
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
API tf.data memungkinkan Anda membangun saluran input yang kompleks dari bagian sederhana yang dapat digunakan kembali. Misalnya, saluran untuk model gambar mungkin mengumpulkan data dari file dalam sistem file terdistribusi, menerapkan gangguan acak ke setiap gambar, dan menggabungkan gambar yang dipilih secara acak ke dalam kumpulan untuk pelatihan. Pipeline untuk model teks mungkin melibatkan ekstraksi simbol dari data teks mentah, mengonversinya menjadi penyematan pengidentifikasi dengan tabel pencarian, dan mengelompokkan urutan dengan panjang yang berbeda. API tf.data memungkinkan untuk menangani data dalam jumlah besar, membaca dari format data yang berbeda, dan melakukan transformasi yang kompleks.
API tf.data memperkenalkan abstraksi tf.data.Dataset yang mewakili urutan elemen, di mana setiap elemen terdiri dari satu atau lebih komponen. Misalnya, dalam saluran gambar, sebuah elemen mungkin berupa contoh pelatihan tunggal, dengan sepasang komponen tensor yang mewakili gambar dan labelnya.
Ada dua cara berbeda untuk membuat kumpulan data:
Sumber data membangun
Datasetdari data yang disimpan dalam memori atau dalam satu atau lebih file.Transformasi data membuat kumpulan data dari satu atau beberapa objek
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
mekanika dasar
Untuk membuat saluran input, Anda harus memulai dengan sumber data . Misalnya, untuk membuat Dataset dari data di memori, Anda dapat menggunakan tf.data.Dataset.from_tensors() atau tf.data.Dataset.from_tensor_slices() . Atau, jika data input Anda disimpan dalam file dalam format TFRecord yang disarankan, Anda dapat menggunakan tf.data.TFRecordDataset() .
Setelah Anda memiliki objek Dataset , Anda dapat mengubahnya menjadi Dataset baru dengan panggilan metode berantai pada objek tf.data.Dataset . Misalnya, Anda dapat menerapkan transformasi per elemen seperti Dataset.map() , dan transformasi multi-elemen seperti Dataset.batch() . Lihat dokumentasi untuk tf.data.Dataset untuk daftar lengkap transformasi.
Objek Dataset adalah Python yang dapat diubah. Ini memungkinkan untuk mengkonsumsi elemen-elemennya menggunakan for loop:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Atau dengan secara eksplisit membuat iterator Python menggunakan iter dan menggunakan elemennya menggunakan next :
it = iter(dataset)
print(next(it).numpy())
8
Atau, elemen dataset dapat dikonsumsi menggunakan transformasi reduce , yang mereduksi semua elemen untuk menghasilkan satu hasil. Contoh berikut mengilustrasikan cara menggunakan transformasi reduce untuk menghitung jumlah kumpulan data bilangan bulat.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Struktur kumpulan data
Dataset menghasilkan urutan elemen , di mana setiap elemen adalah struktur komponen yang sama (bersarang). Komponen individu dari struktur dapat berupa jenis apa pun yang dapat diwakili oleh tf.TypeSpec , termasuk tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray , atau tf.data.Dataset .
Konstruksi Python yang dapat digunakan untuk mengekspresikan struktur elemen (bersarang) termasuk tuple , dict , NamedTuple , dan OrderedDict . Secara khusus, list bukanlah konstruksi yang valid untuk mengekspresikan struktur elemen kumpulan data. Ini karena pengguna tf.data awal sangat merasakan masukan list (misalnya diteruskan ke tf.data.Dataset.from_tensors ) secara otomatis dikemas sebagai tensor dan keluaran list (misalnya mengembalikan nilai fungsi yang ditentukan pengguna) dipaksa menjadi tuple . Akibatnya, jika Anda ingin input list diperlakukan sebagai struktur, Anda perlu mengubahnya menjadi tuple dan jika Anda ingin output list menjadi satu komponen, maka Anda perlu mengemasnya secara eksplisit menggunakan tf.stack .
Properti Dataset.element_spec memungkinkan Anda untuk memeriksa jenis setiap komponen elemen. Properti mengembalikan struktur bersarang dari objek tf.TypeSpec , mencocokkan struktur elemen, yang mungkin berupa komponen tunggal, tupel komponen, atau tupel komponen bersarang. Sebagai contoh:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Transformasi Dataset mendukung kumpulan data dari struktur apa pun. Saat menggunakan Dataset.map() , dan Dataset.filter() , yang menerapkan fungsi ke setiap elemen, struktur elemen menentukan argumen fungsi:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Membaca data masukan
Mengkonsumsi array NumPy
Lihat Memuat array NumPy untuk contoh lainnya.
