunakan untuk masalah klasifikasi multi-kelas, ketika label untuk setiap kelas adalah bilangan bulat (dalam hal ini, mereka dapat berupa 0, 1 , 2 , atau 3 ). Selain itu, ubah metrik menjadimetrics=['accuracy'], karena ini adalah masalah klasifikasi multi-kelas (tf.metrics.BinaryAccuracyhanya digunakan untuk pengklasifikasi biner).Saat merencanakan akurasi dari waktu ke waktu, ubah
binary_accuracydanval_binary_accuracymasing-masing menjadiaccuracydanval_accuracy.Setelah perubahan ini selesai, Anda akan dapat melatih pengklasifikasi multi-kelas.
Belajar lebih banyak
Tutorial ini memperkenalkan klasifikasi teks dari awal. Untuk mempelajari lebih lanjut tentang alur kerja klasifikasi teks secara umum, lihat Panduan klasifikasi teks dari Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.