Jika semua data masukan Anda muat di memori, cara paling sederhana untuk membuat Dataset dari data tersebut adalah dengan mengonversinya menjadi objek tf.Tensor dan menggunakan Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Mengkonsumsi generator Python
Sumber data umum lainnya yang dapat dengan mudah diserap sebagai tf.data.Dataset adalah generator python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Konstruktor Dataset.from_generator mengonversi generator python menjadi tf.data.Dataset yang berfungsi penuh.
Konstruktor mengambil callable sebagai input, bukan iterator. Hal ini memungkinkan untuk me-restart generator ketika mencapai akhir. Dibutuhkan argumen args opsional, yang diteruskan sebagai argumen yang dapat dipanggil.
Argumen output_types diperlukan karena tf.data membangun tf.Graph secara internal, dan tepi grafik memerlukan tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
Argumen output_shapes tidak diperlukan tetapi sangat disarankan karena banyak operasi TensorFlow tidak mendukung tensor dengan peringkat yang tidak diketahui. Jika panjang sumbu tertentu tidak diketahui atau variabel, atur sebagai None di output_shapes .
Penting juga untuk dicatat bahwa output_shapes dan output_types mengikuti aturan bersarang yang sama seperti metode kumpulan data lainnya.
Berikut adalah contoh generator yang menunjukkan kedua aspek, ia mengembalikan tupel array, di mana array kedua adalah vektor dengan panjang yang tidak diketahui.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
Output pertama adalah int32 yang kedua adalah float32 .
Item pertama adalah skalar, bentuk () , dan yang kedua adalah vektor yang panjangnya tidak diketahui, bentuk (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Sekarang dapat digunakan seperti tf.data.Dataset biasa. Perhatikan bahwa saat mengelompokkan kumpulan data dengan bentuk variabel, Anda perlu menggunakan Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Untuk contoh yang lebih realistis, coba bungkus preprocessing.image.ImageDataGenerator sebagai tf.data.Dataset .
Download dulu datanya :
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Mengkonsumsi data TFRecord
Lihat Memuat TFRecords untuk contoh ujung ke ujung.
tf.data API mendukung berbagai format file sehingga Anda dapat memproses kumpulan data besar yang tidak muat di memori. Misalnya, format file TFRecord adalah format biner berorientasi rekaman sederhana yang digunakan banyak aplikasi TensorFlow untuk data pelatihan. Kelas tf.data.TFRecordDataset memungkinkan Anda untuk mengalirkan konten dari satu atau beberapa file TFRecord sebagai bagian dari saluran input.
Berikut adalah contoh menggunakan file tes dari French Street Name Signs (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
Argumen filenames ke penginisialisasi TFRecordDataset dapat berupa string, daftar string, atau tf.Tensor string. Oleh karena itu, jika Anda memiliki dua kumpulan file untuk tujuan pelatihan dan validasi, Anda dapat membuat metode pabrik yang menghasilkan kumpulan data, dengan menggunakan nama file sebagai argumen input:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Banyak proyek TensorFlow menggunakan catatan tf.train.Example serial dalam file TFRecord mereka. Ini perlu didekodekan sebelum dapat diperiksa:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Mengkonsumsi data teks
Lihat Memuat Teks untuk contoh ujung ke ujung.
Banyak dataset didistribusikan sebagai satu atau lebih file teks. tf.data.TextLineDataset menyediakan cara mudah untuk mengekstrak baris dari satu atau lebih file teks. Diberikan satu atau lebih nama file, TextLineDataset akan menghasilkan satu elemen bernilai string per baris file tersebut.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Berikut adalah beberapa baris pertama dari file pertama:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Untuk mengganti baris antar file gunakan Dataset.interleave . Ini membuatnya lebih mudah untuk mengacak file bersama-sama. Berikut adalah baris pertama, kedua dan ketiga dari setiap terjemahan:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
Secara default, TextLineDataset menghasilkan setiap baris dari setiap file, yang mungkin tidak diinginkan, misalnya, jika file dimulai dengan baris header, atau berisi komentar. Baris ini dapat dihapus menggunakan Dataset.skip() atau Dataset.filter() . Di sini, Anda melewati baris pertama, lalu menyaring untuk menemukan hanya yang selamat.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Mengkonsumsi data CSV
Lihat Memuat File CSV , dan Memuat Pandas DataFrames untuk contoh lainnya.
Format file CSV adalah format populer untuk menyimpan data tabular dalam teks biasa.
Sebagai contoh:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Jika data Anda muat di memori, metode Dataset.from_tensor_slices yang sama berfungsi di kamus, memungkinkan data ini diimpor dengan mudah:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Pendekatan yang lebih terukur adalah memuat dari disk seperlunya.
Modul tf.data menyediakan metode untuk mengekstrak catatan dari satu atau lebih file CSV yang sesuai dengan RFC 4180 .
Fungsi experimental.make_csv_dataset adalah antarmuka tingkat tinggi untuk membaca kumpulan file csv. Ini mendukung inferensi tipe kolom dan banyak fitur lainnya, seperti batching dan shuffle, untuk mempermudah penggunaan.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Anda dapat menggunakan argumen select_columns jika Anda hanya membutuhkan subset kolom.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
Ada juga kelas experimental.CsvDataset tingkat rendah yang menyediakan kontrol berbutir lebih halus. Itu tidak mendukung inferensi tipe kolom. Sebaliknya Anda harus menentukan jenis setiap kolom.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Jika beberapa kolom kosong, antarmuka tingkat rendah ini memungkinkan Anda memberikan nilai default, bukan jenis kolom.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
Secara default, CsvDataset menghasilkan setiap kolom dari setiap baris file, yang mungkin tidak diinginkan, misalnya jika file dimulai dengan baris header yang harus diabaikan, atau jika beberapa kolom tidak diperlukan dalam input. Baris dan bidang ini dapat dihapus dengan argumen header dan select_cols masing-masing.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Mengkonsumsi set file
Ada banyak kumpulan data yang didistribusikan sebagai kumpulan file, di mana setiap file adalah contohnya.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
Direktori root berisi direktori untuk setiap kelas:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
File-file di setiap direktori kelas adalah contohnya:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Baca data menggunakan fungsi tf.io.read_file dan ekstrak label dari jalur, kembalikan pasangan (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Mengelompokkan elemen kumpulan data
Pengelompokan sederhana
Bentuk paling sederhana dari kumpulan tumpukan n elemen berurutan dari kumpulan data menjadi satu elemen. Dataset.batch() melakukan hal ini, dengan batasan yang sama seperti operator tf.stack() , diterapkan ke setiap komponen elemen: yaitu untuk setiap komponen i , semua elemen harus memiliki tensor dengan bentuk yang sama persis.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Sementara tf.data mencoba menyebarkan informasi bentuk, pengaturan default Dataset.batch menghasilkan ukuran kumpulan yang tidak diketahui karena kumpulan terakhir mungkin tidak penuh. Perhatikan None s dalam bentuk:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Gunakan argumen drop_remainder untuk mengabaikan kumpulan terakhir itu, dan dapatkan propagasi bentuk penuh:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Batching tensor dengan padding
Resep di atas berfungsi untuk tensor yang semuanya memiliki ukuran yang sama. Namun, banyak model (misalnya model urutan) bekerja dengan data input yang dapat memiliki ukuran yang bervariasi (misalnya urutan dengan panjang yang berbeda). Untuk menangani kasus ini, transformasi Dataset.padded_batch memungkinkan Anda untuk mengelompokkan tensor dengan bentuk yang berbeda dengan menentukan satu atau beberapa dimensi tempat mereka dapat diisi.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
Transformasi Dataset.padded_batch memungkinkan Anda untuk mengatur padding yang berbeda untuk setiap dimensi setiap komponen, dan mungkin panjang variabel (ditandai dengan None dalam contoh di atas) atau panjang konstan. Dimungkinkan juga untuk mengganti nilai padding, yang defaultnya adalah 0.
Alur kerja pelatihan
Memproses beberapa zaman
tf.data API menawarkan dua cara utama untuk memproses beberapa epoch dari data yang sama.
Cara paling sederhana untuk mengulangi kumpulan data dalam beberapa zaman adalah dengan menggunakan transformasi Dataset.repeat() . Pertama, buat kumpulan data titanic data:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
Menerapkan transformasi Dataset.repeat() tanpa argumen akan mengulangi input tanpa batas.
Transformasi Dataset.repeat menggabungkan argumennya tanpa menandakan akhir dari satu epoch dan awal dari epoch berikutnya. Karena itu, Dataset.batch yang diterapkan setelah Dataset.repeat akan menghasilkan kumpulan yang melintasi batas zaman:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
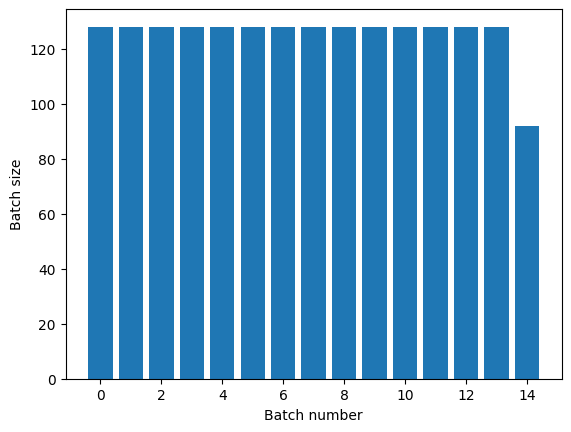
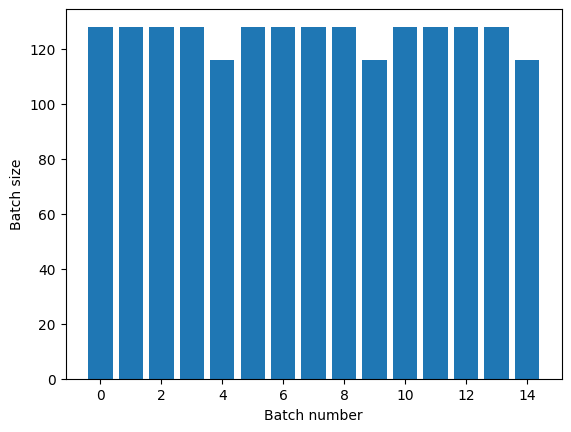
Jika Anda membutuhkan pemisahan epoch yang jelas, letakkan Dataset.batch sebelum pengulangan:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
Jika Anda ingin melakukan perhitungan khusus (misalnya untuk mengumpulkan statistik) di akhir setiap epoch, maka paling mudah untuk memulai ulang iterasi kumpulan data di setiap epoch:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Mengacak data input secara acak
Dataset.shuffle() mempertahankan buffer berukuran tetap dan memilih elemen berikutnya secara acak dari buffer tersebut.
Tambahkan indeks ke dataset sehingga Anda dapat melihat efeknya:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Karena buffer_size adalah 100, dan ukuran batch adalah 20, batch pertama tidak berisi elemen dengan indeks lebih dari 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Seperti halnya Dataset.batch , urutan relatif terhadap Dataset.repeat penting.
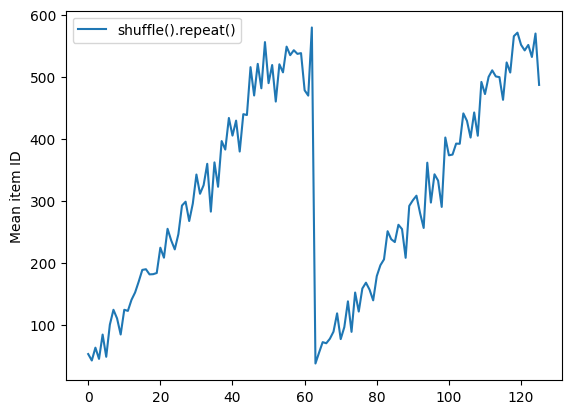
Dataset.shuffle tidak menandakan akhir dari sebuah epoch sampai buffer shuffle kosong. Jadi shuffle yang ditempatkan sebelum pengulangan akan menampilkan setiap elemen dari satu zaman sebelum pindah ke yang berikutnya:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
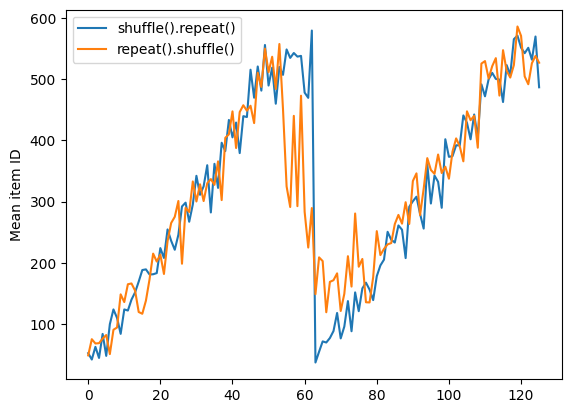
Tetapi pengulangan sebelum shuffle mencampurkan batas-batas zaman bersama-sama:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
Data pra-pemrosesan
Dataset.map(f) menghasilkan kumpulan data baru dengan menerapkan fungsi f yang diberikan ke setiap elemen kumpulan data masukan. Ini didasarkan pada fungsi map() yang umumnya diterapkan pada daftar (dan struktur lainnya) dalam bahasa pemrograman fungsional. Fungsi f mengambil objek tf.Tensor yang mewakili satu elemen dalam input, dan mengembalikan objek tf.Tensor yang akan mewakili satu elemen dalam kumpulan data baru. Implementasinya menggunakan operasi TensorFlow standar untuk mengubah satu elemen menjadi elemen lainnya.
Bagian ini membahas contoh umum tentang cara menggunakan Dataset.map() .
Mendekode data gambar dan mengubah ukurannya
Saat melatih jaringan saraf pada data gambar dunia nyata, sering kali diperlukan untuk mengonversi gambar dengan ukuran berbeda ke ukuran umum, sehingga dapat dikelompokkan menjadi ukuran tetap.
Bangun kembali kumpulan data nama file bunga:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Tulis fungsi yang memanipulasi elemen dataset.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Uji apakah itu berhasil.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Petakan di atas kumpulan data.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Menerapkan logika Python sewenang-wenang
Untuk alasan kinerja, gunakan operasi TensorFlow untuk pra-pemrosesan data Anda jika memungkinkan. Namun, terkadang berguna untuk memanggil pustaka Python eksternal saat mem-parsing data input Anda. Anda dapat menggunakan operasi tf.py_function() Dataset.map() dalam transformasi Dataset.map().
Misalnya, jika Anda ingin menerapkan rotasi acak, modul tf.image hanya memiliki tf.image.rot90 , yang tidak terlalu berguna untuk pembesaran gambar.
Untuk mendemonstrasikan tf.py_function , coba gunakan fungsi scipy.ndimage.rotate sebagai gantinya:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Untuk menggunakan fungsi ini dengan Dataset.map , peringatan yang sama berlaku seperti dengan Dataset.from_generator , Anda perlu menjelaskan bentuk dan tipe kembalian saat Anda menerapkan fungsi:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Parsing tf.Example pesan buffering protokol
Banyak jalur pipa masukan mengekstrak pesan buffering protokol tf.train.Example dari format TFRecord. Setiap record tf.train.Example berisi satu atau beberapa "fitur", dan jalur input biasanya mengubah fitur ini menjadi tensor.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Anda dapat bekerja dengan tf.train.Example protos di luar tf.data.Dataset untuk memahami data:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Jendela deret waktu
Untuk contoh deret waktu ujung ke ujung, lihat: Peramalan deret waktu .
Data deret waktu sering diatur dengan sumbu waktu yang utuh.
Gunakan Dataset.range sederhana untuk menunjukkan:
range_ds = tf.data.Dataset.range(100000)
Biasanya, model yang didasarkan pada jenis data ini akan menginginkan irisan waktu yang berdekatan.
Pendekatan paling sederhana adalah dengan mengelompokkan data:
Menggunakan batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Atau untuk membuat prediksi padat selangkah ke depan, Anda dapat menggeser fitur dan label satu langkah relatif satu sama lain:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Untuk memprediksi seluruh jendela alih-alih offset tetap, Anda dapat membagi kumpulan menjadi dua bagian:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Untuk memungkinkan beberapa tumpang tindih antara fitur satu batch dan label yang lain, gunakan Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Menggunakan window
Saat menggunakan Dataset.batch berfungsi, ada situasi di mana Anda mungkin memerlukan kontrol yang lebih baik. Metode Dataset.window memberi Anda kontrol penuh, tetapi memerlukan perhatian: metode ini mengembalikan Dataset of Datasets . Lihat Struktur kumpulan data untuk detailnya.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
Metode Dataset.flat_map dapat mengambil kumpulan data dari kumpulan data dan meratakannya menjadi satu kumpulan data:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
Di hampir semua kasus, Anda ingin .batch dataset terlebih dahulu:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Sekarang, Anda dapat melihat bahwa argumen shift mengontrol seberapa banyak setiap jendela berpindah.
Menyatukan ini, Anda dapat menulis fungsi ini:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Maka mudah untuk mengekstrak label, seperti sebelumnya:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Pengambilan sampel ulang
Saat bekerja dengan kumpulan data yang sangat tidak seimbang kelasnya, Anda mungkin ingin membuat sampel ulang kumpulan data tersebut. tf.data menyediakan dua metode untuk melakukan ini. Dataset penipuan kartu kredit adalah contoh yang baik dari masalah semacam ini.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Sekarang, periksa distribusi kelas, sangat miring:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Pendekatan umum untuk pelatihan dengan set data yang tidak seimbang adalah dengan menyeimbangkannya. tf.data menyertakan beberapa metode yang mengaktifkan alur kerja ini:
Pengambilan sampel kumpulan data
Salah satu pendekatan untuk resampling dataset adalah dengan menggunakan sample_from_datasets . Ini lebih berlaku bila Anda memiliki data.Dataset terpisah untuk setiap kelas.
Di sini, cukup gunakan filter untuk menghasilkannya dari data penipuan kartu kredit:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Untuk menggunakan tf.data.Dataset.sample_from_datasets , lewati kumpulan data, dan bobot untuk masing-masing:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Sekarang dataset menghasilkan contoh dari setiap kelas dengan probabilitas 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Pengambilan sampel ulang penolakan
Satu masalah dengan pendekatan Dataset.sample_from_datasets di atas adalah diperlukannya tf.data.Dataset terpisah per kelas. Anda dapat menggunakan Dataset.filter untuk membuat kedua kumpulan data tersebut, tetapi hal itu mengakibatkan semua data dimuat dua kali.
Metode data.Dataset.rejection_resample dapat diterapkan ke kumpulan data untuk menyeimbangkannya kembali, sementara hanya memuatnya sekali. Elemen akan dikeluarkan dari dataset untuk mencapai keseimbangan.
data.Dataset.rejection_resample mengambil argumen class_func . class_func ini diterapkan ke setiap elemen dataset, dan digunakan untuk menentukan kelas mana yang menjadi milik contoh untuk tujuan penyeimbangan.
Tujuannya di sini adalah untuk menyeimbangkan distribusi label, dan elemen creditcard_ds sudah (features, label) berpasangan. Jadi class_func hanya perlu mengembalikan label itu:
def class_func(features, label):
return label
Metode resampling berkaitan dengan contoh individual, jadi dalam hal ini Anda harus unbatch kumpulan data sebelum menerapkan metode itu.
Metode ini membutuhkan distribusi target, dan secara opsional estimasi distribusi awal sebagai input.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
Metode rejection_resample mengembalikan (class, example) pasangan di mana class adalah output dari class_func . Dalam hal ini, example sudah menjadi pasangan (feature, label) , jadi gunakan map untuk melepaskan salinan tambahan dari label:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Sekarang dataset menghasilkan contoh dari setiap kelas dengan probabilitas 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Pemeriksaan Iterator
Tensorflow mendukung pengambilan pos pemeriksaan sehingga saat proses pelatihan Anda dimulai ulang, ia dapat memulihkan pos pemeriksaan terbaru untuk memulihkan sebagian besar kemajuannya. Selain memeriksa variabel model, Anda juga dapat memeriksa kemajuan iterator kumpulan data. Ini bisa berguna jika Anda memiliki kumpulan data yang besar dan tidak ingin memulai kumpulan data dari awal setiap kali restart. Namun perhatikan bahwa pos pemeriksaan iterator mungkin besar, karena transformasi seperti shuffle dan prefetch memerlukan elemen buffering di dalam iterator.
Untuk memasukkan iterator Anda ke dalam checkpoint, teruskan iterator ke konstruktor tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Menggunakan tf.data dengan tf.keras
API tf.keras menyederhanakan banyak aspek dalam membuat dan menjalankan model pembelajaran mesin. .fit() dan .evaluate() dan .predict() nya mendukung kumpulan data sebagai input. Berikut adalah set data cepat dan pengaturan model:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Melewati kumpulan data pasangan (feature, label) adalah semua yang diperlukan untuk Model.fit dan Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Jika Anda meneruskan kumpulan data tak terbatas, misalnya dengan memanggil Dataset.repeat() , Anda hanya perlu meneruskan argumen steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Untuk evaluasi Anda dapat melewati sejumlah langkah evaluasi:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
Untuk kumpulan data yang panjang, tetapkan jumlah langkah untuk dievaluasi:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Label tidak diperlukan saat memanggil Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Tetapi label akan diabaikan jika Anda meneruskan kumpulan data yang berisi label tersebut:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)